Depuis des années, la recherche sur l’intelligence artificielle est dominée par les entreprises qui déversent des milliards dans des modèles d’IA massifs, en supposant que la puissance informatique pure les maintiendrait en tête. Mais un nouveau projet de l’Université de Stanford et de l’Université de Washington remet en question cette croyance.
Leur dernier modèle, S1, a été formé pour moins de 50 $ en coûts de calcul, mais se comporte de manière compétitive avec des modèles d’IA de raisonnement développés par OpenAI et Deepseek.
Contrairement aux modèles propriétaires qui nécessitent une infrastructure approfondie et des mois de formation, S1 a été affinée en moins de 30 minutes en utilisant seulement 16 GPU NVIDIA H100, selon les chercheurs.
lié: étreint le visage étreint prend la recherche profonde d’Openai avec l’alternative open-open alternative
Son code, sa méthodologie et son ensemble de données ont été mis à disposition via un référentiel github open-source , ce qui le rend accessible pour que quiconque puisse inspecter, reproduire ou s’améliorer. Le projet soulève une question critique pour l’industrie de l’IA: un budget de plusieurs milliards de dollars est-il toujours nécessaire pour rivaliser au plus haut niveau?
Un modèle qui met les stratégies d’IA Openai et Google à risque
Les géants de l’IA comme OpenAI, Google et Microsoft ont lancé fortement leur capacité à dépenser des concurrents dans la formation et l’infrastructure du modèle AI.
Le modèle O1 d’Openai et le flash GEMINI 2.0 de Google’s Gemini 2.0’s sont conçus avec cet avantage à l’esprit. Cependant, le développement de S1 prouve que les capacités de raisonnement de haut niveau peuvent être reproduites à une fraction du coût.
L’équipe de recherche derrière S1 a utilisé une technique appelée distillation, où un modèle plus petit est formé pour imiter les réponses des réponses de Un système d’IA plus grand.
Au lieu de développer un modèle d’IA à partir de zéro, ils ont pris QWEN2.5-32B-Istruct, un modèle disponible librement dans le laboratoire Qwen AI d’Alibaba et l’a affiné en utilisant 1000 soigneusement sélectionnés soigneusement sélectionnés soigneusement Questions de mathématiques et de raisonnement.
Notamment, l’ensemble de données a été généré à l’aide du modèle expérimental Flash Thinking Gemini 2.0 de Google. As stated in the s1 research paper, “we construct s1K, which consists of 1,000 carefully curated questions paired with reasoning traces et réponses distillées à partir de la pensée Gemini Expérimental.”
lié: Google publie des modèles Gemini 2.0 Pro expérimentaux et de nouveaux modèles AI Flash-Lite
pendant que Google fournit Accès gratuit à l’API à ce modèle, ses conditions d’utilisation interdisent à l’utilisation de ses résultats pour développer des modèles d’IA concurrents. Modèles
Bien qu’il ait été formé sur un ensemble de données relativement petit, S1 atteint des niveaux de performance comparables aux modèles d’Openai et Deepseek.
sur la référence AIME24, qui mesure le problème mathématique AI-Capacité de résolution, S1 a obtenu un score de précision de 56,7%, surpassant O1-Preview d’OpenAI, qui a marqué 44,6%. , le modèle montre certaines limites dans les connaissances scientifiques plus larges. Sur le benchmark GPQA-Diamond, qui contient des problèmes avancés de physique, de biologie et de chimie, S1 a marqué 59,6%, en prenant du retard sur les modèles d’Openai et Google.
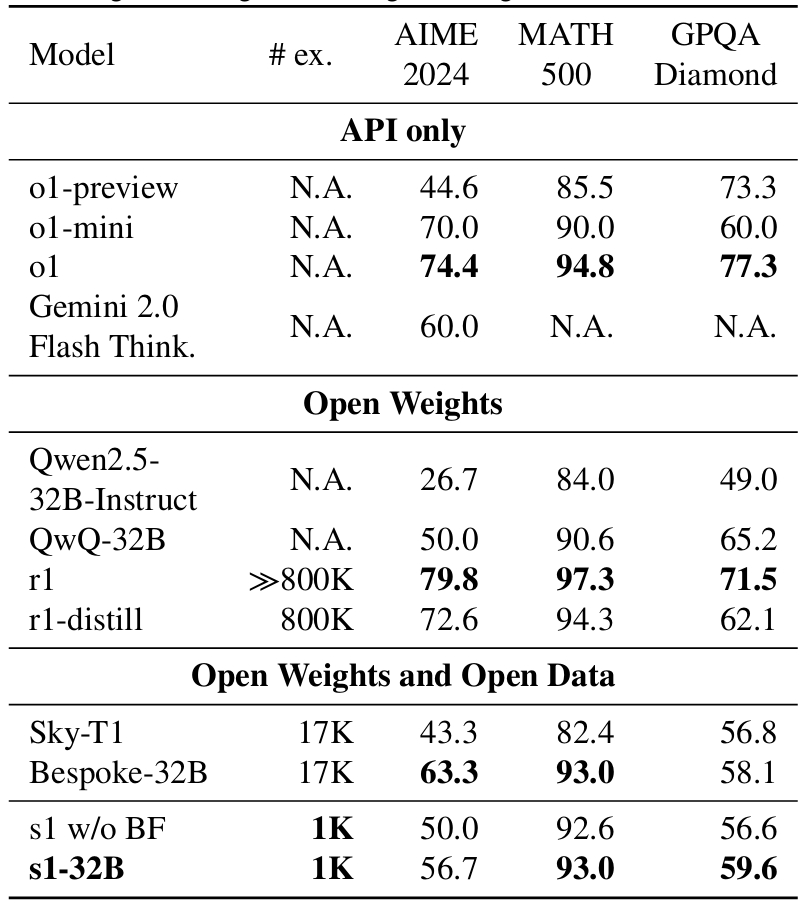 s1 model performance benchmarks compared to leading AI models from Google et Openai
s1 model performance benchmarks compared to leading AI models from Google et Openai
Pourtant, pour un modèle formé en moins de 30 minutes avec un calcul minimal, ces résultats remettent en question l’hypothèse que les ensembles de données plus importants et les cycles d’entraînement plus longs sont toujours nécessaires.
