Une nouvelle étude universitaire jette de sérieux doutes sur la fiabilité de la recherche basée sur l’IA de Google et d’OpenAI. Un document de recherche récemment publié révèle que les outils de recherche générative utilisent souvent des sources moins nombreuses ou moins populaires que la recherche Google traditionnelle.
Les systèmes d’IA ont également du mal à traiter des sujets sensibles au facteur temps et présentent des incohérences majeures sur quelques mois seulement. Ces résultats suggèrent que même si l’IA peut fournir des réponses rapides, elle est souvent à la traîne en termes de précision et de qualité des sources, ce qui pose un défi aux utilisateurs qui comptent sur la recherche d’informations à jour.
La recherche IA mise sur moins de sources et moins populaires
En se plongant dans les mécanismes de recherche par l’IA, le nouveau article publié sur arXiv révèle un changement fondamental dans la manière dont les informations sont obtenues. Les chercheurs Elisabeth Kirsten et ses collègues ont comparé la recherche Google traditionnelle à quatre systèmes d’IA générative : Google’s AI Overview, Gemini 2.5 Flash, GPT-4o Search et GPT-4o avec un outil de recherche.
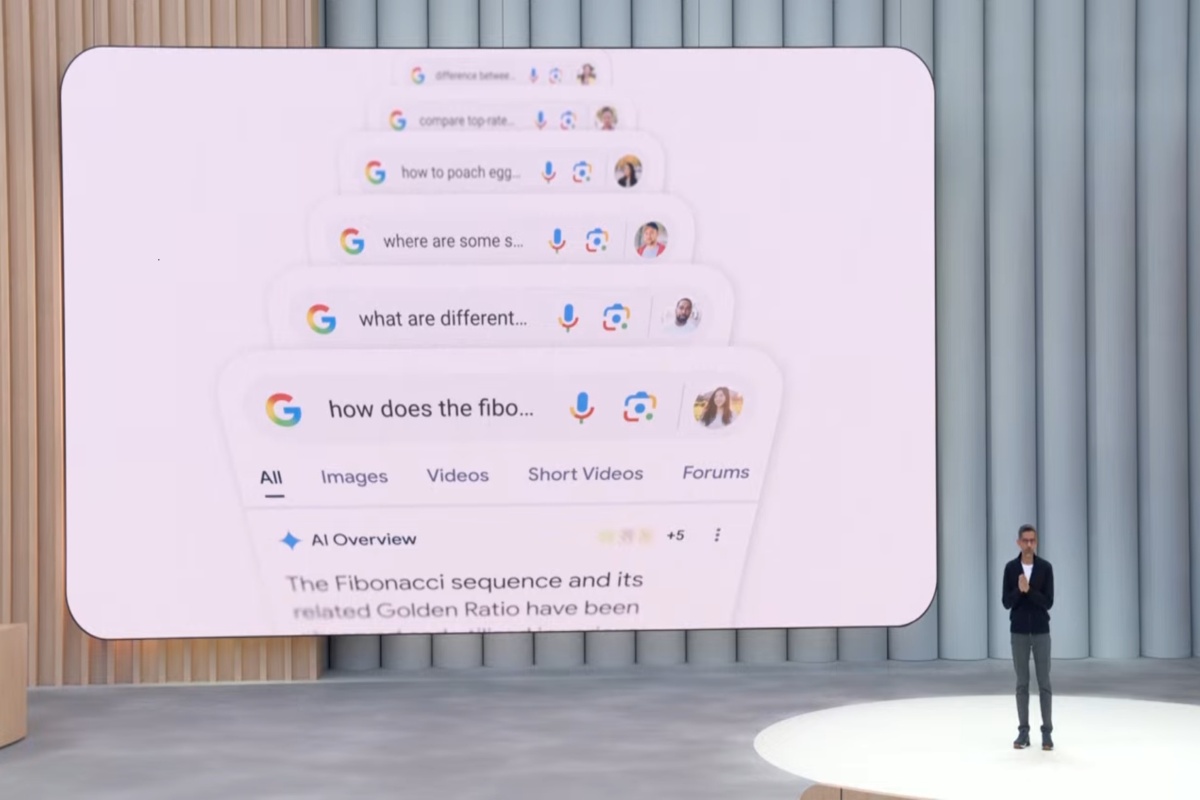
Leur analyse de plus de 4 600 requêtes couvrant les connaissances générales, la politique, la science et le shopping a révélé que les résultats générés par l’IA proviennent souvent d’une tranche différente, et souvent moins importante, du Web.
A Il est frappant de constater que 53 % des sites Web liés par l’IA Overview de Google n’apparaissent pas dans le top 10 des résultats d’une recherche conventionnelle. Cela indique une divergence significative par rapport aux signaux de classement établis de la recherche traditionnelle.
Citant beaucoup moins de sources que ses homologues, le GPT-4o d’OpenAI avec un outil de recherche s’est appuyé sur une moyenne de seulement 0,4 page Web par requête, s’appuyant fortement sur ses connaissances internes pré-entraînées.
