Investigadores del Tencent AI Lab han presentado un nuevo marco de IA diseñado para superar los límites de velocidad de los grandes modelos de lenguaje actuales.
El sistema, detallado en un artículo publicado en línea esta semana, se llama CALM, por sus siglas en inglés, Continuo Autoregressive Language Models. Desafía directamente el lento proceso token por token que impulsa la IA más generativa en la actualidad.
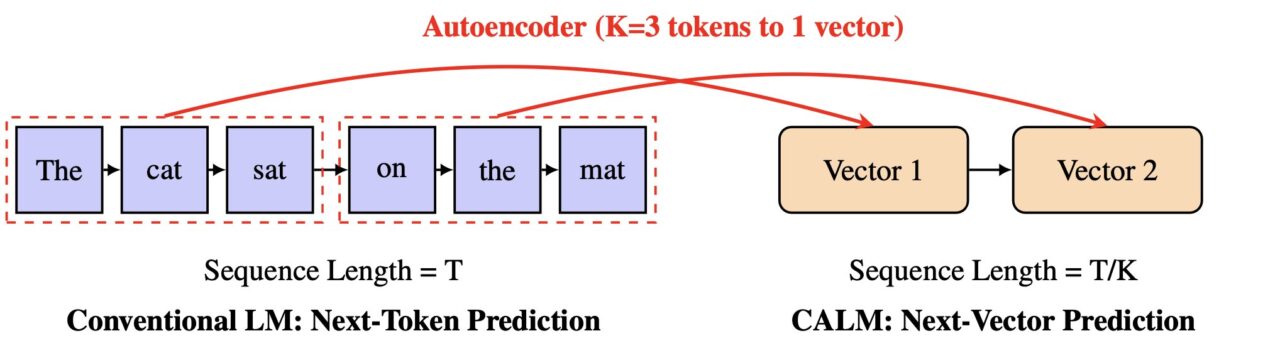
En lugar de predecir una pequeña porción de una palabra a la vez, CALM aprende a predecir un único vector que representa un fragmento completo de texto. Este método podría hacer que la generación de IA sea mucho más rápida y eficiente, abriendo un nuevo camino para los modelos de escala.
La tiranía del token: la IA Cuello de botella autorregresivo
Una debilidad fundamental de los LLM modernos es su dependencia de la generación autorregresiva, token por token. Esta dependencia secuencial es el mayor cuello de botella que limita la velocidad y escalabilidad de la IA.
Generar un artículo extenso requiere miles de pasos de predicción secuenciales, lo que hace que el proceso sea computacionalmente costoso y lento. Este no es sólo un problema académico; es por eso que usar modelos potentes es costoso y la generación de formato largo en tiempo real sigue siendo un desafío.
Este problema de eficiencia se ha convertido en un campo de batalla central para los desarrolladores de IA. Como señaló anteriormente Google Research, “a medida que implementamos estos modelos para más usuarios, hacerlos más rápidos y menos costosos sin sacrificar la calidad es un desafío crítico”.
La industria ha estado explorando numerosas soluciones, desde las cascadas especulativas de Google hasta nuevas técnicas de compresión. Ahora, el trabajo de Tencent propone una solución más radical.
El documento propone un plan para una nueva clase de modelos de lenguaje ultraeficientes y para el cuello de botella de velocidad inducido por los tokens.
El objetivo es cambiar fundamentalmente la unidad de predicción de un único token con poca información a algo mucho más rico.
Un nuevo paradigma: predecir vectores en lugar de tokens
De forma directa Como desafío al status quo de la IA generativa, CALM replantea por completo la tarea de predicción. Los investigadores proponen un nuevo eje de escala para los LLM.
“Sostenemos que superar este cuello de botella requiere un nuevo eje de diseño para el escalamiento de los LLM: aumentar el ancho de banda semántico de cada paso generativo”, escriben en el artículo.
Al aumentar este “ancho de banda semántico”, el modelo puede procesar más información en un solo paso. CALM logra esto a través de un innovador proceso de dos etapas que opera en un espacio continuo, en lugar de discreto.
En el corazón del diseño de CALM se encuentra un codificador automático de alta fidelidad. Este componente aprende a comprimir una porción de K tokens (por ejemplo, cuatro tokens) en un único vector denso y continuo.
Lo más importante es que puede reconstruir los tokens originales a partir de este vector con una precisión superior al 99,9 %. Luego, un modelo de lenguaje independiente realiza una predicción autorregresiva en este nuevo espacio vectorial.
Según la documentación oficial del proyecto, “en lugar de predecir un token discreto a la vez, CALM aprende a predecir un único vector continuo que representa un fragmento completo de K tokens”.
Esto reduce el número de pasos generativos por un factor de K, lo que lleva a ganancias de eficiencia significativas.
El conjunto de herramientas sin probabilidades: cómo CALM aprende y mide el éxito
Pasar de tokens discretos a vectores continuos presenta un desafío importante: el modelo ya no puede calcular una distribución de probabilidad explícita sobre todos los resultados posibles utilizando una capa softmax estándar.
Esto hace que los métodos tradicionales de capacitación y evaluación, que se basan en el cálculo de probabilidades, sean inaplicables. Para resolver esto, el equipo de Tencent desarrolló un marco integral y libre de probabilidades.
Para el entrenamiento, CALM emplea un método de entrenamiento basado en energía, que utiliza una regla de puntuación estrictamente adecuada para guiar el modelo sin necesidad de calcular probabilidades.
Para la evaluación, los investigadores introdujeron una métrica novedosa llamada BrierLM. Alejándose de métricas tradicionales como la perplejidad, BrierLM se deriva de la puntuación Brier, una herramienta de pronóstico probabilístico.
Permite una comparación justa basada en muestras de las capacidades del modelo al verificar qué tan bien las predicciones se alinean con la realidad, un método perfectamente adecuado para modelos donde las probabilidades son intratables.
Un nuevo eje para el escalamiento de la IA y la carrera por la eficiencia
El impacto práctico de esto La nueva arquitectura es una compensación superior entre rendimiento y computación.
El modelo CALM reduce los requisitos computacionales de entrenamiento en un 44 % y la inferencia en un 33 % en comparación con una base sólida. Esto demuestra que ampliar el ancho de banda semántico de cada paso es una nueva y poderosa palanca para mejorar la eficiencia computacional.
El trabajo posiciona a CALM como un competidor importante en la carrera de toda la industria para construir una IA más rápida, más barata y más accesible.
Google ha estado abordando el problema de la velocidad de la IA con métodos como cascadas especulativas y aprendizaje anidado. Otras empresas emergentes, como Inception, están explorando arquitecturas completamente diferentes, como los LLM basados en difusión en su “Mercury Coder” para escapar del “cuello de botella estructural” de la autorregresión.
En conjunto, estos diversos enfoques resaltan un cambio en el desarrollo de la IA. La industria está pasando de un enfoque puramente de escala a una búsqueda más sostenible de una inteligencia artificial más inteligente y económicamente viable. El enfoque vectorial de CALM ofrece un nuevo camino a seguir en ese frente.


