DeepSeek AI a publié DeepSeek-VL2, une famille de modèles de langage de vision (VLM) désormais disponibles sous licences open source. La série présente trois variantes: Tiny, Small et le standard VL2, avec des tailles de paramètres activés de 1,0 milliard, 2,8 milliards et 4,5 milliards, respectivement.
Les modèles sont accessibles via GitHub et Visage câlin. Ils promettent de faire progresser les applications clés de l’IA, notamment la réponse visuelle aux questions (VQA), la reconnaissance optique de caractères (OCR) et l’analyse de documents et de graphiques haute résolution.
Selon la documentation officielle de GitHub, « DeepSeek-VL2 démontre des capacités supérieures dans diverses tâches, y compris, mais sans s’y limiter, la réponse visuelle aux questions, la compréhension de documents/tableaux/graphiques et la mise à la terre visuelle. »
Le timing de cette version place DeepSeek AI en concurrence directe avec des acteurs majeurs comme OpenAI et Google, qui dominent tous deux le domaine de l’IA en langage de vision avec des technologies propriétaires. des modèles tels que GPT-4V et Gemini-Exp.
L’accent mis par DeepSeek sur l’open source. Cette collaboration, combinée aux fonctionnalités techniques avancées de la famille VL2, la positionne comme une option gratuite pour les chercheurs.
Carrelage dynamique : faire progresser le traitement des images haute résolution
L’une des avancées les plus notables de DeepSeek-VL2 est sa stratégie d’encodage de vision en mosaïque dynamique, qui révolutionne la façon dont les modèles traitent les données visuelles haute résolution.
Contrairement aux approches traditionnelles à résolution fixe, la dynamique la mosaïque divise les images en mosaïques plus petites et flexibles qui s’adaptent à différents formats d’image. Cette méthode garantit une extraction détaillée des caractéristiques tout en maintenant l’efficacité des calculs.
Sur son référentiel GitHub, DeepSeek décrit cela comme un moyen de « traiter efficacement des images haute résolution avec des formats d’image variables, en évitant la mise à l’échelle informatique généralement associée à l’augmentation des résolutions d’image. »
Cette capacité permet à DeepSeek-VL2 d’exceller dans des applications telles que la mise à la terre visuelle, où une haute précision est essentielle pour identifier des objets dans des images complexes, et dans les tâches OCR denses, qui nécessitent le traitement de texte dans des documents ou des graphiques détaillés.
En s’ajustant dynamiquement à différentes résolutions d’image et formats d’image, les modèles surmontent les limites des méthodes d’encodage statiques, ce qui les rend adaptés aux cas d’utilisation qui exigent à la fois flexibilité et précision.
Mélange de-Experts et attention latente multi-têtes pour l’efficacité
Les gains de performances de DeepSeek-VL2 sont en outre soutenus par son intégration du cadre Mixture-of-Experts (MoE) et Mécanisme d’attention latente multi-têtes (MLA)
L’architecture MoE active de manière sélective des sous-ensembles spécifiques, ou « experts », au sein du modèle pour gérer les tâches plus efficacement. Cette conception réduit la surcharge de calcul en n’engageant que les paramètres nécessaires pour chaque opération, une fonctionnalité particulièrement utile dans les environnements aux ressources limitées.
Le mécanisme MLA complète le cadre MoE en compressant le cache clé-valeur en latentes. vecteurs lors de l’inférence. Cette optimisation minimise l’utilisation de la mémoire et augmente les vitesses de traitement sans sacrifier la précision du modèle.
Selon la documentation technique,”L’architecture MoE, combinée au MLA, permet à DeepSeek-VL2 d’atteindre des performances compétitives ou supérieures à celles des modèles denses avec moins de paramètres activés.”
Pipeline de formation en trois étapes
Le développement de DeepSeek-VL2 impliquait un pipeline de formation rigoureux en trois étapes conçu pour optimiser les capacités multimodales du modèle. La première étape était axée sur le langage visuel. l’alignement, où les modèles ont été entraînés à intégrer des caractéristiques visuelles avec des informations textuelles.
