Kiinalainen tekoälylaboratorio DeepSeek on esitellyt DeepSeek V3:n, seuraavan genopen-lähdekielimallinsa. Mallissa on 671 miljardia parametria, ja se käyttää niin kutsuttua Mixture-of-Experts (MoE)-arkkitehtuuria laskennan tehokkuuden ja korkean suorituskyvyn yhdistämiseksi.
DeepSeek V3:n tekniset edistysaskeleet tekevät siitä tehokkaimpien tekoälyjärjestelmien joukossa kilpailla sekä avoimen lähdekoodin kilpailijat, kuten Meta’s Llama 3.1, että patentoidut mallit, kuten OpenAI:n GPT-4o.
Julkaisu korostaa tekoälyn tärkeää hetkeä ja osoittaa, että avoimen lähdekoodin järjestelmät voivat kilpailla kalliimpien suljettujen vaihtoehtojen kanssa – ja joissain tapauksissa jopa parempia –.
Aiheeseen liittyvä:
kiinalainen DeepSeek R1-Lite-Preview-malli tähtää OpenAI:n johtoasemaan automatisoidussa päättelyssä
Alibaba Qwen julkaisee QVQ-72B-Preview-multimodaalisen päättelyn tekoälymallin
Tehokas ja innovatiivinen arkkitehtuuri
DeepSeek V3:n arkkitehtuuri yhdistää kaksi edistynyttä konseptia poikkeuksellisen tehokkuuden ja suorituskyvyn saavuttamiseksi: Multi-Head Latent Attention (MLA) ja Mixture-of-Experts (MoE).
MLA parantaa mallin kykyä käsitellä monimutkaisia syötteitä käyttämällä useita huomiopäitä keskittyäkseen datan eri puoliin ja poimiakseen rikkaan ja monipuolisen kontekstuaalin. tietoja.
MoE sitä vastoin aktivoi vain osan mallin 671 miljardista parametrista – noin 37 miljardia per tehtävä – varmistaa, että laskentaresursseja käytetään tehokkaasti tarkkuudesta tinkimättä. Yhdessä nämä mekanismit mahdollistavat DeepSeek V3:n tuottavan korkealaatuisia tuloksia ja samalla vähentäen infrastruktuurin vaatimuksia.
Korkeakseen yleiset haasteet MoE-järjestelmissä, kuten epätasainen työtaakan jakautuminen asiantuntijoiden kesken, DeepSeek esitteli apuhäviöttömän kuormituksen tasapainottava strategia. Tämä dynaaminen menetelmä jakaa tehtäviä asiantuntijaverkoston kesken, mikä säilyttää johdonmukaisuuden ja maksimoi tehtävien tarkkuuden.
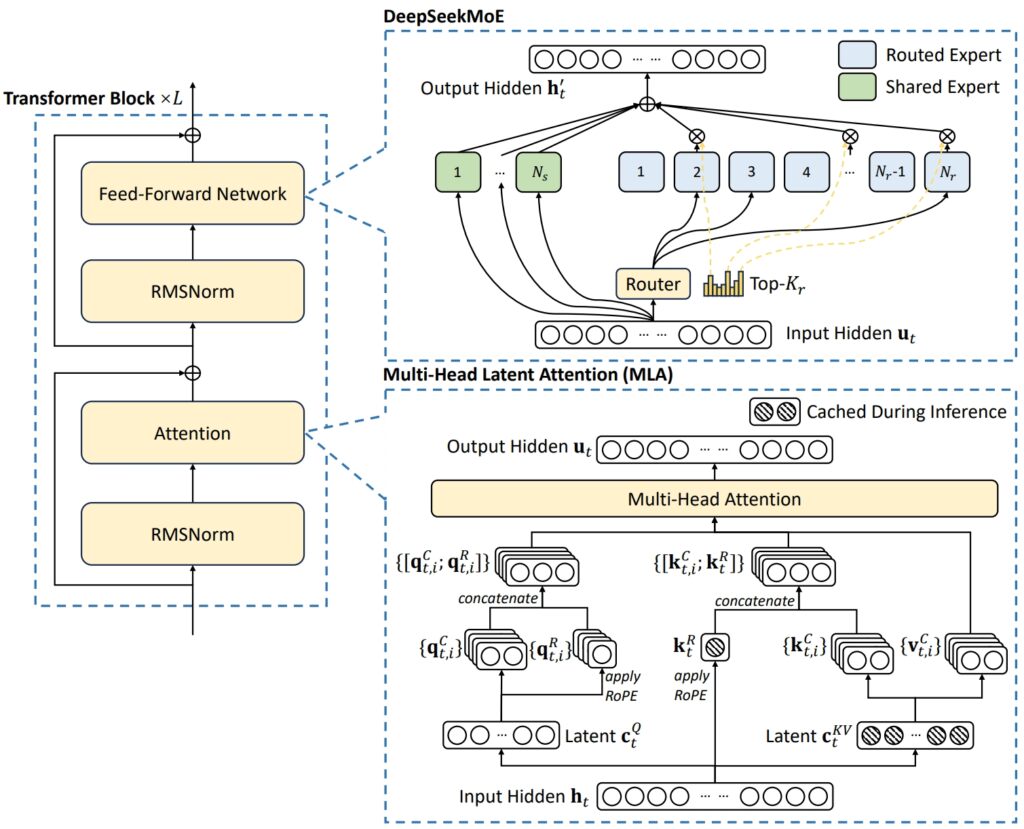 Kuva DeepSeek-V3:n perusarkkitehtuurista (Kuva: DeepSeek)
Kuva DeepSeek-V3:n perusarkkitehtuurista (Kuva: DeepSeek)
Tehokkuuden parantamiseksi entisestään DeepSeek V3 käyttää Multi-Token Prediction (MTP)-ominaisuutta, jonka avulla malli voi luoda useita tunnuksia samanaikaisesti, mikä nopeuttaa merkittävästi tekstin luomista.
