Microsoft a introduit rStar-Math, une continuation et un perfectionnement de son précédent framework rStar, pour repousser les limites des petits modèles de langage (SLM) dans le raisonnement mathématique.
Conçu pour rivaliser avec des systèmes plus grands tels que o1-preview d’OpenAI, rStar-Math atteint des références remarquables en matière de résolution de problèmes tout en démontrant comment les modèles compacts peuvent fonctionner à des niveaux compétitifs. Ce développement montre un changement dans les priorités de l’IA, passant de la mise à l’échelle à l’optimisation des performances pour des tâches spécifiques.
Passer de rStar à rStar-Math
Le rStar Le cadre de travail de l’été dernier a jeté les bases de l’amélioration du raisonnement GDT grâce au Monte Carlo Tree Search (MCTS), un algorithme qui affine les solutions en simulant et en validant plusieurs chemins.
rStar a démontré que des modèles plus petits pouvaient gérer des tâches complexes, mais son application restait générale. rStar-Math s’appuie sur cette base avec des innovations ciblées adaptées au raisonnement mathématique.
Le succès de rStar-Math réside dans sa méthodologie de chaîne de pensée (CoT) augmentée par le code, dans laquelle le modèle produit des solutions dans les deux domaines. langage naturel et code Python exécutable.
Cette structure à double sortie garantit que les étapes de raisonnement intermédiaires sont vérifiables, réduisant ainsi les erreurs et maintenant la cohérence logique. Les chercheurs ont souligné l’importance de cette approche, en déclarant: « La cohérence mutuelle reflète la pratique humaine courante en l’absence de supervision, où l’accord entre pairs sur les réponses dérivées suggère une plus grande probabilité d’exactitude. »
Connexe : Le modèle chinois DeepSeek R1-Lite-Preview cible la avance d’OpenAI en matière de raisonnement automatisé
En plus de CoT, rStar-Math introduit un modèle de préférence de processus (PPM), qui évalue et classe les étapes intermédiaires en fonction de la qualité. Contrairement aux systèmes de récompense traditionnels qui s’appuient souvent sur des données bruitées, le PPM donne la priorité à la cohérence logique et à l’exactitude, améliorant ainsi la fiabilité du modèle :
« Le PPM exploite le fait que. , bien que les valeurs Q ne soient toujours pas assez précises pour évaluer chaque étape de raisonnement malgré l’utilisation de déploiements étendus de MCTS, les valeurs Q peuvent distinguer de manière fiable les étapes positives (correctes) des étapes négatives (non pertinentes/incorrectes). ceux.
Ainsi, la méthode d’entraînement construit des paires de préférences pour chaque étape en fonction des valeurs Q et utilise une perte de classement par paire pour optimiser la prédiction du score de PPM pour chaque étape de raisonnement, obtenant ainsi un étiquetage fiable. Cette approche évite les méthodes conventionnelles qui utilisent directement les valeurs Q comme étiquettes de récompense, qui sont intrinsèquement bruyantes et imprécises dans l’attribution des récompenses par étapes.”
Enfin, une recette d’auto-évolution en quatre tours qui construit progressivement à la fois une frontière modèle politique et PPM à partir de zéro.