Cela a été réalisé à l’aide d’ensembles de données tels que ShareGPT4V, qui fournissent des exemples d’images et de textes appariés pour l’alignement initial. qui incorporait une gamme diversifiée d’ensembles de données, notamment WIT, WikiHow et des données OCR multilingues, pour améliorer les capacités de généralisation du modèle dans plusieurs domaines
Enfin, la troisième étape consistait en une étude supervisée. réglage fin (SFT), où des ensembles de données spécifiques à une tâche ont été utilisés pour affiner les performances du modèle dans des domaines tels que la base visuelle, la compréhension de l’interface utilisateur graphique (GUI) et le sous-titrage dense.
Ces étapes de formation ont permis à DeepSeek-VL2 pour construire une base solide pour la compréhension multimodale tout en permettant aux modèles de s’adapter à des tâches spécialisées. L’incorporation d’ensembles de données multilingues a encore amélioré l’applicabilité des modèles dans les contextes mondiaux de recherche et industriels.
Connexe : Le modèle chinois DeepSeek R1-Lite-Preview cible l’avance d’OpenAI en matière de raisonnement automatisé p>
Résultats de l’analyse comparative
Les modèles DeepSeek-VL2, y compris les variantes Tiny, Small et standard, ont excellé dans les analyses comparatives critiques pour questions-réponses générales (AQ) et tâches multimodales liées aux mathématiques.
DeepSeek-VL2-Small, avec ses 2,8 milliards de paramètres activés, a atteint un score MMStar de 57,0 et a surpassé des modèles de taille similaire comme InternVL2-2B (49,8) et Qwen2-VL-2B (48,0). Il rivalisait également de près avec des modèles beaucoup plus grands, tels que le 4,1B InternVL2-4B (54,3) et le 8,3B Qwen2-VL-7B (60,7), démontrant ainsi son efficacité compétitive.
Sur le test AI2D pour le visuel raisonnement, DeepSeek-VL2-Small a obtenu un score de 80,0, surpassant InternVL2-2B (74,1) et MM 1,5-3B (non rapporté). Même face à des concurrents à plus grande échelle comme InternVL2-4B (78,9) et MiniCPM-V2.6 (82,1), DeepSeek-VL2 a démontré d’excellents résultats avec moins de paramètres activés.
 Source: DeepSeek
Source: DeepSeek
Le produit phare Le modèle DeepSeek-VL2 (4,5 milliards de paramètres activés) a fourni des résultats exceptionnels, avec un score de 61,3 sur MMStar et de 81,4 sur AI2D. Il a surpassé des concurrents tels que Molmo-7B-O (paramètres activés 7,6B, 39,3) et MiniCPM-V2.6 (8,0B, 57,5), validant ainsi sa supériorité technique.
