El gigante de la infraestructura web Cloudflare ha lanzado una importante actualización del reglamento de Internet de tres décadas de antigüedad para los rastreadores web.
La compañía ha introducido su”Política de señales de contenido”, una nueva extensión para archivos `robots.txt` que brinda a los propietarios de sitios web herramientas específicas para permitir o denegar el uso de su contenido para capacitación en inteligencia artificial y respuestas de búsqueda generativas.
La medida tiene como objetivo reequilibrar el poder entre los editores. y empresas de inteligencia artificial, abordando preocupaciones generalizadas sobre la extracción de datos no compensada que amenaza el modelo económico de la web abierta.
Cloudflare ya ha implementado el nuevo estándar en más de 3,8 millones de dominios. lo que indica un cambio significativo en la batalla en curso sobre los datos de IA.
Esta iniciativa confronta directamente las limitaciones del Protocolo de exclusión de robots original. Propuesto por primera vez en 1994, `robots.txt` fue diseñado para evitar la sobrecarga del servidor indicando a los rastreadores qué páginas evitar.
Era una herramienta para gestionar el acceso, no un mecanismo para dictar cómo se podía utilizar el contenido extraído después del hecho.
Un estándar envejecido en un mundo impulsado por la IA
El auge de la IA generativa ha expuesto este aspecto fundamental brecha. Las empresas de IA necesitan grandes cantidades de datos para entrenar sus modelos, y la web abierta se ha convertido en su fuente principal.
Esto ha creado un clásico”problema de aprovechamiento gratuito”, en el que los gigantes tecnológicos crean productos valiosos utilizando el contenido de los editores sin proporcionar el tráfico de referencia o la compensación que tradicionalmente sustentaban a los medios en línea.
Esta tendencia ha sido una fuente de creciente alarma para los editores. Danielle Coffey, directora ejecutiva de News/Media Alliance, captó recientemente la frustración de la industria y afirmó:”Los enlaces fueron la última cualidad redentora de la búsqueda que proporcionó tráfico e ingresos a los editores. Ahora Google simplemente toma el contenido por la fuerza y lo utiliza sin retorno”.
Este sentimiento ha impulsado una ola de demandas de alto perfil, con organizaciones como The New York Times demandando a OpenAI y Microsoft por supuesta infracción de derechos de autor.
El conflicto no es sólo legal sino también técnico. Muchas empresas de IA han sido acusadas de ignorar por completo”robots.txt”. El propio Cloudflare acusó recientemente a Perplexity AI de utilizar”rastreadores sigilosos”para evitar los bloqueos de los editores, una afirmación que Perplexity negó con vehemencia. Estas disputas subrayan la insuficiencia del antiguo sistema de honor.
Cómo funciona la nueva política de señales de contenido
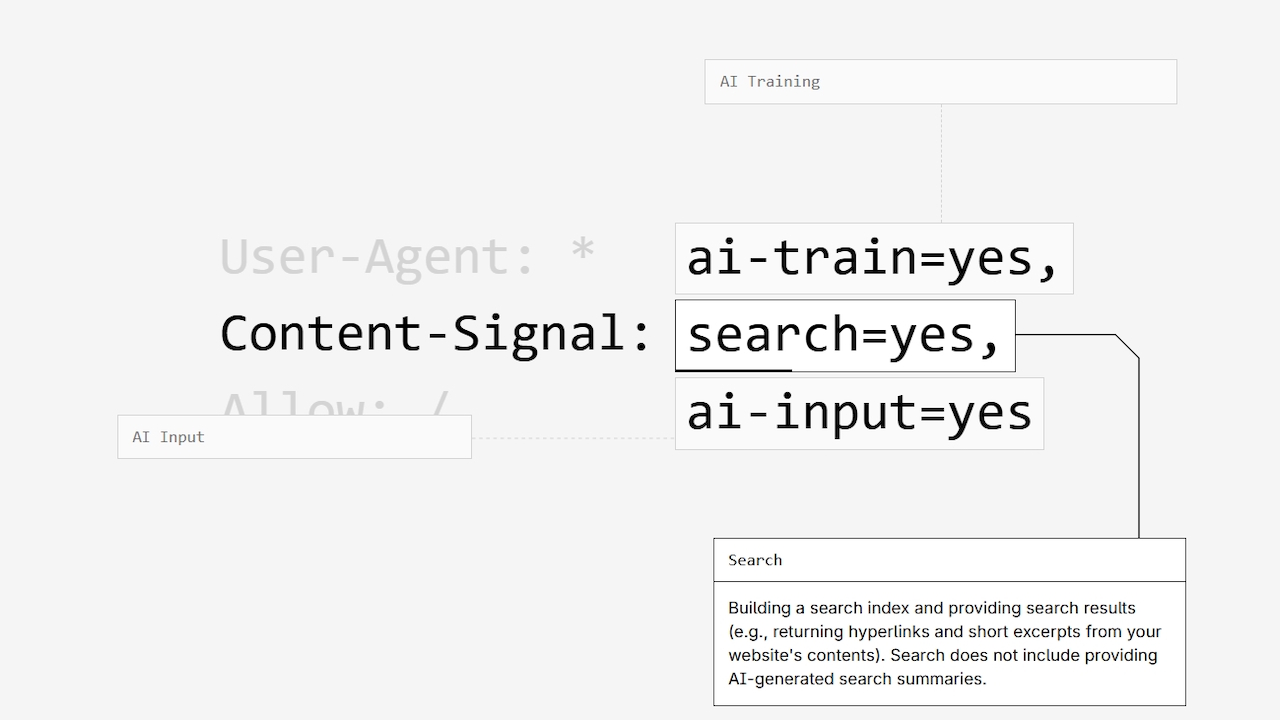
La Política de señales de contenido de Cloudflare intenta modernizar este sistema agregando una nueva capa de especificidad. Funciona integrando comentarios legibles por humanos y una nueva directiva legible por máquinas directamente en el archivo `robots.txt` de un sitio.