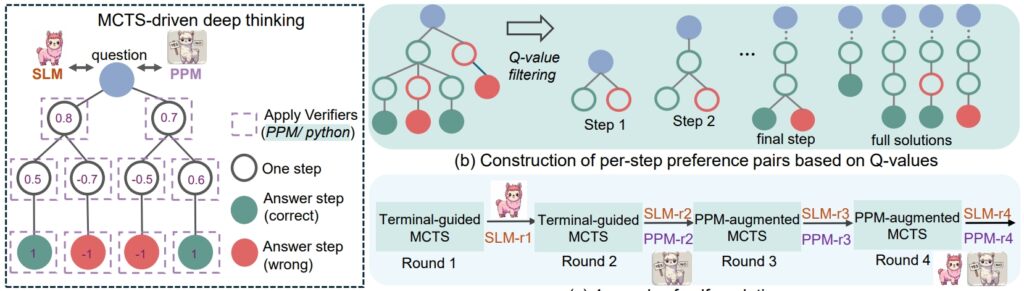 Procédure de raisonnement rSTar-Math (Source: document de recherche)
Procédure de raisonnement rSTar-Math (Source: document de recherche)
Des performances qui défient les modèles plus grands
rStar-Math établit de nouvelles normes en matière de tests de raisonnement mathématique, obtenant des résultats qui rivalisent, et dans certains cas surpassent, ceux des systèmes d’IA plus grands
Sur l’ensemble de données GSM8K. , un test de raisonnement mathématique, la précision d’un modèle de 7 milliards de paramètres s’est améliorée de 12,51 % à 63,91 % après l’intégration de rStar-Math dans le
Les résultats de l’ensemble de données MATH étaient tout aussi impressionnants, rStar-Math atteignant un taux de précision de 90 %, surpassant ainsi l’o1-preview d’OpenAI.
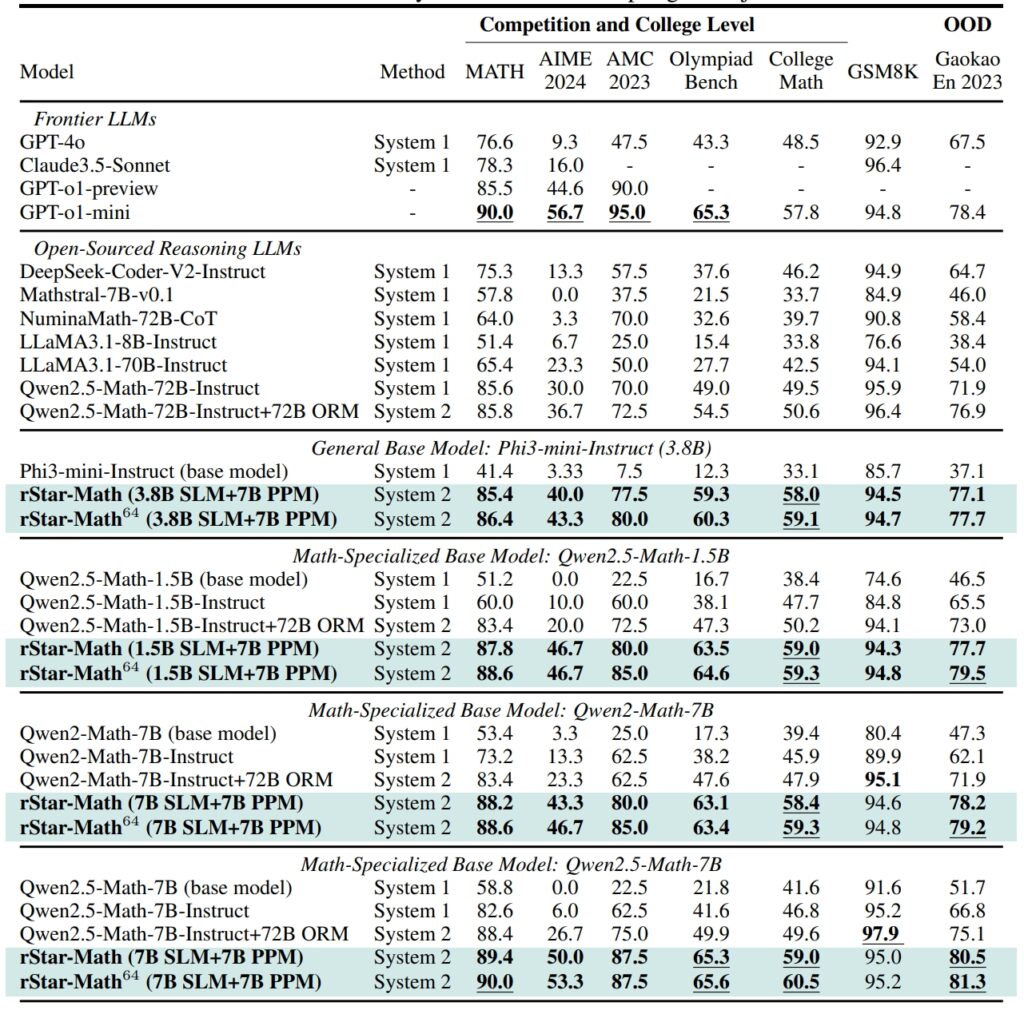 Performance de rStar-Math et d’autres LLM frontières sur les sujets les plus difficiles repères mathématiques (Source : document de recherche)
Performance de rStar-Math et d’autres LLM frontières sur les sujets les plus difficiles repères mathématiques (Source : document de recherche)
Ces réalisations mettent en évidence la capacité du cadre à permettre aux SLM de gérer des tâches auparavant dominées par de grands modèles gourmands en ressources. En mettant l’accent sur la cohérence logique et les étapes intermédiaires vérifiables, rStar-Math répond à l’un des défis les plus persistants de l’IA : garantir un raisonnement fiable sur des espaces de problèmes complexes.
