DeepSeek AI on julkaissut DeepSeek-VL2:n, Vision-Language Models (VLM)-perheen, joka on nyt saatavilla avoimen lähdekoodin lisensseillä. Sarja esittelee kolme versiota – Tiny, Small ja standardin VL2 – joiden aktivoitujen parametrien koot ovat vastaavasti 1,0 miljardia, 2,8 miljardia ja 4,5 miljardia.
Malleihin pääsee käsiksi GitHubin ja Halaavat kasvot. He lupaavat edistää keskeisiä tekoälysovelluksia, mukaan lukien visuaalinen kysymysvastaus (VQA), optinen merkintunnistus (OCR) ja korkearesoluutioinen asiakirja-ja kaavioanalyysi.
Virallisen GitHub-dokumentaation mukaan”DeepSeek-VL2 osoittaa ylivertaisia ominaisuuksia erilaisissa tehtävissä, mukaan lukien, mutta ei rajoittuen, visuaalinen kysymyksiin vastaaminen, asiakirjojen/taulukoiden/kaavioiden ymmärtäminen ja visuaalinen maadoitus.”
Tämän julkaisun ajoitus asettaa DeepSeek AI:n suoraan kilpailemaan suurten toimijoiden, kuten OpenAI:n ja Googlen, kanssa, jotka molemmat hallitsevat vision-kielellä olevaa tekoälyä. mallit, kuten GPT-4V ja Gemini-Exp.
DeepSeek painottaa avoimen lähdekoodin yhteistyötä yhdistettynä VL2-perheen edistyneisiin teknisiin ominaisuuksiin, joten se on ilmainen vaihtoehto tutkijoille.
Dynaaminen laatoitus: Advancing High-Resoluutiokuvankäsittely
Yksi DeepSeek-VL2:n merkittävimmistä edistysaskeleista on sen dynaaminen laatoitusnäkökoodaus strategia, joka mullistaa tavan, jolla mallit käsittelevät korkean resoluution visuaalista dataa.
Toisin kuin perinteiset kiinteän resoluution lähestymistavat, dynaaminen laatoitus jakaa kuvat pienempiin, joustaviin ruutuihin, jotka mukautuvat erilaisiin kuvasuhteisiin. Tämä menetelmä varmistaa yksityiskohtaisen ominaisuuksien poimimisen säilyttäen samalla laskennan tehokkuuden.
DeepSeek kuvailee tätä GitHub-tietovarastossaan tapana”prosessoida tehokkaasti korkearesoluutioisia kuvia vaihtelevilla kuvasuhteilla välttäen laskennallista skaalausta, joka tyypillisesti liittyy kasvaviin kuvien resoluutioihin.”
Tämä ominaisuus mahdollistaa DeepSeek-VL2:n erinomaisen suorituskyvyn sovelluksissa, kuten visuaalisessa maadoituksessa, jossa korkea tarkkuus on välttämätöntä monimutkaisten kuvien objektien tunnistamisessa ja tiheässä OCR:ssä. tehtäviä, jotka vaativat tekstin käsittelyä yksityiskohtaisissa asiakirjoissa tai kaavioissa
Sopeutumalla dynaamisesti erilaisiin kuvien resoluutioihin ja kuvasuhteisiin, mallit ylittävät staattisten koodausmenetelmien rajoitukset ja tekevät niistä sopivia käyttötapauksiin, jotka vaativat sekä joustavuutta. ja tarkkuus.
Asiantuntijoiden yhdistelmä ja monipään piilevä huomio tehokkuuden saavuttamiseksi
DeepSeek-VL2:n suorituskyvyn parannuksia tukee edelleen Mixture-of-Experts (MoE)-kehyksen ja Multi-head Latent Attention (MLA)-mekanismin integrointi
MoE-arkkitehtuuri aktivoi valikoivasti tietyt osajoukot , tai”asiantuntijoita”mallin sisällä hoitaakseen tehtäviä tehokkaammin. Tämä suunnittelu vähentää laskennallista lisärasitusta, koska se ottaa käyttöön vain tarvittavat parametrit jokaiselle toiminnalle. Tämä ominaisuus on erityisen hyödyllinen resurssirajoitteisissa ympäristöissä.
MLA-mekanismi täydentää MoE-kehystä pakkaamalla avainarvovälimuistin piileväksi. vektorit päättelyn aikana. Tämä optimointi minimoi muistin käytön ja lisää käsittelynopeuksia mallin tarkkuudesta tinkimättä.
