Les chercheurs du Tencent AI Lab ont dévoilé un nouveau cadre d’IA conçu pour dépasser les limites de vitesse des grands modèles de langage actuels.
Détaillé dans un article publié en ligne cette semaine, le système s’appelle CALM, pour Continu Autoregressive Language Models. Il remet directement en question le lent processus jeton par jeton qui alimente la plupart des IA génératives actuelles.
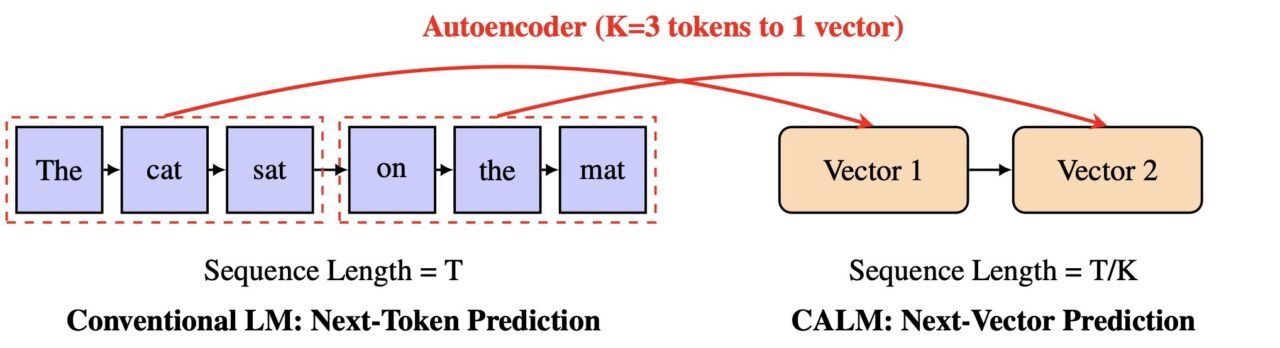
Au lieu de prédire un petit morceau de mot à la fois, CALM apprend à prédire un seul vecteur qui représente tout un morceau de texte. Cette méthode pourrait rendre la génération d’IA beaucoup plus rapide et plus efficace, ouvrant ainsi une nouvelle voie pour la mise à l’échelle des modèles.
La tyrannie du jeton : l’autorégression de l’IA Goulot d’étranglement
Une faiblesse fondamentale des LLM modernes est leur dépendance à l’égard d’une génération autorégressive, jeton par jeton. Cette dépendance séquentielle constitue le plus grand goulot d’étranglement limitant la vitesse et l’évolutivité de l’IA.
La génération d’un long article nécessite des milliers d’étapes de prédiction séquentielles, ce qui rend le processus coûteux et lent en termes de calcul. Ce n’est pas seulement un problème académique ; c’est pourquoi l’utilisation de modèles puissants est coûteuse et la génération de formulaires longs en temps réel reste un défi.
Ce problème d’efficacité est devenu un champ de bataille central pour les développeurs d’IA. Comme Google Research l’a déjà souligné : “à mesure que nous déployons ces modèles auprès d’un plus grand nombre d’utilisateurs, les rendre plus rapides et moins coûteux sans sacrifier la qualité constitue un défi crucial.”
Le secteur a exploré de nombreuses solutions, depuis les cascades spéculatives de Google jusqu’aux nouvelles techniques de compression. Désormais, les travaux de Tencent proposent une solution plus radicale.
L’article propose un modèle pour une nouvelle classe de modèles de langage ultra-efficaces et pour le goulot d’étranglement induit par les jetons pour la vitesse.
L’objectif est de changer fondamentalement l’unité de prédiction d’un jeton unique à faible information à quelque chose de beaucoup plus riche.
Un nouveau paradigme : prédire des vecteurs au lieu de jetons
Dans un défi direct Au statu quo de l’IA générative, CALM recadre entièrement la tâche de prédiction. Les chercheurs proposent un nouvel axe de mise à l’échelle pour les LLM.
« Nous soutenons que surmonter ce goulot d’étranglement nécessite un nouvel axe de conception pour la mise à l’échelle des LLM: augmenter la bande passante sémantique de chaque étape générative », écrivent-ils dans l’article.
En augmentant cette « bande passante sémantique », le modèle peut traiter plus d’informations en une seule étape. CALM y parvient grâce à un processus innovant en deux étapes qui fonctionne dans un espace continu plutôt que discret.
Au cœur de la conception de CALM se trouve un auto-encodeur haute fidélité. Ce composant apprend à compresser un morceau de K jetons – par exemple quatre jetons – en un seul vecteur continu et dense.
Il est surtout possible de reconstruire les jetons d’origine à partir de ce vecteur avec une précision de plus de 99,9 %. Un modèle de langage distinct effectue ensuite une prédiction autorégressive dans ce nouvel espace vectoriel.
Selon la documentation officielle du projet,”au lieu de prédire un jeton discret à la fois, CALM apprend à prédire un seul vecteur continu qui représente un morceau entier de K jetons.”
Cela réduit le nombre d’étapes génératives d’un facteur de K, conduisant à des gains d’efficacité significatifs.
La boîte à outils sans vraisemblance : comment CALM apprend et mesure le succès
Le passage de jetons discrets à des vecteurs continus introduit un défi majeur : le modèle ne peut plus calculer une distribution de probabilité explicite sur tous les résultats possibles à l’aide d’une couche softmax standard.
Cela rend les méthodes traditionnelles de formation et d’évaluation, qui reposent sur le calcul des vraisemblances, inapplicables. Pour résoudre ce problème, l’équipe Tencent a développé un cadre complet et sans vraisemblance.
Pour la formation, CALM utilise une méthode de formation basée sur l’énergie, qui utilise une règle de notation strictement appropriée pour guider le modèle sans avoir besoin de calculer les probabilités.
Pour l’évaluation, les chercheurs ont introduit une nouvelle métrique appelée BrierLM. S’éloignant des mesures traditionnelles comme la perplexité, BrierLM est dérivé du score Brier, un outil de prévision probabiliste.
Il permet une comparaison équitable, basée sur des échantillons, des capacités du modèle en vérifiant dans quelle mesure les prédictions s’alignent sur la réalité, une méthode parfaitement adaptée aux modèles où les probabilités sont intraitables.
Un nouvel axe pour la mise à l’échelle de l’IA et la course à l’efficacité
L’impact pratique de cette nouvelle architecture est un compromis performances-calcul supérieur.
Le modèle CALM réduit les besoins de calcul de formation de 44 % et d’inférence de 33 % par rapport à une base de référence solide. Cela démontre que l’augmentation de la bande passante sémantique de chaque étape constitue un nouveau levier puissant pour améliorer l’efficacité informatique.
Ces travaux positionnent CALM comme un concurrent important dans la course à l’échelle de l’industrie pour créer une IA plus rapide, moins chère et plus accessible.
Google s’est attaqué au problème de vitesse de l’IA avec des méthodes telles que les cascades spéculatives et l’apprentissage imbriqué. D’autres startups, comme Inception, explorent des architectures totalement différentes, comme les LLM basés sur la diffusion, dans son “Mercury Coder” pour échapper au”goulot d’étranglement structurel”de l’autorégression.
Ensemble, ces approches variées mettent en évidence un changement dans le développement de l’IA. L’industrie passe d’une simple focalisation sur l’échelle à une recherche plus durable d’une intelligence artificielle plus intelligente et plus viable économiquement. L’approche vectorielle de CALM offre une nouvelle voie à suivre sur ce front.