Une astuce inattendue qui Améliore le raisonnement de l’IA
La recherche a également révélé une constatation inattendue qui a amélioré la précision de S1. Au lieu de modifier le modèle lui-même, ils ont expérimenté la façon dont les invites ont été structurées.
L’étude indique: «Nous développons le forçage du budget à contrôler le calcul du temps de test en terminant avec force le processus de réflexion du modèle ou en l’allongeant en ajoutant «Attendez» plusieurs fois à la génération du modèle lorsqu’il essaie de se terminer. Cela peut conduire le modèle à revérifier sa réponse, fixant souvent des étapes de raisonnement incorrectes.”
ajoutant simplement le mot”attendre”dans l’invite forcée S1 à passer plus de temps à considérer sa réponse avant de finaliser une réponse. Cette approche s’aligne sur Recherches récentes sur la mise à l’échelle du temps de test , où les modèles améliorent la précision en allouant Plus de calcul à des tâches complexes au lieu de répondre instantanément.
pourrait ouvrir et Google à verrouiller leurs modèles d’IA?
L’essor du raisonnement AI à faible coût Des modèles comme S1 présentent un défi pour les entreprises qui ont investi massivement dans des systèmes d’IA exclusifs.
OpenAI et Google ont fait valoir que la création de modèles d’IA fiables et sûrs nécessite des ressources de calcul importantes, justifiant leurs services d’IA premium et leurs politiques d’accès restrictives et restrictives.
Cependant, alors que de plus en plus de chercheurs démontrent que les capacités de l’IA de haut niveau peuvent être reproduites à moindre coût, ces entreprises peuvent rechercher de nouvelles façons de protéger leurs modèles contre les inarciens ou distillés en petits concurrents.
Openai a déjà montré des signes de resserrement de l’accès à sa technologie. La société restreint actuellement sa fonction de recherche approfondie aux utilisateurs payants de Chatgpt Pro, limitant la capacité des développeurs d’IA externes à étudier ses méthodes. Google, quant à lui, impose des limites de taux strictes à l’accès à son API Gemini 2.0 et interdit explicitement la formation de modèles d’IA concurrents en utilisant ses résultats.
Avec des projets tels que S1 Emerging, il y a une probabilité croissante que les entreprises mettent en œuvre des techniques d’eau ou des restrictions légales pour empêcher que leurs résultats générés par l’IA ne soient utilisés pour la formation d’autres systèmes. Cependant, l’application de ces règles dans les environnements de recherche d’IA open source sera extrêmement difficile.
L’avenir de l’IA: recherche ouverte ou contrôle d’entreprise?
As La recherche sur l’IA continue de progresser, la bataille entre l’innovation open source et le développement de l’IA propriétaire devient plus intense. Le succès des modèles AI distillés comme S1 et Sky-T1 suggère que les capacités AI ne sont plus exclusifs aux géants de la technologie.
Les grandes sociétés d’IA soutiennent que les modèles propriétaires offrent un meilleur contrôle sur les risques d’IA, assurant la sécurité, la réduction des biais et la conformité réglementaire. Mais les chercheurs indépendants ont contrecarré que les modèles open source améliorent la transparence, permettant aux experts d’auditer et d’affiner les systèmes d’IA sans influence d’entreprise.
Les gouvernements et les régulateurs regardent également de près ces développements. L’élaboration des politiques de l’IA s’est jusqu’à présent concentrée sur la gouvernance de modèles à grande échelle, mais l’émergence de techniques de réplication de l’IA à faible coût pourrait déplacer la conversation vers les restrictions d’accès aux données et les considérations éthiques.
La libération de S1 signale un changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change ce changement qui change de changement qui change ce changement qui’pourrait remodeler l’industrie de l’IA. Si un raisonnement puissant AI peut être reproduit pour moins de 50 $, les petites équipes et startups de recherche sur l’IA pourraient bientôt avoir la capacité de rivaliser avec des sociétés d’IA d’un milliard de dollars.
Pour l’instant, S1 reste open-source, ce qui signifie que les chercheurs dans le monde peut tester, modifier et développer ses capacités. Cependant, si OpenAI, Google et d’autres laboratoires d’IA voient cela comme une menace, ils peuvent faire pression pour des contrôles d’accès API plus stricts, des restrictions de licence ou même une action en justice contre les méthodes de distillation de l’IA.
L’avenir sera défini par des modèles propriétaires contrôlés par l’entreprise, ou les recherches d’IA ouvriront-elles de progresser, ce qui rend le raisonnement d’IA de haut niveau accessible à tous? Faites-nous savoir dans les commentaires ce que vous en pensez.