Teknisen dokumentaation mukaan”MoE-arkkitehtuuri yhdistettynä MLA:han mahdollistaa DeepSeek-VL2:n kilpailukykyisen tai paremman suorituskyvyn kuin tiheät mallit, joissa on vähemmän aktivoituja parametreja.”
Kolmivaiheinen koulutusputki
DeepSeek-VL2:n kehittämiseen sisältyi tiukka kolmivaiheinen koulutusputkisto, joka oli suunniteltu optimoimaan mallin multimodaaliset ominaisuudet. Ensimmäinen vaihe keskittyi näön ja kielen kohdistukseen, jossa mallit opetettiin integroimaan visuaalisia ominaisuuksia tekstitietoihin. Alkuperäinen kohdistus Toiseen vaiheeseen sisältyi visiokielen esikoulutus, joka sisälsi monenlaisia tietojoukkoja, mukaan lukien WIT, WikiHow ja. monikieliset OCR-tiedot mallin yleistyskyvyn parantamiseksi useilla aloilla. Lopuksi kolmas vaihe koostui valvotusta hienosäädöstä (SFT), jossa tehtäväkohtaisia tietojoukkoja käytettiin mallin suorituskyvyn parantamiseen sellaisilla alueilla kuin visuaalinen maadoitus, graafinen käyttöliittymä. (GUI) ymmärtäminen ja tiivis tekstitys.
Näiden koulutusvaiheiden ansiosta DeepSeek-VL2 pystyi rakentamaan vankan perustan multimodaaliselle ymmärtämiselle samalla mahdollistaa mallien mukautumisen erikoistehtäviin. Monikielisten tietojoukkojen sisällyttäminen paransi mallien soveltuvuutta maailmanlaajuisessa tutkimuksessa ja teollisessa ympäristössä.
Aiheeseen liittyvä: Kiinalainen DeepSeek R1-Lite-Preview-malli kohdistaa OpenAI:n johtoaseman automatisoidussa päättelyssä
p>
Vertailutulokset
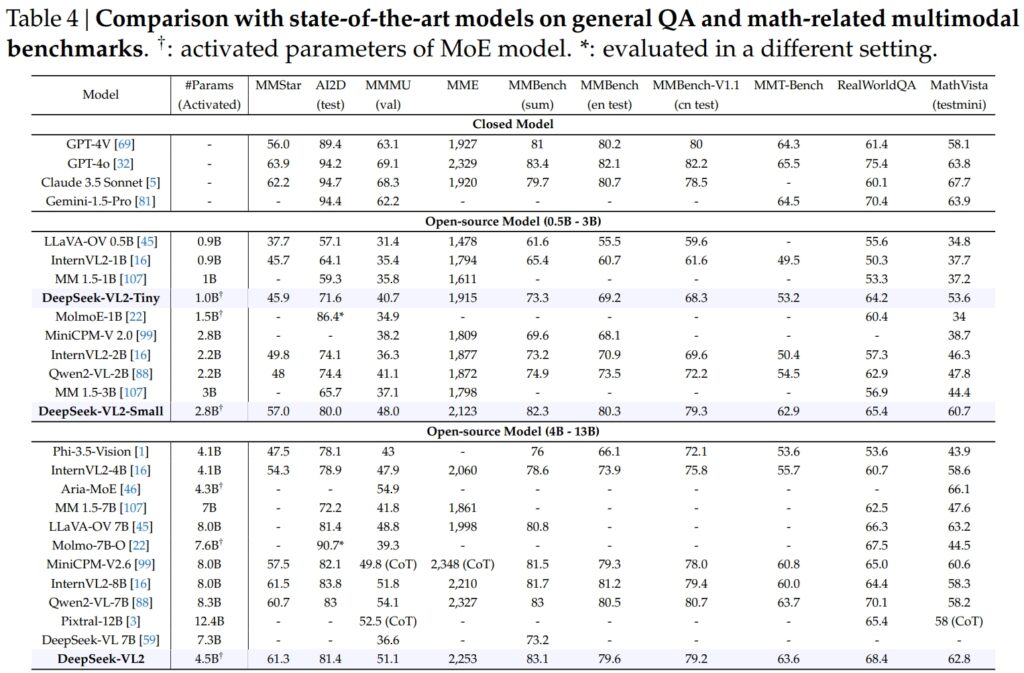
DeepSeek-VL2-mallit, mukaan lukien Tiny, Small ja standardimuunnelmat, jotka ovat erinomaiset kriittisissä vertailuissa yleisten kysymysvastausten (QA) ja matematiikkaan liittyvien multimodaalisten tehtävien osalta.
