Des chercheurs de Sakana AI, une startup d’IA basée à Tokyo, ont introduit un nouveau système d’optimisation de la mémoire qui améliore l’efficacité des modèles basés sur Transformer. y compris les grands modèles de langage (LLM).
La méthode, appelée Modèles de mémoire d’attention neuronale (NAMM) disponible via le code de formation complet sur GitHub, réduit l’utilisation de la mémoire jusqu’à 75 % tout en améliorant les performances globales. En se concentrant sur les jetons essentiels et en supprimant les informations redondantes, les NAMM relèvent l’un des défis les plus gourmands en ressources de l’IA moderne : la gestion de longues fenêtres contextuelles.
Les modèles Transformer, l’épine dorsale des LLM, s’appuient sur des « fenêtres contextuelles ». pour traiter les données d’entrée. Ces fenêtres contextuelles stockent des « paires clé-valeur » (cache KV) pour chaque jeton de la séquence d’entrée.
À mesure que la longueur de la fenêtre augmente (atteignant désormais des centaines de milliers de jetons), le le coût de calcul monte en flèche. Les solutions antérieures tentaient de réduire ce coût grâce à un élagage manuel des jetons ou à des stratégies heuristiques, mais dégradaient souvent les performances. Les NAMM, cependant, utilisent des réseaux de neurones formés grâce à l’optimisation évolutive pour automatiser et affiner le processus de gestion de la mémoire.
Optimisation de la mémoire avec les NAMM
Les NAMM analysent les valeurs d’attention. généré par Transformers pour déterminer l’importance du jeton. Ils traitent ces valeurs en spectrogrammes (représentations basées sur la fréquence couramment utilisées dans le traitement de l’audio et du signal) pour compresser et extraire les caractéristiques clés des modèles d’attention.
Ces informations sont ensuite transmises via un réseau neuronal léger qui attribue un score à chaque jeton, décidant s’il doit être conservé ou supprimé.
Sakana AI met en évidence la manière dont les algorithmes évolutifs pilotent les NAMM. succès. Contrairement aux méthodes traditionnelles basées sur le gradient, qui sont incompatibles avec les décisions binaires telles que « se souvenir » ou « oublier », l’optimisation évolutive teste et affine de manière itérative les stratégies de mémoire pour maximiser les performances en aval.
« L’évolution surmonte intrinsèquement la non-différentiabilité. de nos opérations de gestion de la mémoire, qui impliquent des résultats binaires « se souvenir » ou « oublier », expliquent les chercheurs.
Des résultats prouvés selon des critères de référence
À valider le performances et l’efficacité des modèles de mémoire d’attention neuronale (NAMM), Sakana AI a mené des tests approfondis sur plusieurs tests de référence de pointe conçus pour évaluer le traitement de contexte long et les capacités multitâches. Les résultats ont souligné la capacité des NAMM à améliorer considérablement les performances tout en réduisant les besoins en mémoire. , prouvant leur efficacité dans divers cadres d’évaluation.
