Microsoft ha presentado rStar-Math, una continuación y perfeccionamiento de su anterior rStar framework, para ampliar los límites de los modelos de lenguajes pequeños (SLM) en el razonamiento matemático.
Diseñado para competir con sistemas más grandes como o1-preview de OpenAI, rStar-Math logra puntos de referencia notables en la resolución de problemas al tiempo que demuestra cómo los modelos compactos pueden funcionar a niveles competitivos. Este desarrollo muestra un cambio en las prioridades de la IA, pasando de la ampliación a la optimización del rendimiento para tareas específicas.
Avanzando de rStar a rStar-Math
El rStar El marco del verano pasado sentó las bases para mejorar el razonamiento de GST a través de Monte Carlo Tree Search (MCTS), un algoritmo que refina las soluciones simulando y validando múltiples rutas.
rStar demostró que los modelos más pequeños podían manejar tareas complejas, pero su aplicación seguía siendo general. rStar-Math se basa en esta base con innovaciones específicas diseñadas para el razonamiento matemático.
Un elemento central del éxito de rStar-Math es su metodología de cadena de pensamiento (CoT) aumentada por código, donde el modelo produce soluciones en ambos Lenguaje natural y código Python ejecutable.
Esta estructura de salida dual garantiza que los pasos de razonamiento intermedios sean verificables, lo que reduce los errores y mantiene la coherencia lógica. Los investigadores enfatizaron la importancia de este enfoque y afirmaron:”La coherencia mutua refleja la práctica humana común en ausencia de supervisión, donde el acuerdo entre pares sobre las respuestas derivadas sugiere una mayor probabilidad de corrección”.
Relacionado: El modelo chino DeepSeek R1-Lite-Preview apunta al liderazgo de OpenAI en razonamiento automatizado
Además de CoT, rStar-Math presenta un modelo de preferencia de proceso (PPM), que evalúa y clasifica los pasos intermedios según la calidad. A diferencia de los sistemas de recompensa tradicionales que a menudo se basan en datos ruidosos, el PPM prioriza la coherencia lógica y la precisión, mejorando aún más la confiabilidad del modelo. Los investigadores escriben:
“El PPM aprovecha este hecho. que, aunque los valores Q todavía no son lo suficientemente precisos para calificar cada paso de razonamiento a pesar de utilizar implementaciones extensas de MCTS, los valores Q pueden distinguir de manera confiable los pasos positivos (correctos) de los negativos (irrelevantes/incorrectos) unos.
Por lo tanto, el método de entrenamiento construye pares de preferencias para cada paso en función de los valores Q y utiliza una pérdida de clasificación por pares para optimizar la predicción de puntuación de PPM para cada paso de razonamiento, logrando un etiquetado confiable. Este enfoque evita los métodos convencionales que utilizan directamente valores Q como etiquetas de recompensa, que son inherentemente ruidosos e imprecisos en la asignación de recompensas por pasos”.
Finalmente, una receta de autoevolución de cuatro rondas que construye progresivamente una frontera modelo de políticas y PPM desde cero.