DeepSeek-VL2-Small, jossa on 2,8 miljardia aktivoitua parametria, saavutti MMStar-pistemäärän 57,0 ja ylitti samankokoiset mallit, kuten InternVL2-2B (49,8) ja Qwen2-VL-2B (48,0). Se kilpaili tiiviisti myös paljon suurempia malleja, kuten 4.1B InternVL2-4B (54.3) ja 8.3B Qwen2-VL-7B (60.7), mikä osoitti kilpailukykynsä tehokkuutta.
Visuaalisen AI2D-testissä päättelyn perusteella DeepSeek-VL2-Small saavutti pistemäärän 80,0, ohittaen InternVL2-2B:n (74,1) ja MM 1.5-3B (ei raportoitu). Jopa suurempia kilpailijoita, kuten InternVL2-4B (78.9) ja MiniCPM-V2.6 (82.1) vastaan, DeepSeek-VL2 osoitti vahvoja tuloksia vähemmillä aktivoiduilla parametreilla.
 Lähde: DeepSeek
Lähde: DeepSeek
Lippulaiva DeepSeek-VL2-malli (4,5 miljardia aktivoitua parametria) tuotti poikkeuksellisia tuloksia, pisteytyksen 61.3 MMStarilla ja 81.4 AI2D:llä. Se ylitti kilpailijat, kuten Molmo-7B-O (7.6B aktivoidut parametrit, 39.3) ja MiniCPM-V2.6 (8.0B, 57.5), mikä vahvisti entisestään sen teknistä ylivoimaisuutta.
Erinomainen tekstintunnistus-Aiheeseen liittyvät vertailuarvot
DeepSeek-VL2:n ominaisuudet ulottuvat näkyvästi tekstintunnistusohjelmaan (optinen merkintunnistus) liittyvät tehtävät, tärkeä alue asiakirjojen ymmärtämisessä ja tekstin poimimisessa tekoälyssä. DocVQA-testissä DeepSeek-VL2-Small saavutti vaikuttavan 92,3 prosentin tarkkuuden, mikä ylitti kaikki muut saman mittakaavan avoimen lähdekoodin mallit, mukaan lukien InternVL2-4B (89,2 %) ja MiniCPM-V2.6 (90,8 %). Sen tarkkuus jäi vain suljetuista malleista, kuten GPT-4o (92,8) ja Claude 3.5 Sonnet (95,2).
DeepSeek-VL2-malli johti myös ChartQA-testissä pistemäärällä 86,0, mikä ylitti InternVL2-4B (81,5) ja MiniCPM-V2,6 (82,4). Tämä tulos kuvastaa DeepSeek-VL2:n edistynyttä kykyä käsitellä kaavioita ja poimia näkemyksiä monimutkaisista visuaalisista tiedoista.
Lähde: DeepSeek
In OCRBench, erittäin kilpailukykyinen mittari hienorakeisen tekstin tunnistukseen, DeepSeek-VL2 saavutti 811, ylittää 7.6B Qwen2-VL-7B (845) ja MiniCPM-V2.6 (852 CoT) ja korostaa sen vahvuutta tiheissä OCR-tehtävissä.
Vertailu johtaviin Vision-Language-malleihin
Kun sijoitetaan alan johtajien, kuten OpenAI:n GPT-4V:n ja Googlen rinnalle Gemini-1.5-Pro-, DeepSeek-VL2-mallit tarjoavat vakuuttavan suorituskyvyn ja tehokkuuden tasapainon. Esimerkiksi GPT-4V sai DocVQA:ssa pisteet 87,2, mikä on vain hieman DeepSeek-VL2:ta (93,3) edellä, vaikka jälkimmäinen toimii avoimen lähdekoodin kehyksessä, jossa on vähemmän aktivoituja parametreja.
TextVQA:ssa DeepSeek-VL2-Small saavutti 83,4, mikä ylitti merkittävästi samanlaiset avoimen lähdekoodin mallit, kuten InternVL2-2B (73,4) ja MiniCPM-V2.0 (74.1). Jopa paljon suurempi MiniCPM-V2.6 (8.0B) saavutti vain 80,4, mikä korostaa entisestään DeepSeek-VL2:n arkkitehtuurin skaalautuvuutta ja tehokkuutta.
ChartQA:n osalta DeepSeek-VL2:n pistemäärä 86,0 ylitti Pixtral-12B (81.8) ja InternVL2-8B (83.3), mikä osoittaa sen kykyä loistaa erikoistehtävissä, jotka vaativat tarkkaa visuaalista tekstin ymmärtämistä.