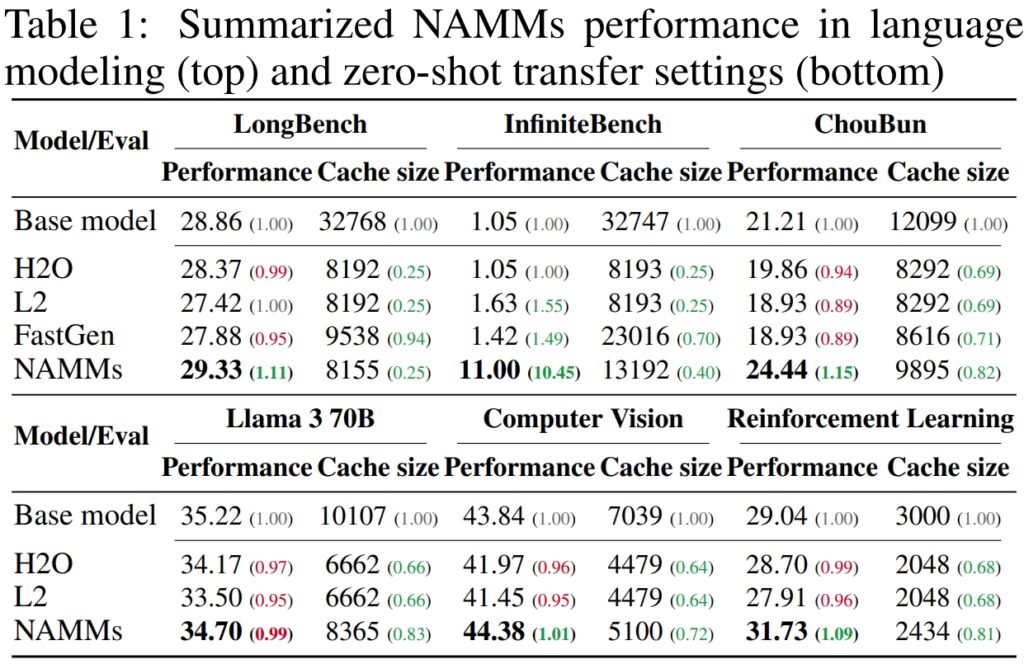
Sur LongBench, un benchmark spécifiquement créé pour mesurer les performances des modèles sur des tâches à contexte long, les NAMM ont obtenu une amélioration de 11 % en termes de précision par rapport au modèle de référence à contexte complet. Cette amélioration a été obtenue tout en réduisant l’utilisation de la mémoire de 75 %, mettant en évidence l’efficacité de la méthode dans la gestion du cache clé-valeur (KV).
En éliminant intelligemment les jetons les moins pertinents, les NAMM ont permis au modèle de se concentrer sur le contexte critique sans sacrifier les résultats, ce qui le rend idéal pour les scénarios nécessitant des entrées étendues, telles que l’analyse de documents ou la réponse à des questions longues.
En éliminant intelligemment les jetons les moins pertinents, les NAMM ont permis au modèle de se concentrer sur le contexte critique sans sacrifier les résultats, ce qui le rend idéal pour les scénarios nécessitant des entrées étendues, telles que l’analyse de documents ou la réponse à des questions détaillées. p>
Pour InfiniteBench, un benchmark qui pousse les modèles à leurs limites avec des séquences-certaines dépassant 200 000 jetons-les NAMM ont démontré leur capacité à évoluer efficacement.
Alors que les modèles de base rencontraient des difficultés avec les exigences de calcul liées à des entrées aussi longues, les NAMM ont obtenu une amélioration spectaculaire des performances, augmentant la précision de 1,05 % à 11,00 %.
Ce résultat est particulièrement remarquable car il met en valeur la capacité des NAMM à gérer des contextes ultra-longs, une capacité de plus en plus essentielle pour des applications telles que le traitement de la littérature scientifique, des documents juridiques ou de grands référentiels de code où la taille des entrées de jetons est immense.
Sur le propre benchmark ChouBun de Sakana AI, qui évalue le raisonnement à contexte long pour les tâches en langue japonaise, Les NAMM ont généré une amélioration de 15 % par rapport à la référence. ChouBun comble une lacune dans les benchmarks existants, qui ont tendance à se concentrer sur les langues anglaise et chinoise, en testant des modèles sur des saisies de texte japonaises étendues.
Le succès des NAMM sur ChouBun met en évidence leur polyvalence dans toutes les langues et prouve leur robustesse dans la gestion des entrées non anglaises, une fonctionnalité clé pour les applications mondiales d’IA. Les NAMM ont pu conserver efficacement le contenu spécifique au contexte tout en éliminant les redondances grammaticales et les jetons moins significatifs, permettant au modèle de fonctionner plus efficacement sur des tâches telles que le résumé long et la compréhension en japonais.
