El nuevo modelo de razonamiento de DeepSeek llamado R1 desafía el rendimiento de ChatGPT o1 de OpenAI, aunque se basa en GPU limitadas y un presupuesto comparativamente pequeño.
En un entorno marcado por los controles de exportación de Estados Unidos que restringen los chips avanzados, la startup china de inteligencia artificial fundada por el administrador de fondos de cobertura Liang Wenfeng ha demostrado cómo la eficiencia y el intercambio de recursos pueden impulsar el desarrollo de la IA.
El ascenso de la empresa ha captado la atención de los círculos tecnológicos tanto en China como en Estados Unidos.
Relacionado: Por qué las sanciones de Estados Unidos pueden tener problemas para frenar el crecimiento tecnológico de China
El rápido ascenso de DeepSeek
El viaje de DeepSeek comenzó en 2021, cuando Liang, mejor conocido por su fondo comercial cuantitativo High-Flyer, comenzó a comprar miles de GPU Nvidia.
En ese momento, este movimiento parecía inusual. Como dijo uno de los socios comerciales de Liang al Financial Times, Era un tipo muy nerd con un peinado terrible que hablaba de construir un grupo de 10.000 chips para entrenar sus propios modelos. No lo tomamos en serio”.
Según la misma fuente, “No pudo articular su visión más que decir: quiero construir esto, y será un cambio de juego. Pensamos Esto sólo era posible gracias a gigantes como ByteDance y Alibaba”.
A pesar del escepticismo inicial, Liang siguió centrado en prepararse para posibles controles de exportación de Estados Unidos. Esta previsión permitió a DeepSeek asegurar un gran suministro de hardware Nvidia, incluidas las GPU A100 y H800, antes de que entraran en vigor restricciones radicales.
Relacionado: DeepSeek AI Open Sources VL2 Series of Vision Language Modelos
DeepSeek fue noticia al revelar que había entrenado su modelo R1 de 671 mil millones de parámetros por solo $ 5,6 millones usando 2048 GPU Nvidia H800.
Aunque el rendimiento del H800 está deliberadamente limitado para el mercado chino, los ingenieros de DeepSeek optimizaron el procedimiento de capacitación para lograr resultados de alto nivel a una fracción del costo típicamente asociado con modelos de lenguaje a gran escala..
En una entrevista publicado por MIT Technology Review, Zihan Wang, ex investigador de DeepSeek, describe cómo el equipo logró reducir el uso de memoria y la sobrecarga computacional preservando al mismo tiempo la precisión.
Dijo que las limitaciones técnicas los empujaron a explorar nuevas estrategias de ingeniería, lo que en última instancia los ayudó a seguir siendo competitivos frente a los laboratorios tecnológicos estadounidenses mejor financiados.
Relacionado: China El modelo de razonamiento DeepSeek R1 y el contendiente OpenAI o1 están fuertemente censurados
Resultados excepcionales en los puntos de referencia de matemáticas y codificación
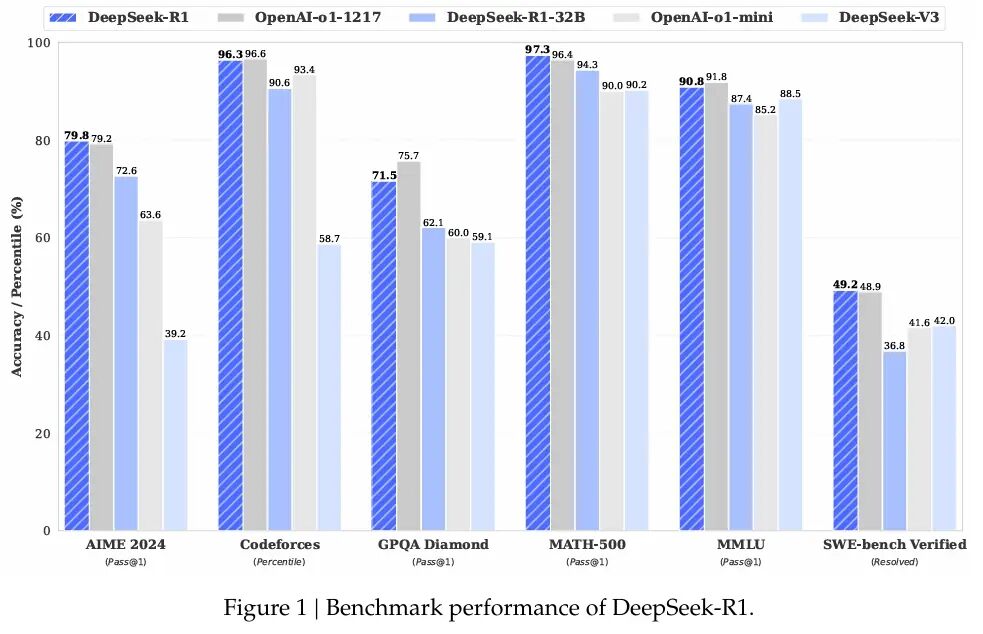
R1 demuestra excelentes capacidades en varios puntos de referencia de matemáticas y codificación. DeepSeek reveló que R1 obtuvo una puntuación del 97,3 % (Pass@1) en MATH-500 y del 79,8 % en AIME 2024.