Aiheeseen liittyvä: Mistral AI esittelee Pixtral 12B:n tekstin ja kuvankäsittelyyn
Laajentuvat sovellukset: Perustetuista keskusteluista visuaaliseen tarinankerrontaan
Yksi DeepSeek-VL2-mallien merkittävä ominaisuus on niiden kyky käydä maadoitettuja keskusteluja, joissa malli tunnistaa kuvissa olevat kohteet ja integroi ne kontekstuaalisiin keskusteluihin.
Esimerkiksi erikoistunnuksia käyttämällä malli voi tarjota kohdekohtaisia tietoja, kuten sijainnin ja kuvauksen, vastatakseen kuvia koskeviin kyselyihin. Tämä avaa mahdollisuuksia robotiikan, lisätyn todellisuuden ja digitaalisten assistenttien sovelluksille, joissa vaaditaan tarkkaa visuaalista päättelyä.
Toinen sovellusalue on visuaalinen tarinankerronta. DeepSeek-VL2 voi luoda yhtenäisiä kertomuksia kuvasarjan perusteella yhdistäen edistyneen visuaalisen tunnistuksen ja kieliominaisuudet.
Tämä on erityisen arvokasta koulutuksen, median ja viihteen kaltaisilla aloilla, joissa dynaaminen sisällöntuotanto on etusijalla. Mallit hyödyntävät vahvaa multimodaalista ymmärrystä luodakseen yksityiskohtaisia ja asiayhteyteen sopivia tarinoita ja integroivat visuaalisia elementtejä, kuten maamerkkejä ja tekstiä, saumattomasti kerrokseen.
Malleilla on yhtä vahvaa visuaalista pohjaa. Monimutkaisia kuvia sisältävissä testeissä DeepSeek-VL2 on osoittanut kykynsä paikantaa ja kuvata kohteita tarkasti kuvailevien kehotteiden perusteella.
Esimerkiksi kun mallia pyydetään tunnistamaan”kadun vasemmalle puolelle pysäköity auto”, malli voi paikantaa tarkan kohteen kuvassa ja luoda rajauslaatikon koordinaatit havainnollistamaan sen vastausta. se soveltuu erittäin hyvin autonomisiin järjestelmiin ja valvontaan, joissa yksityiskohtainen visuaalinen analyysi on kriittinen.
Avoimen lähdekoodin käytettävyys ja skaalautuvuus
DeepSeek AI:n päätös julkaista DeepSeek-VL2 avoimena lähdekoodina eroaa jyrkästi kilpailijoiden patentoidusta luonteesta, kuten OpenAI:n GPT-4V ja Googlen Gemini-Exp, jotka ovat suljettuja järjestelmiä, jotka on suunniteltu rajoitettua julkista pääsyä varten.
Teknisen dokumentaation mukaan”Asettamalla valmiiksi koulutetut mallimme ja koodimme julkisesti saataville pyrimme nopeuttamaan visio-kielimallinnuksen edistymistä ja edistämään yhteistyöinnovaatioita koko tutkimusyhteisössä.”
DeepSeek-VL2:n skaalautuvuus parantaa entisestään niiden vetovoimaa. Mallit on optimoitu käytettäviksi monenlaisissa laitteistokokoonpanoissa yksittäisistä 10 Gt:n muistilla varustetuista GPU-asennuksista usean GPU:n asetuksiin, jotka pystyvät käsittelemään suuria työkuormia.
Tämä joustavuus varmistaa, että DeepSeek-VL2:ta voivat käyttää kaikenkokoiset organisaatiot startupeista suuriin yrityksiin ilman erityistä infrastruktuuria.
Innovaatioita datassa ja Harjoittelu
Tärkein DeepSeek-VL2:n menestyksen taustatekijä on sen laaja ja monipuolinen harjoitustieto. Esiopetusvaihe sisälsi tietojoukkoja, kuten WIT, WikiHow ja OBELICS, jotka tarjosivat yhdistelmän lomitettuja kuva-tekstipareja yleistämistä varten.
Lisätietoja tiettyjä tehtäviä varten, kuten tekstintunnistusta ja visuaalista kysymysvastausta varten, saatiin lähteistä, kuten LaTeX OCR ja PubTabNet, mikä varmisti, että mallit pystyivät käsittelemään sekä yleisiä että erikoistehtäviä erittäin tarkasti.