Excellence en OCR-Repères associés
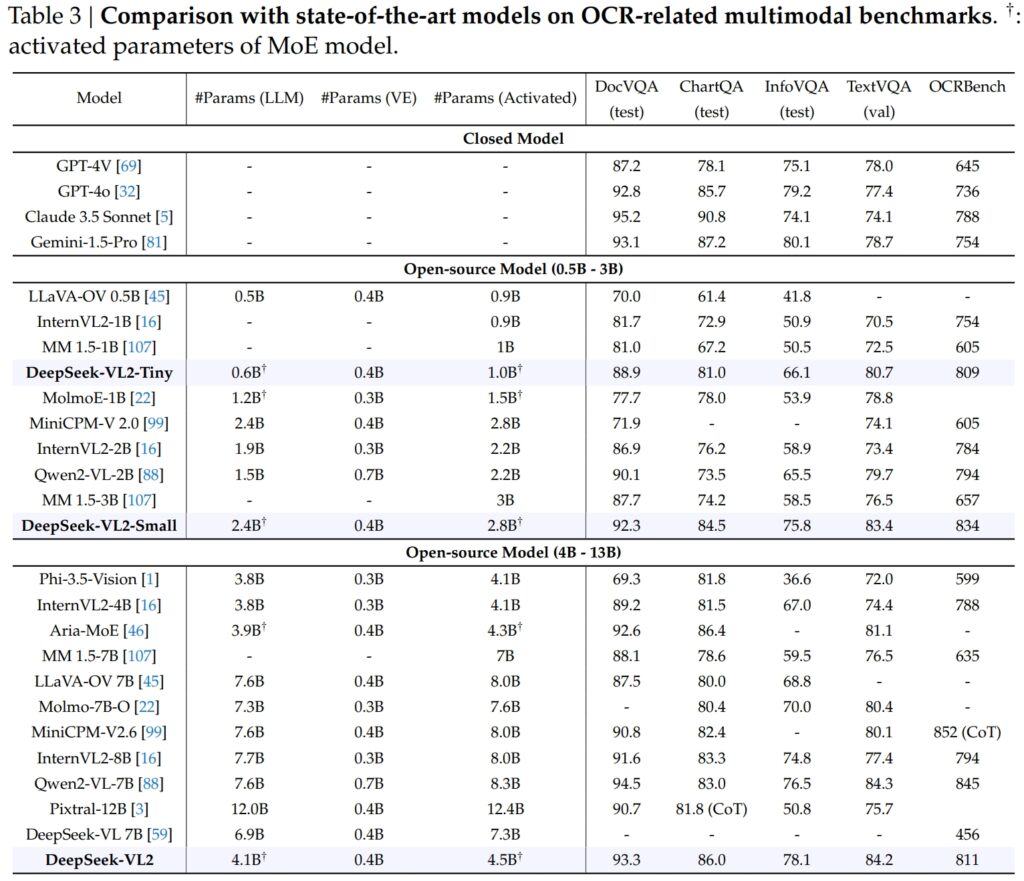
Les capacités de DeepSeek-VL2 s’étendent en grande partie à l’OCR (reconnaissance optique de caractères) tâches, un domaine crucial pour la compréhension des documents et l’extraction de textes en IA. Dans le test DocVQA, le DeepSeek-VL2-Small a atteint une précision impressionnante de 92,3 %, surpassant tous les autres modèles open source d’échelle similaire, notamment InternVL2-4B (89,2 %) et MiniCPM-V2.6 (90,8 %). Sa précision était juste derrière les modèles fermés comme GPT-4o (92,8) et Claude 3.5 Sonnet (95,2).
Le modèle DeepSeek-VL2 a également mené le test ChartQA avec un score de 86,0, surpassant InternVL2-. 4B (81,5) et MiniCPM-V2.6 (82,4). Ce résultat reflète la capacité avancée de DeepSeek-VL2 à traiter des graphiques et à extraire des informations à partir de données visuelles complexes.
 Source : DeepSeek
Source : DeepSeek
Dans OCRBench, un outil hautement compétitif métrique pour la reconnaissance de texte à granularité fine, DeepSeek-VL2 a atteint 811, surclassant les 7,6B Qwen2-VL-7B (845) et MiniCPM-V2.6 (852 avec CoT), et soulignant sa force dans les tâches OCR denses.
Comparaison avec les principaux modèles de langage de vision
Lorsqu’ils sont placés aux côtés de leaders du secteur comme le GPT-4V d’OpenAI et le Gemini-1.5-Pro de Google, les modèles DeepSeek-VL2 offrent un équilibre convaincant entre performances et efficacité. Par exemple, GPT-4V a obtenu un score de 87,2 dans DocVQA, ce qui n’est que légèrement supérieur à DeepSeek-VL2 (93,3), bien que ce dernier fonctionne dans un cadre open source avec moins de paramètres activés.