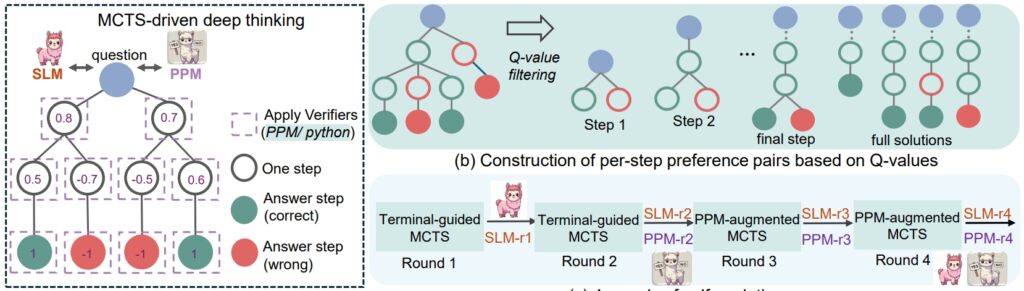 procedimiento de razonamiento rSTar-Math (Fuente: artículo de investigación)
procedimiento de razonamiento rSTar-Math (Fuente: artículo de investigación)
Rendimiento que desafía los modelos más grandes
rStar-Math establece nuevos estándares en puntos de referencia de razonamiento matemático, logrando resultados que rivalizan, y en algunos casos superan, a los de sistemas de IA más grandes
En el conjunto de datos GSM8K. , una prueba de razonamiento matemático, la precisión de un modelo de 7 mil millones de parámetros mejoró del 12,51% al 63,91% después de integrar rStar-Math en
Los resultados del conjunto de datos MATH fueron igualmente impresionantes: rStar-Math logró una tasa de precisión del 90 %, superando la vista previa o1 de OpenAI.
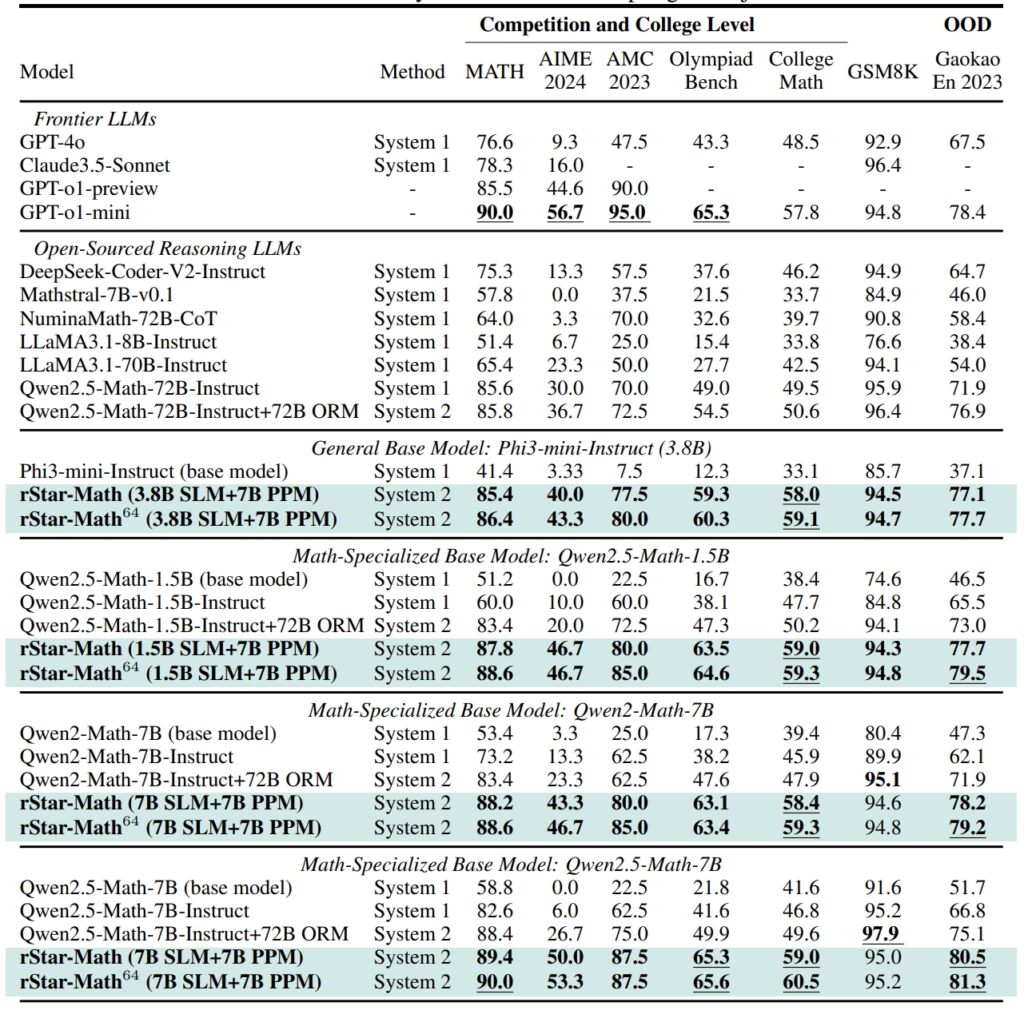 Rendimiento de rStar-Math y otros LLM de vanguardia en la mayoría desafiantes puntos de referencia matemáticos (Fuente: trabajo de investigación)
Rendimiento de rStar-Math y otros LLM de vanguardia en la mayoría desafiantes puntos de referencia matemáticos (Fuente: trabajo de investigación)
Estos logros resaltan la capacidad del marco para permitir que los SLM manejen tareas previamente dominadas por modelos grandes que consumen muchos recursos. Al enfatizar la coherencia lógica y los pasos intermedios verificables, rStar-Math aborda uno de los desafíos más persistentes de la IA: garantizar un razonamiento confiable en espacios de problemas complejos.