Monikielisten tietojoukkojen sisällyttäminen heijastelee myös DeepSeek AI:n maailmanlaajuista sovellettavuutta. Kiinankieliset tietojoukot, kuten Wanjuan, integroitiin englanninkielisten tietojoukkojen rinnalle, jotta mallit voisivat toimia tehokkaasti monikielisissä ympäristöissä.
Tämä lähestymistapa parantaa DeepSeek-VL2:n käytettävyyttä alueilla, joilla ei-englanninkielinen data hallitsee, mikä laajentaa sen potentiaalista käyttäjäkuntaa merkittävästi.
Valvottu hienosäätövaihe jalosti malleja entisestään. ominaisuuksia keskittymällä tiettyihin tehtäviin, kuten graafisen käyttöliittymän ymmärtämiseen ja kaavioanalyysiin. Yhdistämällä talon sisäiset tietojoukot korkealaatuisiin avoimen lähdekoodin resursseihin DeepSeek-VL2 saavutti huipputason suorituskyvyn useissa vertailuissa ja vahvisti koulutusmenetelmiensä tehokkuuden.
DeepSeek AI:n huolellinen kuratointi Tietojen ja innovatiivisten koulutusputkien ansiosta VL2-mallit ovat menestyneet useissa eri tehtävissä säilyttäen samalla tehokkuuden ja skaalautuvuuden. Nämä tekijät tekevät niistä arvokkaan lisäyksen multimodaalisen tekoälyn alaan.
Malleiden kyky käsitellä monimutkaisia kuvankäsittelytehtäviä, kuten visuaalinen maadoitus ja tiheä OCR, tekevät niistä ihanteellisia sellaisille aloille kuin logistiikka ja turvallisuus. Logistiikassa he voivat automatisoida varaston seurannan analysoimalla kuvia varastokalustosta, tunnistamalla nimikkeitä ja integroimalla havainnot varastonhallintajärjestelmiin.
Turvallisuusalueella DeepSeek-VL2 voi auttaa valvonnassa tunnistamalla kohteet tai henkilöt reaaliajassa kuvailevien kyselyjen perusteella ja tarjoamalla yksityiskohtaisia kontekstuaalisia tietoja käyttäjille.
DeepSeek-VL2:n maadoitettu keskustelukyky tarjoaa mahdollisuuksia myös robotiikassa ja lisätyssä todellisuudessa. Esimerkiksi tällä mallilla varustettu robotti voisi tulkita ympäristöään visuaalisesti, vastata ihmisten tiedusteluihin tietyistä objekteista ja suorittaa toimintoja visuaalisen syötteen ymmärtämisen perusteella.
Samaan tapaan lisätyn todellisuuden laitteet voivat hyödyntää mallin visuaalisia maadoitus-ja tarinankerrontaominaisuuksia tarjotakseen interaktiivisia, mukaansatempaavia kokemuksia, kuten opastettuja kierroksia tai kontekstuaalisia peittokuvia reaaliaikaisissa ympäristöissä.
Haasteet ja tulevaisuuden näkymät
Lukuisista vahvuuksistaan huolimatta DeepSeek-VL2 kohtaa useita haasteita. Yksi keskeinen rajoitus on sen konteksti-ikkunan koko, joka tällä hetkellä rajoittaa kuvien määrää, joita voidaan käsitellä yhdessä vuorovaikutuksessa.
Tämän kontekstiikkunan laajentaminen tulevissa iteraatioissa mahdollistaisi monipuolisemman, monikuvaisen vuorovaikutuksen ja parantaisi mallin hyödyllisyyttä tehtävissä, jotka vaativat laajempaa kontekstuaalista ymmärrystä.
Toinen haaste on ulkopuolisten kuvien käsittely. verkkotunnuksen tai huonolaatuisia visuaalisia syötteitä, kuten epäselviä kuvia tai esineitä, joita ei ole sen harjoitustiedoissa. Vaikka DeepSeek-VL2 on osoittanut merkittäviä yleistysominaisuuksia, tällaisten syötteiden kestävyyden parantaminen parantaa entisestään sen soveltuvuutta reaalimaailman skenaarioihin.
Jatkossa DeepSeek AI aikoo vahvistaa malliensa päättelykykyä, jotta ne voivat käsitellä yhä monimutkaisempia multimodaalisia tehtäviä. Integroimalla parannettuja koulutusputkia ja laajentamalla tietojoukkoja kattamaan entistä monipuolisempia skenaarioita, DeepSeek-VL2:n tulevat versiot voivat asettaa uusia vertailukohtia visiokielen tekoälyn suorituskyvylle.