Estos números rivalizan con la serie o1 de OpenAI y muestran cómo la optimización deliberada puede desafiar los modelos entrenados en chips más potentes.
Dimitris Papailiopoulos, investigador principal del laboratorio AI Frontiers de Microsoft, dijo a MIT Technology Review:”DeepSeek buscaba respuestas precisas en lugar de detallar cada paso lógico, reduciendo significativamente el tiempo de procesamiento y manteniendo un alto nivel”. de efectividad”.
Más allá del modelo principal, DeepSeek ha lanzado versiones más pequeñas de R1 que pueden ejecutarse en hardware de consumo. Aravind Srinivas, director ejecutivo de Perplexity, tuiteó en referencia a las variantes compactas: “DeepSeek tiene ha replicado en gran medida o1-mini y lo ha abierto.”
DeepSeek ha replicado en gran medida o1-mini y lo ha abierto. pic.twitter.com/2TbQ5p5l2c
— Aravind Srinivas (@AravSrinivas) 20 de enero de 2025
Razonamiento en cadena de pensamiento y R1-Zero
Además del estándar de R1 entrenamiento, DeepSeek se aventuró en el aprendizaje por refuerzo puro con una variante llamada R1-Zero. Este enfoque, detallado en la documentación de investigación de la empresa, descarta el ajuste supervisado en favor de la optimización de políticas relativas al grupo (GRPO).
Al eliminar un modelo crítico separado y basarse en puntuaciones de referencia agrupadas, R1-Zero mostró razonamiento en cadena de pensamiento y comportamientos de autorreflexión. Sin embargo, el equipo reconoció que R1-Zero producía resultados repetitivos o en lenguajes mixtos, lo que indica una necesidad de supervisión parcial antes de que pudiera usarse en aplicaciones cotidianas.
El espíritu de código abierto detrás de DeepSeek lo distingue de muchos laboratorios propietarios. Mientras que empresas estadounidenses como OpenAI, Meta y Google DeepMind a menudo mantienen ocultos sus métodos de entrenamiento, DeepSeek hace que su código, pesos de modelos y recetas de entrenamiento estén disponibles públicamente.
Relacionado: Mistral AI presenta Pixtral 12B para procesamiento de texto e imágenes
Según Liang, este enfoque surge del deseo de construir una cultura de investigación que favorezca transparencia y progreso colectivo. En una entrevista con el medio de comunicación chino 36Kr, explicó que muchas empresas chinas de IA tienen dificultades con la eficiencia en comparación con sus pares occidentales. y que cerrar esa brecha requiere colaboración tanto en hardware como en estrategias de capacitación.
Su punto de vista se alinea con otros en la escena de la IA en China, donde los lanzamientos de código abierto están en aumento. Alibaba Cloud ha introducido más de 100 modelos de código abierto y 01.AI, fundada por Kai-Fu Lee, se asoció recientemente con Alibaba Cloud para establecer un laboratorio industrial de IA.
La comunidad tecnológica global ha respondido con una mezcla de asombro y precaución. En X, Marc Andreessen, co-inventor del navegador web Mosaic y ahora uno de los principales inversores de Andreessen Horowitz, escribió: “Deepseek R1 es uno de los avances más sorprendentes e impresionantes que he visto jamás y, como código abierto, un profundo regalo para el mundo.”
Deepseek R1 es uno de los avances más sorprendentes e impresionantes que he visto jamás y, como código abierto, un profundo regalo para el mundo. 🤖🫡
— Marc Andreessen 🇺🇸 (@pmarca) 24 de enero de 2025
Yann LeCun, jefe de IA Un científico de Meta, señaló en LinkedIn que si bien el logro de DeepSeek podría parecer indicar que China está superando a los Estados Unidos, sería más exacto decir que los modelos de código abierto en conjunto están alcanzando a las alternativas patentadas.