Les innovations techniques qui stimulent rStar-Math
L’évolution de rStar vers rStar-Math introduit plusieurs avancées clés. L’intégration de MCTS reste au cœur du cadre, permettant au modèle d’explorer diverses voies de raisonnement et de prioriser les plus prometteuses.
L’ajout du raisonnement CoT, axé sur la vérification du code, garantit que les résultats sont à la fois interprétables et précis.
Connexe : QwQ-32B d’Alibaba-Preview rejoint la bataille de raisonnement des modèles d’IA avec OpenAI
Le processus de formation auto-évolutif de rStar-Math est peut-être le plus transformateur. Au cours de quatre cycles itératifs, le cadre affine son modèle politique et son PPM, en intégrant des données de raisonnement de meilleure qualité à chaque étape.
Cette approche itérative permet au modèle d’améliorer continuellement ses performances, obtenant des résultats de pointe sans dépendre de la distillation de modèles plus grands.
Comparaison de rStar-Math to OpenAI’s o1
Alors que Microsoft se concentre sur l’optimisation de modèles plus petits, OpenAI continue de donner la priorité à la mise à l’échelle de ses systèmes.
Le mode o1 Pro, introduit en décembre 2024 dans le cadre du plan ChatGPT Pro, offre des capacités de raisonnement avancées adaptées aux applications à enjeux élevés telles que le codage et la recherche scientifique. OpenAI a rapporté que le mode o1 Pro a atteint un taux de précision de 86 % sur AIME et un taux de réussite de 90 % dans les tests de codage comme Codeforces.
rStar-Math représente un changement dans l’innovation en matière d’IA, remettant en question l’accent mis par l’industrie sur des modèles plus grands. comme principal moyen de parvenir à un raisonnement avancé. En améliorant les SLM avec des optimisations spécifiques à un domaine, Microsoft propose une alternative durable qui réduit les coûts de calcul et l’impact environnemental.
Connexe : Alignement délibératif : stratégie de sécurité d’OpenAI pour ses modèles de pensée o1 et o3
Le succès du cadre en matière de raisonnement mathématique ouvre les portes à des applications plus larges, allant de l’éducation à la recherche scientifique.
Les chercheurs prévoient de publier le code et les données de rStar-Math sur GitHub, ouvrant ainsi la voie à une collaboration et à un développement ultérieurs. Cette transparence reflète l’approche de Microsoft visant à rendre les outils d’IA hautes performances accessibles à un public plus large, y compris les établissements universitaires et les organisations de taille moyenne.
Connexe : SemiAnalysis : non, la mise à l’échelle de l’IA n’est pas possible. Cela ne ralentit pas
Alors que la concurrence entre Microsoft et OpenAI s’intensifie, les avancées introduites par rStar-Math mettent en évidence le potentiel des modèles plus petits pour défier la domination des systèmes plus grands. En donnant la priorité à l’efficacité et à la précision, rStar-Math établit une nouvelle référence pour ce que les systèmes d’IA compacts peuvent réaliser.