 Source: Sakana AI
Source: Sakana AI
Le les résultats démontrent collectivement que les NAMM excellent dans l’optimisation de l’utilisation de la mémoire sans compromettre la précision. Qu’ils soient évalués sur des tâches nécessitant des séquences extrêmement longues ou dans des contextes linguistiques autres que l’anglais, les NAMM surpassent systématiquement les modèles de base, obtenant à la fois une efficacité informatique et de meilleurs résultats.
Cette combinaison d’économies de mémoire et de gains de précision positionne les NAMM comme une avancée majeure pour les systèmes d’IA d’entreprise chargés de gérer des entrées vastes et complexes.
Les résultats sont particulièrement remarquables par rapport aux méthodes antérieures telles que H₂O et L2, qui sacrifiait les performances au profit de l’efficacité. Les NAMM, en revanche, réalisent les deux.
“Nos résultats démontrent que les NAMM apportent avec succès des améliorations cohérentes sur les axes de performance et d’efficacité par rapport aux transformateurs de base”, déclarent les chercheurs.
Applications multimodales : au-delà du langage
L’une des découvertes les plus impressionnantes était la capacité des NAMM à transférer le tir nul vers d’autres tâches et modalités de saisie.
L’un des plus L’un des aspects remarquables des modèles de mémoire d’attention neuronale (NAMM) est leur capacité à transférer de manière transparente entre différentes tâches et modalités d’entrée, au-delà des applications traditionnelles basées sur le langage.
Contrairement à d’autres méthodes d’optimisation de la mémoire, qui nécessitent souvent un recyclage ou une modification fine. En adaptant chaque domaine, les NAMM conservent leurs avantages en matière d’efficacité et de performances sans ajustements supplémentaires. Les expériences de Sakana AI ont démontré cette polyvalence dans deux domaines clés : la vision par ordinateur et l’apprentissage par renforcement, qui présentent tous deux des défis uniques pour les transformateurs. modèles.
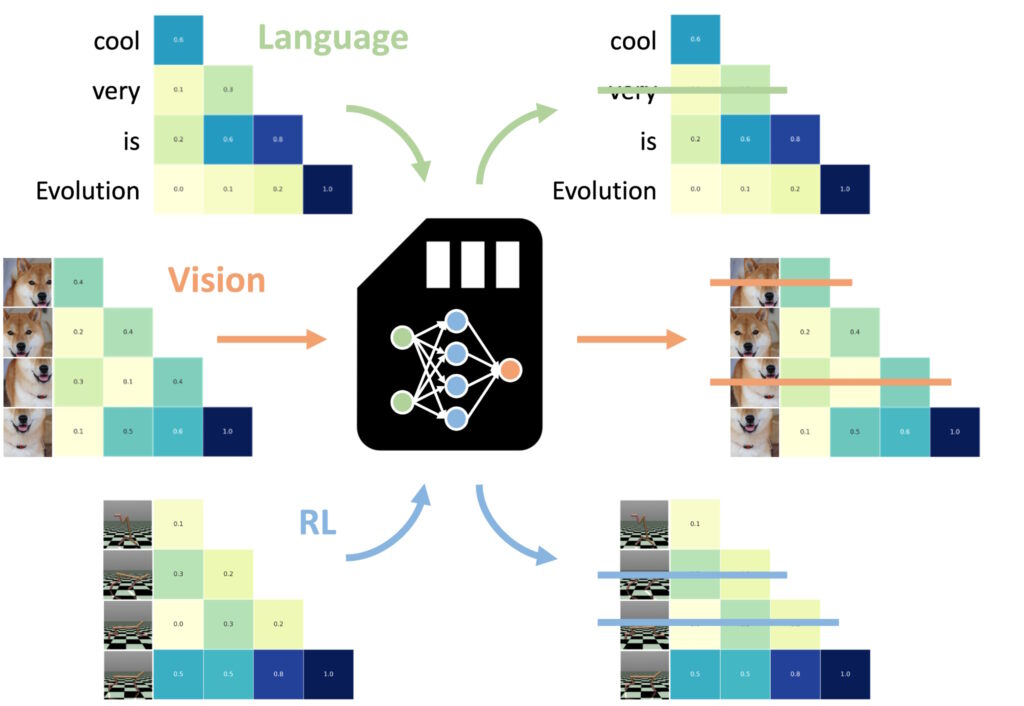 Les NAMM formés sur la langue peuvent être zéro-plan transféré vers d’autres transformateurs à travers les modalités d’entrée et les domaines de tâches. (Image : Sakana AI)
Les NAMM formés sur la langue peuvent être zéro-plan transféré vers d’autres transformateurs à travers les modalités d’entrée et les domaines de tâches. (Image : Sakana AI)
En vision par ordinateur, les NAMM ont été évalués à l’aide du modèle Llava Next Video, un Transformateur conçu pour traiter de longues séquences vidéo. Les vidéos contiennent intrinsèquement de grandes quantités de données redondantes, telles que des images répétées ou des variations mineures qui fournissent peu d’informations supplémentaires.