“DeepSeek se ha beneficiado de la investigación abierta y del código abierto (por ejemplo, PyTorch y Llama de Meta)”, explicó. “Se les ocurrieron nuevas ideas y las construyeron sobre el trabajo de otras personas. Debido a que su trabajo está publicado y es de código abierto, todos pueden beneficiarse de él. Ese es el poder de la investigación abierta y del código abierto.”
Ver en Threads
Incluso Mark Zuckerberg, fundador y director ejecutivo de Meta, insinuó un camino diferente al anunciar inversiones masivas en centros de datos e infraestructura de GPU.
En Facebook, escribió: “Este será un año decisivo para la IA. En 2025, espero que Meta AI sea el asistente líder que atienda a más de mil millones de personas, Llama 4 se convertirá en el estado líder. el modelo artístico y construiremos un ingeniero de inteligencia artificial que comenzará a contribuir con cantidades cada vez mayores de código a nuestros esfuerzos de I+D. Para impulsar esto, Meta está construyendo un centro de datos de más de 2 GW que es tan grande que cubriría una parte importante de Manhattan. p>
Poneremos en línea aproximadamente 1 GW de computación en 2025 y finalizaremos el año con más de 1,3 millones de GPU. Planeamos invertir entre 60 000 y 65 000 millones de dólares en gastos de capital este año y, al mismo tiempo, aumentar significativamente nuestros equipos de IA. y tenemos el capital para seguir invirtiendo en los años venideros. Este es un esfuerzo enorme y en los próximos años impulsará nuestros productos y negocios principales, desbloqueará innovaciones históricas y ampliará el liderazgo tecnológico estadounidense. ¡Vamos a construir!”
Los comentarios de Zuckerberg sugieren que las estrategias que utilizan muchos recursos siguen siendo una fuerza importante en la configuración del sector de la IA.
Relacionado: LLaMA AI Under Fire – Lo que Meta no te dice sobre los modelos de “código abierto”
Ampliación del impacto y perspectivas futuras
Para DeepSeek, la combinación de El talento, el almacenamiento temprano de GPU y el énfasis en los métodos de código abierto lo han convertido en un foco de atención generalmente reservado para los grandes gigantes tecnológicos. En julio de 2024, Liang declaró que su equipo tenía como objetivo abordar lo que llamó una brecha de eficiencia en la IA china.
Describió que muchas empresas locales de inteligencia artificial requieren el doble de potencia informática para igualar los resultados en el extranjero, lo que se agrava aún más cuando se tiene en cuenta el uso de datos. Las ganancias del fondo de cobertura de High-Flyer le dan a DeepSeek un amortiguador contra las presiones comerciales inmediatas. permitiendo a Liang y sus ingenieros concentrarse en las prioridades de investigación. Liang dijo:
“Estimamos que los mejores modelos nacionales y extranjeros pueden tener una brecha única en la estructura del modelo y la dinámica de entrenamiento. Sólo por esta razón, necesitamos consumir el doble de potencia informática para lograr el mismo efecto.
Además, también puede haber una brecha doble en la eficiencia de los datos, es decir, necesitamos consumir el doble de datos de entrenamiento y potencia informática para lograr el mismo efecto. Juntos, necesitamos consumir cuatro veces más potencia informática. Lo que tenemos que hacer es reducir continuamente estas brechas.”
La reputación de DeepSeek en China también recibió un impulso cuando Liang se convirtió en el único líder de IA invitado a una reunión de alto perfil con Li Qiang, el segundo presidente del país. funcionario más poderoso, donde se le instó a centrarse en la creación de tecnologías centrales.
Los analistas ven esto como una señal más de que Beijing está apostando fuertemente por pequeños innovadores locales para ampliar los límites de la IA bajo restricciones de hardware.
Si bien el futuro sigue siendo incierto, especialmente porque las restricciones estadounidenses pueden endurecerse aún más, DeepSeek se destaca por abordar los desafíos de maneras que transforman las limitaciones en vías para una rápida resolución de problemas.
Al dar a conocer sus avances y ofrecer ofertas más pequeñas. técnicas de capacitación a gran escala, la startup ha motivado debates más amplios sobre si la eficiencia de los recursos puede rivalizar seriamente con los clústeres de supercomputación masivos.
A medida que DeepSeek continúa perfeccionando R1, los ingenieros y. Los responsables políticos de ambos lados del Pacífico están observando de cerca para ver si los logros de este modelo pueden allanar una ruta sostenible para el progreso de la IA en una era de restricciones cambiantes.