Innovaciones técnicas que impulsan rStar-Math
La evolución de rStar a rStar-Math introduce varios avances clave. La integración de MCTS sigue siendo fundamental para el marco, lo que permite que el modelo explore diversos caminos de razonamiento y priorice los más prometedores.
La incorporación del razonamiento CoT, centrado en la verificación del código, garantiza que los resultados sean interpretables y precisos.
Relacionado: QwQ-32B de Alibaba-La vista previa se une a la batalla del razonamiento del modelo de IA con OpenAI
Quizás lo más transformador sea el proceso de entrenamiento autoevolutivo de rStar-Math. A lo largo de cuatro rondas iterativas, el marco perfecciona su modelo de políticas y PPM, incorporando datos de razonamiento de mayor calidad en cada paso.
Este enfoque iterativo permite que el modelo mejore continuamente su rendimiento, logrando resultados de última generación sin depender de la destilación de modelos más grandes.
Comparación de rStar-Math a o1 de OpenAI
Mientras Microsoft se centra en optimizar modelos más pequeños, OpenAI continúa priorizando la ampliación de sus sistemas.
El modo Pro o1, introducido en diciembre de 2024 como parte del plan ChatGPT Pro, ofrece capacidades de razonamiento avanzadas diseñadas para aplicaciones de alto riesgo como codificación e investigación científica. OpenAI informó que o1 Pro Mode logró una tasa de precisión del 86 % en AIME y una tasa de éxito del 90 % en pruebas comparativas de codificación como Codeforces.
rStar-Math representa un cambio en la innovación de la IA, desafiando el enfoque de la industria en modelos más grandes. como medio principal para lograr un razonamiento avanzado. Al mejorar los SLM con optimizaciones específicas de dominio, Microsoft ofrece una alternativa sostenible que reduce los costos computacionales y el impacto ambiental.
Relacionado: Alineación deliberativa: la estrategia de seguridad de OpenAI para sus modelos de pensamiento o1 y o3
El éxito del marco en el razonamiento matemático abre puertas a aplicaciones más amplias, desde la educación a la investigación científica.
Los investigadores planean publicar el código y los datos de rStar-Math en GitHub, allanando el camino para una mayor colaboración y desarrollo. Esta transparencia refleja el enfoque de Microsoft para hacer que las herramientas de IA de alto rendimiento sean accesibles a un público más amplio, incluidas instituciones académicas y organizaciones medianas.
Relacionado: Semianálisis: No, el escalamiento de IA no es No se está desacelerando
A medida que se intensifica la competencia entre Microsoft y OpenAI, los avances introducidos por rStar-Math resaltan el potencial de los modelos más pequeños para desafiar el dominio de los sistemas más grandes. Al priorizar la eficiencia y la precisión, rStar-Math establece un nuevo punto de referencia sobre lo que pueden lograr los sistemas compactos de IA.