Les NAMM ont automatiquement identifié et supprimé ces images redondantes lors de l’inférence, compressant efficacement la fenêtre contextuelle sans compromettre la capacité du modèle à interpréter le contenu vidéo.
Par exemple, les NAMM ont conservé les images contenant des détails visuels clés, tels que les changements d’action, les interactions d’objets ou les événements critiques, tout en supprimant les images répétitives ou statiques. Cela a entraîné une amélioration de l’efficacité du traitement, permettant au modèle de se concentrer sur les éléments visuels les plus pertinents, maintenant ainsi la précision tout en réduisant les coûts de calcul.
Dans l’apprentissage par renforcement, les NAMM ont été appliqués au Decision Transformer, un modèle conçu pour traiter des séquences d’actions, d’observations et de récompenses pour optimiser la prise de décision tâches. Les tâches d’apprentissage par renforcement impliquent souvent de longues séquences d’entrées avec différents niveaux de pertinence, où des actions sous-optimales ou redondantes peuvent nuire aux performances.
Les NAMM ont relevé ce défi en supprimant sélectivement les jetons correspondant à des actions inefficaces et à des informations de faible valeur, tout en conservant ceux essentiels à l’obtention de meilleurs résultats.
Par exemple, dans des tâches comme Hopper et Walker2d, qui implique le contrôle d’agents virtuels en mouvement continu, les NAMM ont amélioré les performances de plus de 9%. En filtrant les mouvements sous-optimaux ou les détails inutiles, le Decision Transformer a obtenu un apprentissage plus efficace et efficient, en concentrant sa puissance de calcul sur les décisions qui maximisent le succès de la tâche.
Ces résultats mettent en évidence l’adaptabilité des NAMM dans des domaines très différents. Qu’il s’agisse de traiter des images vidéo dans des modèles de vision ou d’optimiser des séquences d’action dans l’apprentissage par renforcement, les NAMM ont démontré leur capacité à améliorer les performances, à réduire l’utilisation des ressources et à maintenir la précision du modèle, le tout sans recyclage.
Les NAMM apprennent à oublier presque exclusivement des pièces. d’images vidéo redondantes, plutôt que de jetons de langage décrivant l’invite finale, note le document, soulignant l’adaptabilité des NAMM.
Les fondements techniques de NAMM
L’efficience et l’efficacité des modèles de mémoire d’attention neuronale (NAMM) résident dans leur processus d’exécution rationalisé et systématique, qui permet un élagage précis des jetons sans intervention manuelle. Ce processus repose sur trois composants principaux : les spectrogrammes d’attention, la compression des caractéristiques et la notation automatisée.
Les NAMM ajustent dynamiquement leur comportement en fonction des exigences de la tâche et de la profondeur de la couche Transformer. Les premières couches donnent la priorité au contexte « global » comme les descriptions de tâches, tandis que les couches plus profondes conservent les détails « locaux » spécifiques aux tâches. Dans les tâches de codage, par exemple, les NAMM ont ignoré les commentaires et le code passe-partout ; dans les tâches en langage naturel, ils ont éliminé les redondances grammaticales tout en conservant le contenu clé.
