Des chercheurs de l’Université d’intelligence artificielle Mohamed bin Zayed (MBZUAI) à Abu Dhabi ont a dévoilé LlamaV-o1, un nouveau modèle d’IA multimodal qui donne la priorité à la transparence et à la cohérence logique du raisonnement.
Contrairement à d’autres modèles d’IA de raisonnement, qui fournissent souvent des résultats de type boîte noire, LlamaV-o1 démontre son processus de résolution de problèmes étape par étape, permettant aux utilisateurs de retracer chaque étape de sa logique.
Associé à l’introduction de VRC-Bench, une nouvelle référence pour évaluer les étapes de raisonnement intermédiaires, LlamaV-o1 offre une nouvelle perspective sur l’interprétabilité et l’utilisabilité de l’IA dans divers domaines tels que le diagnostic médical, la finance et la science. recherche.
La publication de ce modèle et de ce benchmark reflète la demande croissante d’IA. des systèmes qui non seulement fournissent des résultats précis, mais expliquent également comment ces résultats sont obtenus.
Connexe : OpenAI dévoile le nouveau modèle o3 avec des compétences de raisonnement considérablement améliorées
VRC-Bench : un benchmark conçu pour un raisonnement transparent
Le benchmark VRC-Bench est un élément central de Développement et évaluation de LlamaV-o1. Les benchmarks traditionnels de l’IA se concentrent principalement sur l’exactitude des réponses finales, négligeant souvent les processus logiques qui mènent à ces réponses.
VRC-Bench résout cette limitation en évaluant la qualité des étapes de raisonnement grâce à des mesures telles que l’étape de fidélité et la couverture sémantique, qui mesurent dans quelle mesure le raisonnement d’un modèle s’aligne avec le matériel source et la cohérence logique.
Connexe : Le nouveau modèle de réflexion Flash Gemini 2.0 de Google défie l’o1 Pro d’OpenAI avec d’excellentes performances
Couvrant plus de 1 000 tâches dans huit catégories, VRC-Bench comprend des domaines tels que le raisonnement visuel, l’imagerie médicale et l’analyse du contexte culturel. Ces tâches comportent plus de 4 000 étapes de raisonnement vérifiées manuellement, ce qui fait de l’évaluation l’une des plus complètes en matière d’évaluation du raisonnement étape par étape.
Les chercheurs décrivent son importance en déclarant: « La plupart des benchmarks se concentrent principalement sur la précision de la tâche finale, négligeant la qualité des étapes de raisonnement intermédiaires. VRC-Bench présente un ensemble diversifié de défis… permettant une évaluation robuste de la cohérence logique et de l’exactitude du raisonnement.”
En établissant une nouvelle norme pour l’évaluation multimodale de l’IA, VRC-Bench garantit que les modèles comme LlamaV-o1 sont tenus responsables de leurs processus de prise de décision, offrant un niveau de transparence essentiel pour les applications à enjeux élevés.
Mesures de performance : comment se présente LlamaV-o1 Out
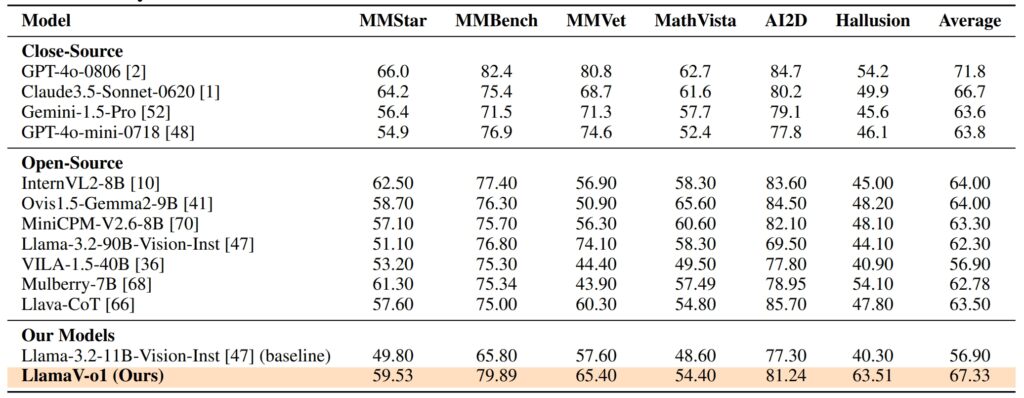
Les performances de LlamaV-o1 sur VRC-Bench et d’autres tests démontrent ses prouesses techniques. Il a obtenu un score de raisonnement de 68,93, surpassant d’autres modèles open source comme LLava-CoT (66,21) et réduisant l’écart avec des modèles propriétaires tels que le GPT-4o, qui a obtenu un score de 71,8
En plus de sa précision, LlamaV-o1 a fourni des vitesses d’inférence cinq fois plus rapides que ses pairs, démontrant son efficacité.
Sur six tests multimodaux, dont MathVista, AI2D et Hallusion, LlamaV-o1 a obtenu un score moyen de 67,33 %. souligne sa capacité à gérer diverses tâches de raisonnement tout en maintenant la cohérence logique et la transparence.
Formation LlamaV-o1 : la synergie entre l’apprentissage du programme et la recherche de faisceaux
Le succès de LlamaV-o1 est enraciné dans ses méthodes de formation innovantes. Les chercheurs ont utilisé l’apprentissage curriculaire, une technique inspirée de l’éducation humaine.
Cette approche commence par des tâches plus simples et progresse progressivement vers des tâches plus complexes, permettant au modèle de développer des compétences de raisonnement fondamentales avant de s’attaquer à des défis avancés.
En structurant le processus de formation, l’apprentissage du programme améliore la capacité du modèle à généraliser à diverses tâches, de l’OCR de documents au raisonnement scientifique.
Connexe : QwQ d’Alibaba-32B-Preview rejoint la bataille de raisonnement des modèles d’IA avec OpenAI
Beam Search, un algorithme d’optimisation, améliore cette approche de formation en générant plusieurs chemins de raisonnement en parallèle et en sélectionnant le plus logique. Cette méthode améliore non seulement la précision du modèle, mais réduit également les coûts de calcul, le rendant ainsi plus efficace pour les applications réelles.
Comme l’expliquent les chercheurs :”En tirant parti de l’apprentissage du programme et de Beam Search, notre modèle acquiert progressivement des compétences… garantissant à la fois une inférence optimisée et des capacités de raisonnement robustes.”
Applications en médecine , Finance et au-delà
Les capacités de raisonnement transparentes de LlamaV-o1 le rendent particulièrement adapté aux applications où la confiance et l’interprétabilité sont essentielles. En imagerie médicale, par exemple, le modèle peut fournir non seulement un diagnostic. mais un détail explication de la façon dont il est arrivé à cette conclusion.
Cette fonctionnalité permet aux radiologues et à d’autres professionnels de la santé de valider les informations basées sur l’IA, améliorant ainsi la confiance et la précision dans la prise de décision critique.
Dans le secteur financier, LlamaV-o1 excelle dans l’interprétation de tableaux et de diagrammes complexes, proposant des analyses étape par étape qui fournissent des informations exploitables.
LlamaV-o1 représente une avancée significative dans l’IA multimodale, en particulier dans sa capacité fournir un raisonnement transparent. En combinant l’apprentissage du programme et Beam Search avec les mesures d’évaluation robustes de VRC-Bench, il établit une nouvelle référence en matière d’interprétabilité et d’efficacité.
À mesure que les systèmes d’IA sont de plus en plus intégrés dans des secteurs critiques, le besoin de modèles capables d’expliquer leurs processus de raisonnement ne fera que croître.