NVIDIA a lancé NV-Embed sur Hugging Face, un modèle d’intégration avancé qui a atteint les premières positions dans le Massive Text Embedding Benchmark (MTEB). Ce modèle, basé sur une architecture de modèle de langage étendu (LLM), démontre des améliorations significatives dans diverses tâches grâce à sa conception et ses méthodes de formation uniques.
Mesures de performance et réalisations
NV-Embed a excellé dans plusieurs tâches, notamment la récupération, le reclassement et la classification, obtenant ainsi le classement général le plus élevé du MTEB. Les mesures de performances notables incluent :
AmazonCounterfactualClassification (en) : une précision de 95,119 %, une précision moyenne (AP) de 79,215 et un score F1 de 92,456. AmazonPolarityClassification : précision de 97,143 %, score AP de 95,286 et score F1 de 97,143. AmazonReviewsClassification (fr) : précision de 55,466 % et score F1 de 52,702. ArguAna : MAP@1 sur 44,879, MAP@10 sur 60,146, MAP@100 sur 60,533, MRR@1 sur 0,000, Precision@1 sur 44,879 et Recall@1 sur 44,879. ArxivClustering : V-Mesure de 53,764 (P2P) et 49,589 (S2S). Posez des questions à UbuntuDup : MAP de 67,499 et MRR de 80,778.
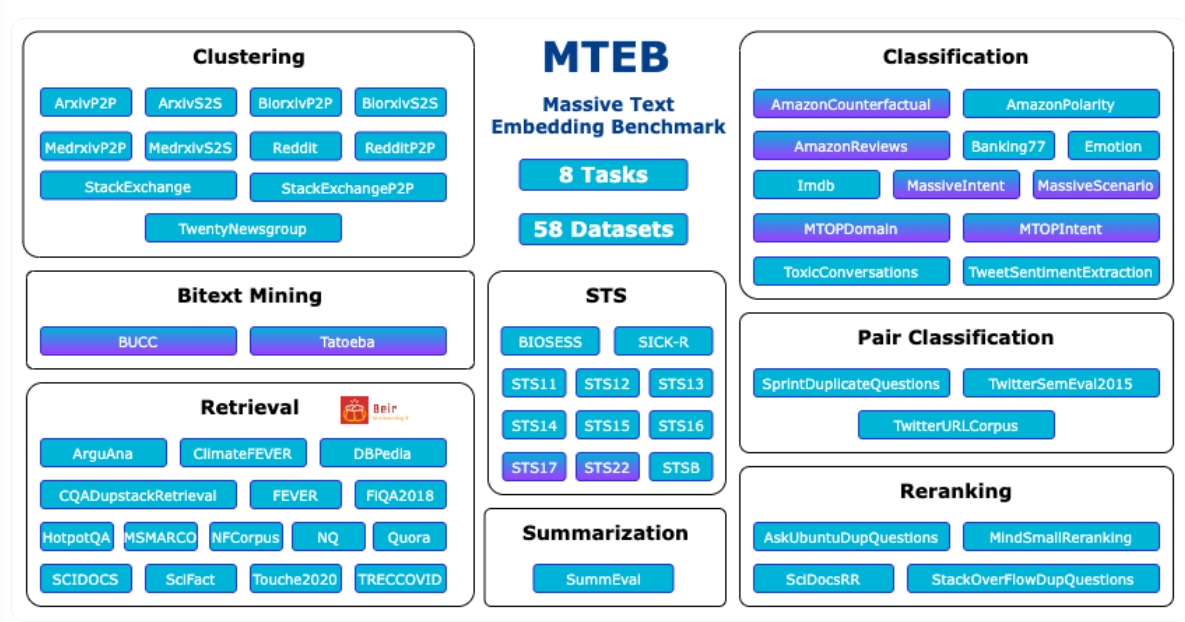
Le Massive Text Embedding Benchmark (MTEB) a été développé pour répondre aux limites des évaluations traditionnelles d’intégration de texte, qui se concentrent souvent sur un ensemble restreint d’ensembles de données et de tâches. MTEB propose un cadre d’analyse comparative complet qui comprend huit tâches d’intégration dans 58 ensembles de données et 112 langues, ce qui en fait l’un des tests d’évaluation les plus complets disponibles.
Ce cadre met en évidence le large éventail d’applications pour l’intégration de langage naturel, du clustering et représentation du sujet dans les systèmes de recherche et l’exploration de texte.
Innovations architecturales et de formation
Le succès du modèle NV-Embed est en grande partie dû à ses innovations architecturales et à ses procédures de formation avancées. Bien que NVIDIA n’ait pas divulgué de détails spécifiques sur la configuration du modèle, les dimensions de sortie et le nombre de paramètres, l’architecture basée sur LLM joue un rôle crucial dans son efficacité.
Les performances exceptionnelles du modèle dans diverses tâches suggèrent l’utilisation de technologies sophistiquées. architectures de réseaux neuronaux et méthodologies de formation avancées qui exploitent des ensembles de données à grande échelle.
Défis et perspectives du MTEB
L’évaluation de NV-Embed dans le cadre du MTEB a révélé qu’aucune méthode d’intégration de texte ne surpasse systématiquement les autres dans toutes les tâches, indiquant l’absence de solution universelle pour l’intégration de texte. Le benchmark a également mis en évidence l’infaisabilité de l’utilisation de modèles de langage génératifs ou d’encodeurs croisés pour certaines applications en raison de leurs exigences informatiques étendues.
Les modèles d’intégration de texte actuels sont souvent évalués de manière contrainte, en se concentrant sur des tâches telles que similarité textuelle sémantique (STS) et classification, mais n’a pas été testée de manière approfondie pour la transférabilité à d’autres tâches telles que la recherche ou le clustering.
Impact du prétraitement et des paramètres d’hyperparamètres
Les paramètres de prétraitement et d’hyperparamètres peuvent avoir un impact significatif sur les performances du modèle, obscurcissant potentiellement les véritables améliorations des performances.
MTEB vise à clarifier les performances des modèles dans une variété de tâches d’intégration, en offrant une vue complète de l’état des modèles d’intégration de texte, y compris les modèles open source et ceux accessibles via des API.
Diverses performances des modèles
L’évaluation a également révélé que différents modèles excellent dans différentes tâches. Par exemple, les modèles ST5 fonctionnent bien dans les tâches de classification, tandis que les MPNet rivalise efficacement avec des modèles plus grands comme ST5-XXL dans les tâches de clustering.
GTR-XL et GTR-XXL est en tête des tâches de classification par paires, et les modèles MPNet et MiniLM affichent de solides performances dans les tâches de reclassement. SGPT-5.8B-msmarco excelle dans les tâches de récupération, et LaBSE domine l’exploration de bitextes, avec des performances variables selon les langues.
Licences et accessibilité
NV-Embed est disponible sous la licence internationale Creative Commons Attribution-NonCommercial 4.0 (cc-by-nc-4.0). Ce choix de licence reflète l’engagement de NVIDIA à rendre ses travaux accessibles à la communauté des chercheurs tout en restreignant leur utilisation commerciale. La disponibilité du modèle sur Hugging Face améliore encore son accessibilité pour les chercheurs et les développeurs.


