Des chercheurs de l’Université Jiao Tong de Shanghai et de l’Université de Wuhan ont développé un nouveau modèle d’IA nommé Streaming Infinite Retentive Large Language Model (SirLLM) pour remédier aux limites des grands modèles de langage (LLM) actuels dans la gestion de longueurs d’entrée infinies et le maintien de capacités de mémoire robustes. SirLLM vise à améliorer la rétention de mémoire et l’adaptabilité des LLM sans avoir besoin de réglages précis.
SirLLM améliore la rétention de mémoire dans les modèles d’IA
Les LLM actuels, malgré leur croissance rapide et leur application dans diverses tâches de traitement du langage naturel (NLP), telles que les chatbots et les assistants d’écriture, se heurtent à des longueurs d’entrée et des capacités de mémoire illimitées. Des techniques telles que l’attention par fenêtre coulissante et StreamLLM ont été utilisées pour étendre la longueur des entrées, mais elles sont confrontées à des problèmes tels que la perte de mémoire et la perte d’attention. Ces méthodes impliquent souvent d’affiner le mécanisme d’attention pour améliorer la longueur du contexte d’entrée, mais les problèmes de préservation et d’oubli des jetons persistent.
SirLLM introduit une nouvelle méthode en utilisant la métrique Token Entropy et un mécanisme de dégradation de la mémoire pour filtrer. phrases clés, améliorant ainsi la mémoire adaptable et à long terme du modèle. Le framework gère à la fois un cache clé-valeur (KV) et un cache d’entropie de jeton. Lorsque le nombre de jetons dans le cache KV dépasse la longueur de pré-entraînement, SirLLM calcule l’entropie de chaque jeton et sélectionne ceux avec une entropie plus élevée pour économiser de l’espace. Cette méthode garantit que les jetons de clé, qui contiennent plus d’informations, sont préservés.
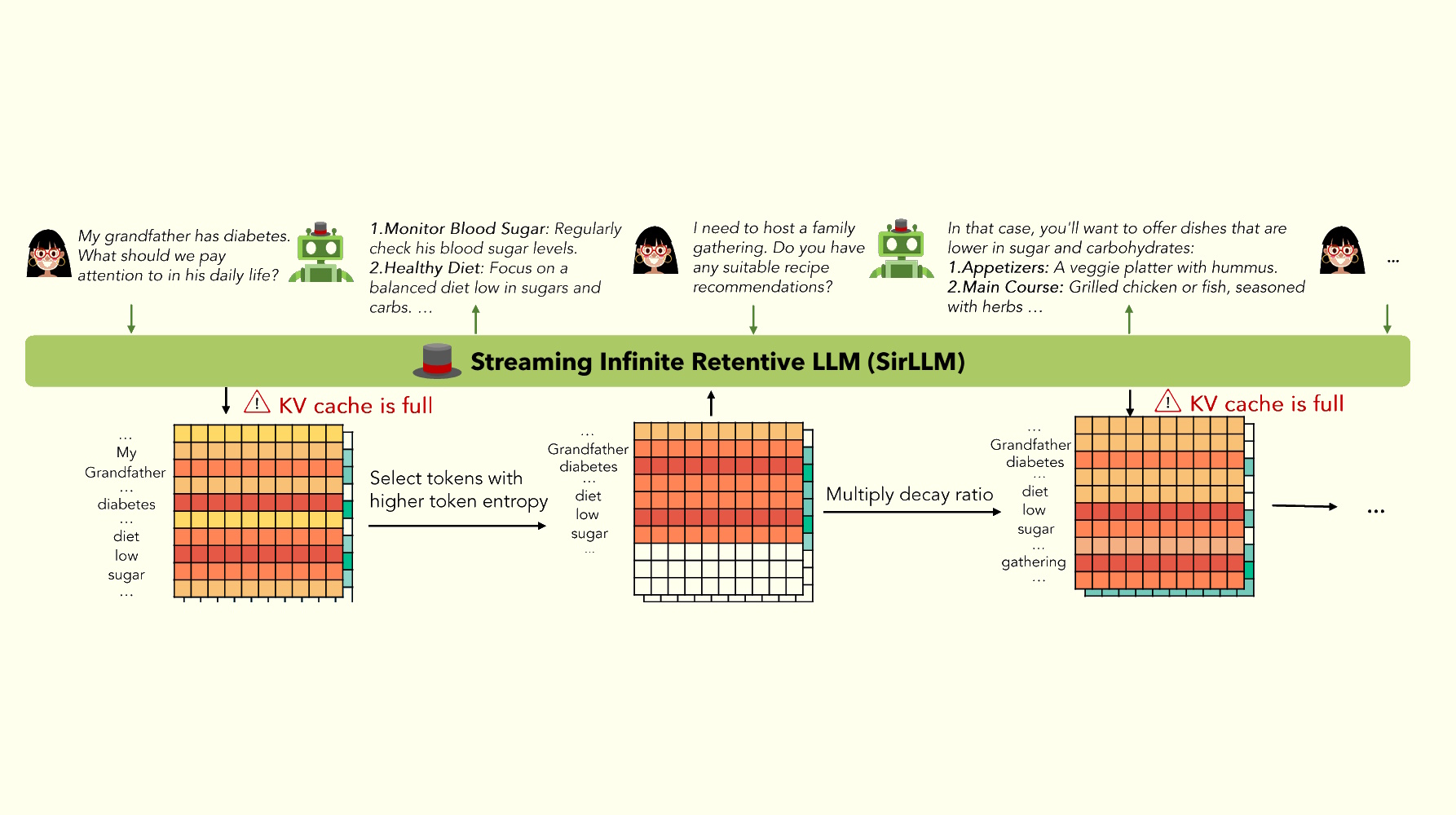
Pour remédier à la rigidité de la mémoire causée par la préservation des jetons basée uniquement sur l’entropie, SirLLM intègre un taux de désintégration qui permet au modèle d’oublier les informations clés plus anciennes après chaque cycle de dialogue. Cet ajustement améliore la flexibilité du modèle et l’expérience utilisateur.
Validation expérimentale
L’efficacité de SirLLM a été évaluée à travers trois tâches : DailyDialog, Grocery Shopping et l’ensemble de données Rock-Paper-Scissors. L’analyse de l’ensemble de données Rock-Paper-Scissors démontre la surperformance constante de SirLLM par rapport au StreamLLM de référence. Le modèle montre une amélioration constante des taux de victoire contre des joueurs ayant des préférences diverses, maintenant des performances élevées dans tous les modèles évalués. Le mécanisme de désintégration intégré contribue de manière significative au maintien de performances équilibrées sur plusieurs tours, mettant en évidence la capacité de SirLLM à s’adapter et à rappeler les mouvements précédents, ce qui est essentiel au succès des interactions prolongées.
Les chercheurs ont publié leurs résultats, validant la robustesse de SirLLM. et polyvalence dans la gestion de la rétention de dialogues longs sans nécessiter un réglage fin du modèle. L’étude positionne SirLLM comme un atout précieux pour les explorations et applications futures dans le traitement du langage naturel. Pour plus de détails, vous pouvez consulter le document de recherche disponible sur arXiv.