Sur TextVQA, DeepSeek-VL2-Small a obtenu 83,4, surpassant considérablement les modèles open source similaires comme InternVL2-2B (73,4) et MiniCPM-V2.0 (74.1). Même le MiniCPM-V2.6 (8,0 B), beaucoup plus grand, n’a atteint que 80,4, soulignant encore davantage l’évolutivité et l’efficacité de l’architecture de DeepSeek-VL2.
Pour ChartQA, le score de 86,0 de DeepSeek-VL2 a dépassé celui de Pixtral-12B (81,8) et InternVL2-8B (83,3), démontrant sa capacité à exceller dans des domaines spécialisés tâches nécessitant une compréhension visuelle et textuelle précise.
Connexe : Mistral AI lance Pixtral 12B pour le traitement de texte et d’images
Applications en expansion : à partir de conversations fondées à la narration visuelle
Une caractéristique notable des modèles DeepSeek-VL2 est leur capacité à mener des conversations fondées, où le modèle peut identifier des objets dans des images et les intégrer dans des contextes contextuels. discussions.
Par exemple, en utilisant un jeton spécialisé, le modèle peut fournir des détails spécifiques à un objet, tels que l’emplacement et la description, pour répondre aux requêtes sur les images. Cela ouvre des possibilités d’applications dans la robotique, la réalité augmentée et les assistants numériques, où un raisonnement visuel précis est requis.
Un autre domaine d’application est la narration visuelle. DeepSeek-VL2 peut générer des récits cohérents basés sur une séquence d’images, combinant ses capacités avancées de reconnaissance visuelle et de langage.
Ceci est particulièrement utile dans des domaines tels que l’éducation, les médias et le divertissement, où la création de contenu dynamique est une priorité. Les modèles exploitent une solide compréhension multimodale pour créer des histoires détaillées et contextuellement appropriées, intégrant des éléments visuels tels que des points de repère et du texte dans le récit de manière transparente.
La capacité des modèles en matière de fondement visuel est tout aussi forte. Lors de tests impliquant des images complexes, DeepSeek-VL2 a démontré sa capacité à localiser et à décrire avec précision des objets sur la base d’invites descriptives.
Par exemple, lorsqu’on lui demande d’identifier une « voiture garée sur le côté gauche de la rue », le modèle peut identifier l’objet exact dans l’image et générer les coordonnées du cadre de délimitation pour illustrer sa réponse. Ces fonctionnalités permettent il s’applique parfaitement aux systèmes autonomes et à la surveillance, où une analyse visuelle détaillée est essentielle.
Accessibilité et évolutivité open source
La décision de DeepSeek AI de publier DeepSeek-VL2 comme L’open source contraste fortement avec la nature propriétaire de concurrents comme GPT-4V d’OpenAI et Gemini-Exp de Google, qui sont des systèmes fermés conçus pour un accès public limité.
Selon la documentation technique, « En créant notre pré-des modèles formés et du code accessibles au public, nous visons à accélérer les progrès dans la modélisation du langage vision et à promouvoir l’innovation collaborative au sein de la communauté de recherche.
L’évolutivité de DeepSeek-VL2 renforce encore leur attrait. Les modèles sont optimisés pour le déploiement sur une large gamme de configurations matérielles, depuis les GPU uniques avec 10 Go de mémoire jusqu’aux configurations multi-GPU capables de gérer des charges de travail à grande échelle.
Cette flexibilité garantit que DeepSeek-VL2 peut être utilisé par des organisations de toutes tailles, des startups aux grandes entreprises, sans avoir besoin d’une infrastructure spécialisée.
Innovations en matière de données et Formation
L’un des principaux facteurs à l’origine du succès de DeepSeek-VL2 réside dans ses données de formation étendues et diversifiées. La phase de pré-formation comprenait des ensembles de données tels que WIT, WikiHow et OBELICS, qui fournissaient un mélange de paires image-texte entrelacées pour la généralisation.