Tämä ominaisuus ei ainoastaan paranna harjoittelun tehokkuutta, vaan myös sijoittaa mallin nopeampaan todellisuuteen.-maailman sovelluksia, mikä vahvistaa sen asemaa johtavana avoimen lähdekoodin tekoälyn innovaatioissa.
Benchmark Performance: A Leader in Math ja koodaus
DeepSeek V3:n benchmark-tulokset osoittavat sen poikkeukselliset kyvyt useissa eri tehtävissä ja vahvistavat sen asemaa johtavana avoimen lähdekoodin tekoälymallien joukossa.
Hyödyntämällä edistynyttä arkkitehtuuriaan ja laajaa koulutustietokantaa, malli on saavuttanut huipputason suorituskyvyn matematiikassa, koodauksessa ja monikielisissä vertailuissa, samalla kun se on tarjonnut kilpailukykyisiä tuloksia alueilla, joita perinteisesti hallitsevat suljetun lähdekoodin mallit, kuten OpenAI:n GPT.-4o ja Anthropic’s Claude 3.5 Sonnetti.
🚀 Esittelyssä DeepSeek-V3!
Suurin harppaus eteenpäin:
⚡ 60 merkkiä sekunnissa (3x nopeampi kuin V2!)
💪 Parannetut ominaisuudet
🛠 API-yhteensopivuus ennallaan
🌍 Täysin auki-lähdemallit ja-paperit🐋 1/n pic.twitter.com/p1dV9gJ2Sd
— DeepSeek (@deepseek_ai) 26. joulukuuta 2024
Matemaattinen päättely
Math-500-testi, matemaattisten ongelmanratkaisutaitojen arviointiin suunniteltu vertailuarvo, DeepSeek V3 saavutti vaikuttavan pistemäärän 90,2. Tämä pistemäärä asettaa sen kaikkien avoimen lähdekoodin kilpailijoiden edelle. Qwen 2.5 pisteytti 80 ja Llama 3.1 jäljessä 73,8. Jopa GPT-4o, suljetun lähdekoodin malli, joka on tunnettu yleisistä ominaisuuksistaan, sai hieman alhaisemman pistemäärän, 74,6. Tämä suorituskyky korostaa DeepSeek V3:n edistyneitä päättelykykyjä erityisesti laskennallisesti vaativissa tehtävissä, joissa tarkkuus ja logiikka ovat tärkeitä.
Lisäksi DeepSeek V3 loisti muissa matemaattisissa testeissä, kuten:
MGSM (Math Grade School Matematiikka): Pisteet 79,8, ohittaen Llaman 3,1 (69,9) ja Qwenin 2,5 (76,2). CMath (kiinalainen matematiikka): pisteet 90,7, parempia kuin Llama 3.1 (77,3) ja GPT-4o (84,5).
Nämä tulokset korostavat sen vahvuutta paitsi englanninkielisessä matemaattisessa päättelyssä, mutta myös kielikohtaista numeerista ongelmanratkaisua vaativissa tehtävissä.
Aiheeseen liittyvä: DeepSeek AI Open Sources VL2-sarja Vision Language-mallit
Ohjelmointi ja koodaus
DeepSeek V3 osoitti merkittävää kyvykkyys koodauksessa ja ongelmanratkaisussa. Kilpailukykyisellä ohjelmointialustalla Codeforces malli saavutti 51,6 prosenttipisteen, mikä kuvastaa sen kykyä käsitellä monimutkaisia algoritmisia tehtäviä. Tämä suorituskyky ylittää huomattavasti avoimen lähdekoodin kilpailijat, kuten Llama 3.1, joka sai vain 25,3, ja jopa haastaa Claude 3.5 Sonnetin, joka rekisteröi alhaisemman prosenttipisteen. Mallin menestystä vahvistivat myös sen korkeat pisteet koodauskohtaisissa vertailuissa:
HumanEval-Mul: Pistemäärä 82,6, parempi Qwen 2,5 (77,3) ja vastaava GPT-4o (80,5). LiveCodeBench (Pass@1): Pisteet 37,6, ennen Llama 3.1:tä (30.1) ja Claude 3.5 Sonnetia (32.8). CRUXEval-I: Pistemäärä 67,3, huomattavasti parempi kuin Qwen 2,5 (59,1) ja Llama 3,1 (58,5).
Nämä tulokset korostavat mallin soveltuvuutta ohjelmistokehityksen sovelluksiin ja reaalimaailman koodausympäristöihin, joissa tehokas ongelmanratkaisu ja koodin luominen ovat ensiarvoisen tärkeitä.