La división de investigación de IA de Meta ha presentado un modelo inventivo que difiere del aprendizaje tradicional basado en texto. A diferencia de los modelos de lenguajes grandes (LLM) predominantes que derivan el conocimiento de datos textuales, el nuevo modelo de Meta, llamada Video Joint Embedding Predictive Architecture (V-JEPA), avanza aprendiendo directamente de las entradas de vídeo. Este importante paso fue encabezado por Yann LeCun, líder del grupo de investigación de IA fundacional de Meta (FAIR), lo que marca un cambio fundamental hacia modelos que pueden asimilar e interpretar el mundo visual de manera más natural y eficiente.
La mecánica de V-JEPA
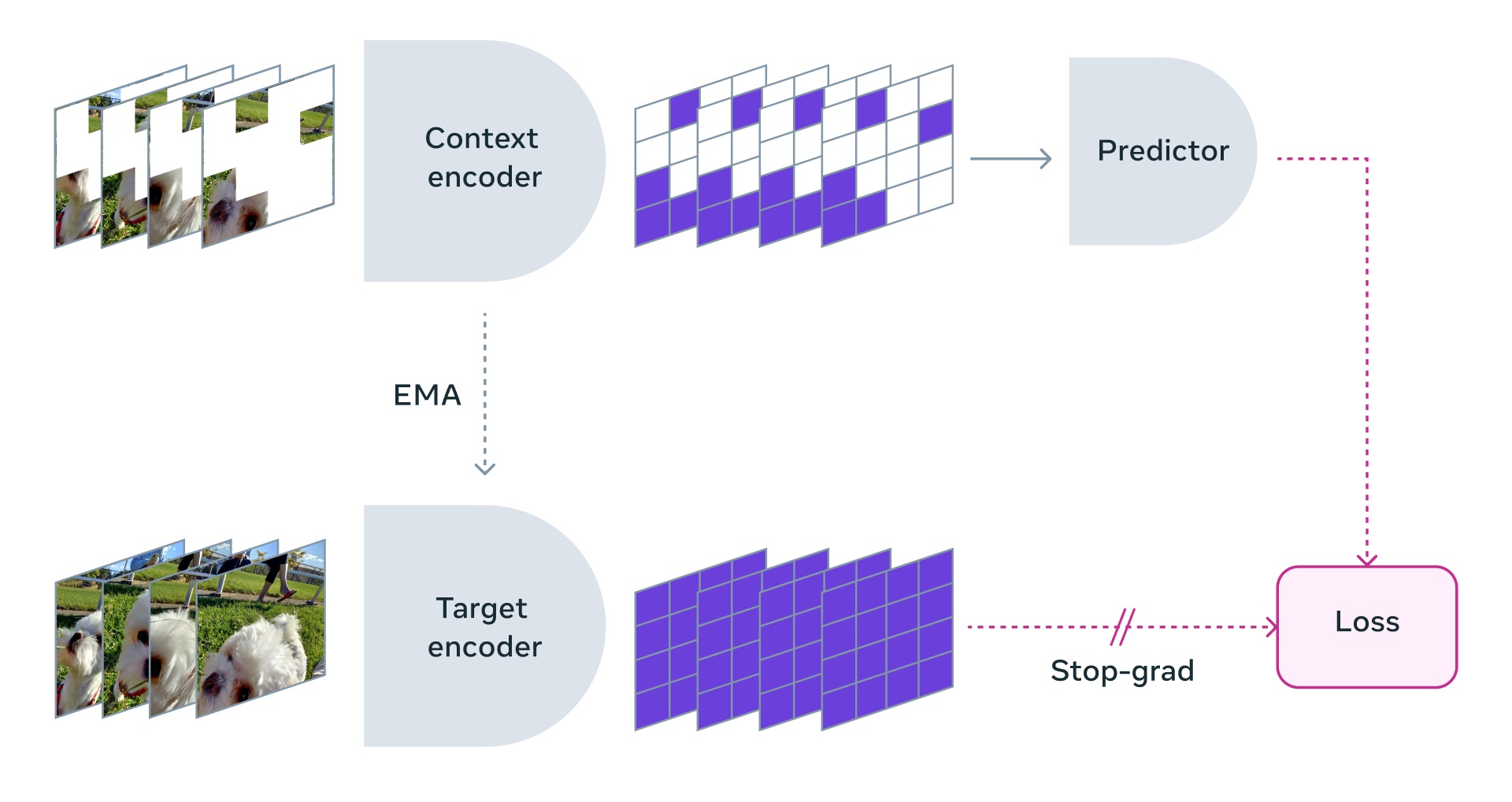
V-JEPA se distingue por emplear una metodología de aprendizaje única en la que procesa contenido de vídeo sin etiquetar para inferir lo que ocurre en partes de la pantalla momentáneamente ocultas a la vista. Esta técnica de enmascaramiento de video refleja la estrategia de enmascaramiento utilizada en la capacitación de LLM, donde se ocultan palabras seleccionadas para obligar al modelo a predecir la información faltante. Sin embargo, el enfoque de V-JEPA en video en lugar de texto le permite desarrollar un modelo conceptual del mundo, enriqueciendo su capacidad para reconocer y comprender interacciones complejas de objetos dentro de su campo visual. Es notable que V-JEPA, como lo subrayan LeCun y su equipo, no está diseñado como un modelo generativo sino predictivo con la capacidad de construir una representación interna del mundo.
Más amplio Implicaciones para la IA y más allá
El lanzamiento de V-JEPA no solo es un testimonio de la innovación continua de Meta en IA, sino que también tiene implicaciones de gran alcance para el ecosistema tecnológico más amplio, particularmente en áreas como la realidad aumentada (AR). Meta ha discutido anteriormente cómo aprovechar un”modelo mundial”para aplicaciones de AR, incluidas las gafas inteligentes, que se beneficiarían enormemente de un modelo como V-JEPA que posee una comprensión inherente del mundo audiovisual. Esto podría revolucionar la forma en que la IA ayuda a interactuar y aumente las experiencias humanas en tiempo real proporcionando contenido digital personalizado y contextual.
Además, V-JEPA promete un cambio en los métodos predominantes para entrenar modelos de IA. El panorama actual del desarrollo de modelos fundamentales está marcado por demandas considerables de tiempo y recursos computacionales, lo que tiene un impacto más amplio. implicaciones económicas y ecológicas. Una mejora de la eficiencia en las metodologías de capacitación, como lo demuestra V-JEPA, podría democratizar el acceso al desarrollo avanzado de IA, permitiendo que entidades más pequeñas participen reduciendo los costos generales.
En un movimiento estratégico, Meta ha optado por lanzar V-JEPA bajo una licencia no comercial Creative Commons, fomentando una amplia experimentación y potencialmente acelerando el progreso en el campo de la IA. Este enfoque se alinea con la filosofía de Meta de colaboración de código abierto y contrasta con los modelos más propietarios favorecidos por algunas organizaciones en el espacio de la IA.
Mientras Meta mira hacia el futuro, agregar dimensiones de audio al modelo representa el próximo hito, mejorar aún más las capacidades de aprendizaje de la IA al proporcionar un conjunto de datos más rico similar a la experiencia de aprendizaje de un niño. Este avance subraya el compromiso de Meta de ser pionero en un camino hacia la inteligencia artificial general, un futuro en el que la IA puede rivalizar con las capacidades cognitivas humanas en diversos dominios.