Des données supplémentaires pour des tâches spécifiques, telles que l’OCR et la réponse visuelle aux questions, provenaient de sources telles que LaTeX OCR et PubTabNet, garantissant que les modèles pouvaient gérer des tâches générales et spécialisées avec une grande précision.
L’inclusion d’ensembles de données multilingues reflète également l’objectif d’applicabilité mondiale de DeepSeek AI. Des ensembles de données en langue chinoise comme Wanjuan ont été intégrés aux ensembles de données en anglais pour garantir que les modèles puissent fonctionner efficacement dans des environnements multilingues.
Cette approche améliore la convivialité de DeepSeek-VL2 dans les régions où les données non anglaises dominent, élargissant ainsi considérablement sa base d’utilisateurs potentiels.
La phase de mise au point supervisée a encore affiné les modèles. capacités en se concentrant sur des tâches spécifiques telles que la compréhension de l’interface graphique et l’analyse des graphiques. En combinant des ensembles de données internes avec des ressources open source de haute qualité, DeepSeek-VL2 a atteint des performances de pointe sur plusieurs benchmarks, validant l’efficacité de sa méthodologie de formation.
La conservation minutieuse de DeepSeek AI de données et un pipeline de formation innovant ont permis aux modèles VL2 d’exceller dans un large éventail de tâches tout en maintenant efficacité et évolutivité. Ces facteurs en font un ajout précieux au domaine de l’IA multimodale.
La capacité des modèles à gérer des tâches de traitement d’image complexes, telles que la mise à la terre visuelle et l’OCR dense, les rend idéales pour des secteurs comme la logistique et la sécurité. Dans le domaine de la logistique, ils peuvent automatiser le suivi des stocks en analysant les images du stock de l’entrepôt, en identifiant les articles et en intégrant les résultats dans les systèmes de gestion des stocks.
Dans le domaine de la sécurité, DeepSeek-VL2 peut aider à la surveillance en identifiant des objets ou des individus en temps réel, sur la base de requêtes descriptives, et en fournissant des informations contextuelles détaillées aux opérateurs.
DeepSeek-La capacité de conversation terrestre du VL2 offre également des possibilités en robotique et en réalité augmentée. Par exemple, un robot équipé de ce modèle pourrait interpréter visuellement son environnement, répondre aux requêtes humaines sur des objets spécifiques et effectuer des actions basées sur sa compréhension de l’entrée visuelle.
De même, les appareils de réalité augmentée peuvent exploiter les fonctionnalités visuelles et de narration du modèle pour offrir des expériences interactives et immersives, telles que des visites guidées ou des superpositions contextuelles dans des environnements en temps réel.
Défis et perspectives d’avenir
Malgré ses nombreux atouts, DeepSeek-VL2 est confronté à plusieurs défis. L’une des principales limitations est la taille de sa fenêtre contextuelle, qui limite actuellement le nombre d’images pouvant être traitées au sein d’une seule interaction.
L’extension de cette fenêtre contextuelle dans les itérations futures permettrait des interactions multi-images plus riches et améliorerait l’utilité du modèle dans les tâches nécessitant une compréhension contextuelle plus large.
Un autre défi réside dans la gestion des domaine ou des entrées visuelles de faible qualité, telles que des images floues ou des objets non présents dans ses données d’entraînement. Bien que DeepSeek-VL2 ait démontré des capacités de généralisation remarquables, l’amélioration de la robustesse face à de telles entrées augmentera encore son applicabilité dans des scénarios du monde réel.
Pour l’avenir, DeepSeek AI prévoit de renforcer les capacités de raisonnement de ses modèles, leur permettant de gérer des tâches multimodales de plus en plus complexes. En intégrant des pipelines de formation améliorés et en élargissant les ensembles de données pour couvrir des scénarios plus diversifiés, les futures versions de DeepSeek-VL2 pourraient établir de nouvelles références en matière de performances de l’IA en langage visuel.