El objetivo es crear un estándar inequívoco sobre cómo los rastreadores pueden usar el contenido después de acceder a él, una distinción que el protocolo original nunca hizo. La política introduce tres señales distintas.
La señal de”búsqueda”permite que el contenido se utilice para crear un índice de búsqueda tradicional, incluidos hipervínculos y extractos breves, pero excluye explícitamente los resúmenes generados por IA. La señal”ai-input”gobierna el uso en tiempo real en respuestas de IA generativa, como la generación aumentada de recuperación (RAG). Finalmente, la señal”ai-train”controla si el contenido se puede utilizar para entrenar o ajustar modelos de IA. Los operadores de sitios web pueden expresar sus preferencias con una línea simple delimitada por comas, como `Content-Signal: search=yes, ai-train=no`.
Un “sí” otorga permiso, mientras que un “no” lo prohíbe. Fundamentalmente, si se omite una señal, la política establece que el propietario del sitio web ni otorga ni restringe el permiso, dejando una opción neutral. Para fomentar la adopción, Cloudflare ha publicado la política bajo una licencia CC0 y proporciona una herramienta generadora en ContentSignals.org.
Para darle más peso a la política, el texto proporcionado por Cloudflare incluye un aviso legal que enmarca las señales como una”reserva expresa de derechos”según la UE de 2019. Directiva de derechos de autor.
Esto posiciona las directivas no solo como solicitudes educadas sino como declaraciones legalmente significativas de la intención de un editor.
Para acelerar la adopción, Cloudflare ha habilitado automáticamente la política para más de 3,8 millones de dominios utilizando su función administrada `robots.txt`.
La configuración predeterminada es `search=yes` y `ai-train=no`. La compañía dejó deliberadamente neutral la señal”ai-input”en este lanzamiento, afirmando que no quería adivinar las preferencias de sus clientes para ese caso de uso específico. Esta medida crea efectivamente una exclusión masiva, a escala web, de la capacitación en IA de forma predeterminada.
El enigma del cumplimiento y la pregunta de Google
Si bien es un paso importante, el éxito de la política depende del cumplimiento voluntario. Al igual que el protocolo original, las señales de contenido son de carácter consultivo y no se pueden hacer cumplir técnicamente.
Es posible que algunos malos actores simplemente ignoren las nuevas reglas. Es por eso que Cloudflare enmarca la política como una”reserva de derechos”, fortaleciendo la posición legal de un editor.
Esta iniciativa es la última en la creciente defensa de Cloudflare para los editores. La compañía lanzó anteriormente”AI Labyrinth”, una herramienta para atrapar robots que no cumplen con las normas en laberintos de contenido falso, y está probando el”Pago por rastreo”para permitir que los sitios cobren por el acceso.
El CEO de Cloudflare, Matthew Prince, ha sido optimista respecto a la aplicación de la ley, bromeando:”¿Me estás diciendo que no puedo detener a un nerd con una corporación C en Palo Alto?”
Sigue existiendo un importante punto de conflicto. Google. Un testimonio durante el histórico juicio antimonopolio entre Estados Unidos y Google reveló que la empresa utiliza sistemas de exclusión voluntaria separados para sus principales productos de búsqueda y sus modelos de IA Gemini.
Un ejecutivo de Google DeepMind confirmó que el contenido que se excluyó de la capacitación de Gemini a través de la directiva”Google-Extended”aún podría ser utilizado por la división de búsqueda, afirmando:”correcto, para su uso en la búsqueda”.
Esto obliga a los editores a tomar una decisión injusta: bloquear la IA de Google. funciones y corre el riesgo de perder tráfico de búsqueda vital o permitir el uso del contenido en todos los ámbitos.
Hasta que los principales actores como Google adopten el nuevo estándar u ofrezcan controles más claros y unificados, los editores seguirán atrapados entre la visibilidad y el control, y la batalla por el futuro de la web continuará.