En revanche, AI Overview et Gemini de Google ont tous deux cité plus de 8,5 pages en moyenne, montrant un un recours accru à la récupération Web externe. Pour les requêtes ambiguës, l’étude a noté que la recherche traditionnelle offrait toujours une meilleure couverture de plusieurs points de vue.
Instable et peu fiable : l’IA répond au changement de jour en jour
Au-delà du sourcing, l’étude expose un défaut critique de cohérence. Les moteurs de recherche génératifs semblent être très volatils, leurs réponses et leurs sources changeant considérablement sur de courtes périodes.
Pour tester cela, les chercheurs ont répété leurs requêtes à deux mois d’intervalle et ont mesuré la stabilité des résultats. Pour les utilisateurs qui attendaient des informations fiables et reproductibles, le résultat était préoccupant.
Les résultats du nouveau test ont été décevants. La recherche Google traditionnelle a maintenu une cohérence de 45 % dans les sources présentées. En baisse, l’AI Overview de Google n’a montré qu’une cohérence de 18 %, ce qui signifie que ses sources sous-jacentes étaient presque entièrement différentes d’un test à l’autre.
Cette instabilité suggère que les réponses synthétisées que reçoivent les utilisateurs ne sont pas seulement différentes de la recherche traditionnelle, mais sont également imprévisibles d’un jour à l’autre, ce qui compromet leur fiabilité pour toute tâche de recherche ou de vérification sérieuse.
Lutte avec le « maintenant » : L’IA échoue dans les actualités urgentes
Pour les requêtes urgentes sur des événements récents, l’étude a révélé des échecs critiques qui mettent en évidence le danger de s’appuyer sur des modèles d’IA dotés de connaissances internes obsolètes. Les chercheurs ont testé les systèmes en utilisant des sujets d’actualité, notamment une requête sur la « cause du décès de Ricky Hatton », un ancien boxeur décédé en septembre 2025.
Les deux modèles GPT, lorsqu’ils ne s’appuyaient pas beaucoup sur la récupération Web en temps réel, ont échoué au test. Ils ont signalé à tort que Hatton était toujours en vie, une erreur factuelle importante provenant d’un manque d’accès aux informations actuelles.
Cet échec spécifique démontre une faiblesse fondamentale : sans récupération robuste et dynamique, la recherche par l’IA peut présenter en toute confiance des informations dangereusement obsolètes comme des faits. Même si les systèmes de récupération augmentée comme Gemini ont obtenu de meilleurs résultats, l’incident souligne les risques d’actualités de dernière minute ou d’événements évolutifs.
Un écart de confiance grandissant dans la guerre de l’information sur l’IA
De tels modèles de manque de fiabilité font écho aux conclusions récentes d’une étude historique de la BBC, qui a révélé des erreurs significatives dans 45 % des réponses liées à l’actualité fournies par les assistants IA. Ce rapport faisait état de l’utilisation de « citations cérémonielles » : des liens qui semblent faire autorité mais qui ne soutiennent pas réellement les affirmations formulées.
Jean Philip De Tender, directeur des médias à l’UER, a souligné la nature systémique du problème.”Cette recherche montre de manière concluante que ces échecs ne sont pas des incidents isolés. Ils sont systémiques, transfrontaliers et multilingues, et nous pensons que cela met en danger la confiance du public.”
Un nombre croissant de preuves alimente un conflit déjà tendu entre les plateformes technologiques et les éditeurs de presse. Les éditeurs affirment que les moteurs de recherche IA non seulement ne sont pas fiables, mais qu’ils nuisent activement à leurs activités en supprimant le contenu pour fournir des réponses directes, éliminant ainsi la nécessité pour les utilisateurs de cliquer jusqu’à la source d’origine.
Cette tendance, confirmée par une étude du Pew Research Center montrant que les clics chutent lorsque les aperçus de l’IA apparaissent, rompt l’échange de valeurs de longue date du Web ouvert.
Comme Danielle Coffey, PDG de News/Media Selon Alliance,”Les liens étaient la dernière qualité rédemptrice de la recherche qui a donné du trafic et des revenus aux éditeurs. Désormais, Google prend le contenu de force et l’utilise sans retour.”
En fin de compte, les auteurs de l’article affirment que l’ensemble du cadre permettant d’évaluer la qualité de la recherche a besoin d’une refonte à l’ère de l’IA. Les mesures actuelles, conçues pour les listes de liens classées, sont insuffisantes pour évaluer ces nouveaux systèmes.
« Nos travaux démontrent la nécessité de nouvelles méthodes d’évaluation qui prennent en compte conjointement la diversité des sources, la couverture conceptuelle et le comportement de synthèse dans les systèmes de recherche générative. »
Les auteurs soulignent également la nécessité de meilleurs mécanismes pour gérer la nature rapide de l’information en ligne.
« Ces résultats soulignent l’importance de intégrant la conscience temporelle et la récupération dynamique dans les cadres d’évaluation de la recherche générative.”
Tant que de telles normes ne seront pas développées et adoptées, la promesse d’une recherche par IA plus intelligente et plus rapide reste assombrie par des problèmes persistants de fiabilité, de cohérence et de confiance.