Cette conservation adaptative des jetons garantit que les modèles restent concentrés sur les informations pertinentes tout au long du traitement, améliorant ainsi la vitesse et la précision.
Le premier L’étape consiste à générer des spectrogrammes d’attention. Les transformateurs calculent des « valeurs d’attention » à chaque couche pour déterminer l’importance relative de chaque jeton dans la fenêtre contextuelle. Les NAMM transforment ces valeurs d’attention en représentations basées sur la fréquence à l’aide de la Transformation de Fourier à court terme (STFT).
STFT est une technique de traitement du signal largement utilisée qui décompose une séquence en composantes de fréquence localisées au fil du temps, fournissant une représentation compacte mais détaillée d’une importance symbolique. En appliquant STFT, les NAMM convertissent les séquences d’attention brutes en séquences de type spectrogramme. données, permettant une analyse plus claire des jetons qui contribuent de manière significative à la sortie du modèle.
Ensuite, la compression des fonctionnalités est appliquée pour réduire la dimensionnalité des données du spectrogramme tout en préservant ses caractéristiques essentielles. Ceci est réalisé à l’aide d’une moyenne mobile exponentielle (EMA), une méthode mathématique qui compresse les modèles d’attention historiques dans un résumé compact de taille fixe. EMA garantit que les représentations restent légères et gérables, permettant aux NAMM d’analyser efficacement les longues séquences d’attention tout en minimisant la surcharge de calcul.
La dernière étape est la Scoring and Pruning, où les NAMM utilisent une méthode légère. classificateur de réseau neuronal pour évaluer les représentations de jetons compressées et attribuer des scores en fonction de leur importance. Les jetons dont les scores sont inférieurs à un seuil défini sont supprimés de la fenêtre contextuelle, « oubliant » efficacement les détails inutiles ou redondants. Ce mécanisme de notation permet aux NAMM de prioriser les jetons critiques qui contribuent au processus de prise de décision du modèle tout en supprimant les données les moins pertinentes.
Ce qui rend les NAMM particulièrement efficaces, c’est leur recours à l’optimisation évolutive pour affiner ce processus. Les méthodes d’optimisation traditionnelles telles que la descente de gradient ont du mal à gérer des tâches non différenciables, telles que la décision. si un jeton doit être conservé ou rejeté.
Au lieu de cela, les NAMM utilisent un algorithme évolutif itératif, inspiré de la sélection naturelle, pour « muter » et « sélectionner » les stratégies de gestion de la mémoire les plus efficaces au fil du temps. , le système évolue pour hiérarchiser automatiquement les jetons essentiels, atteignant un équilibre entre performances et efficacité de la mémoire sans nécessiter de réglage manuel.
Cette exécution rationalisée, combinant une analyse de jetons basée sur un spectrogramme, une compression efficace et une élagage: permet aux NAMM de réaliser à la fois des économies de mémoire significatives et des gains de performances sur diverses tâches basées sur Transformer. En réduisant les exigences de calcul tout en maintenant ou en améliorant la précision, les NAMM établissent une nouvelle référence en matière de gestion efficace de la mémoire dans les modèles d’IA modernes.
Quelle est la prochaine étape pour les Transformers ?
Sakana AI pense que les NAMM ne sont qu’un début. Alors que les travaux actuels se concentrent sur l’optimisation des modèles pré-entraînés lors de l’inférence, les recherches futures pourraient intégrer les NAMM dans le processus de formation lui-même. Cela pourrait permettre aux modèles d’apprendre des stratégies de gestion de la mémoire de manière native, prolongeant ainsi la longueur des fenêtres de contexte et améliorant l’efficacité entre les domaines.
« Ce travail ne fait que commencer à explorer l’espace de conception de nos modèles de mémoire, ce que nous prévoyons peut offrir de nombreuses nouvelles opportunités pour faire progresser les futures générations de transformateurs”, conclut l’équipe.
La capacité éprouvée des NAMM à adapter les performances, à réduire les coûts et à s’adapter à toutes les modalités établit une nouvelle norme pour l’efficacité des projets à grande échelle. Modèles d’IA.