DeepSeek ha lanzado sus últimos modelos de IA de código abierto, DeepSeek-R1 y DeepSeek-R1-Zero, redefiniendo cómo se pueden lograr capacidades de razonamiento a través del aprendizaje por refuerzo (RL).
El nuevos modelos desafían el desarrollo de IA convencional al demostrar que el ajuste fino supervisado (SFT) no es esencial para cultivar tecnologías avanzadas. capacidades de resolución de problemas. Con resultados de referencia que rivalizan con sistemas propietarios como la serie o1 de OpenAI, los modelos de DeepSeek ilustran el creciente potencial de la IA de código abierto para ofrecer herramientas competitivas y de alto rendimiento.
El éxito de estos modelos radica en sus enfoques únicos de refuerzo Aprendizaje (RL), la introducción de datos de arranque en frío y un proceso de destilación eficaz. Estas innovaciones han producido capacidades de razonamiento en codificación, matemáticas y tareas de lógica general, lo que subraya la viabilidad de la IA de código abierto como competidor de los principales modelos propietarios.
Relacionado: DeepSeek AI Open Sources Serie VL2 de modelos de lenguaje de visión
Los resultados de las pruebas comparativas resaltan el potencial del código abierto
El desempeño de DeepSeek-R1 en pruebas comparativas ampliamente respetadas confirma sus capacidades:
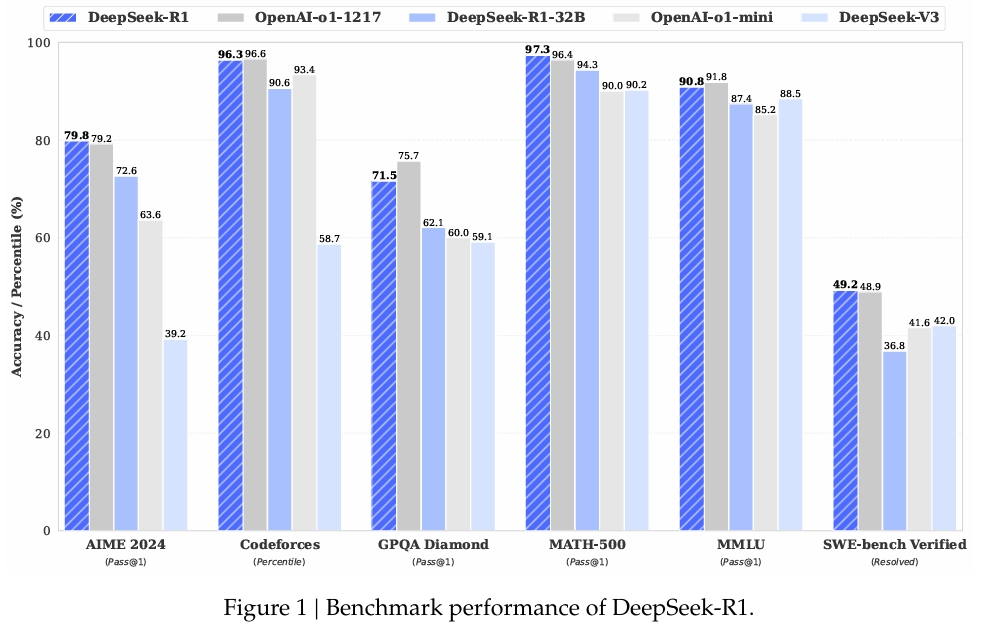
En MATH-500, un conjunto de datos diseñado para evaluar la resolución de problemas matemáticos, DeepSeek-R1 logró una puntuación Pass@1 del 97,3%, igualando la de OpenAI. Modelo o1-1217. En la prueba comparativa AIME 2024, que se centra en tareas de razonamiento avanzado, el modelo obtuvo una puntuación del 79,8 %, superando ligeramente los resultados de OpenAI.
El rendimiento del modelo en LiveCodeBench, una prueba comparativa para tareas lógicas y de codificación, fue igualmente notable, con una puntuación Pass@1-CoT del 65,9%. Según la investigación de DeepSeek, esto lo convierte en uno de los modelos de código abierto con mejor desempeño en esta categoría.
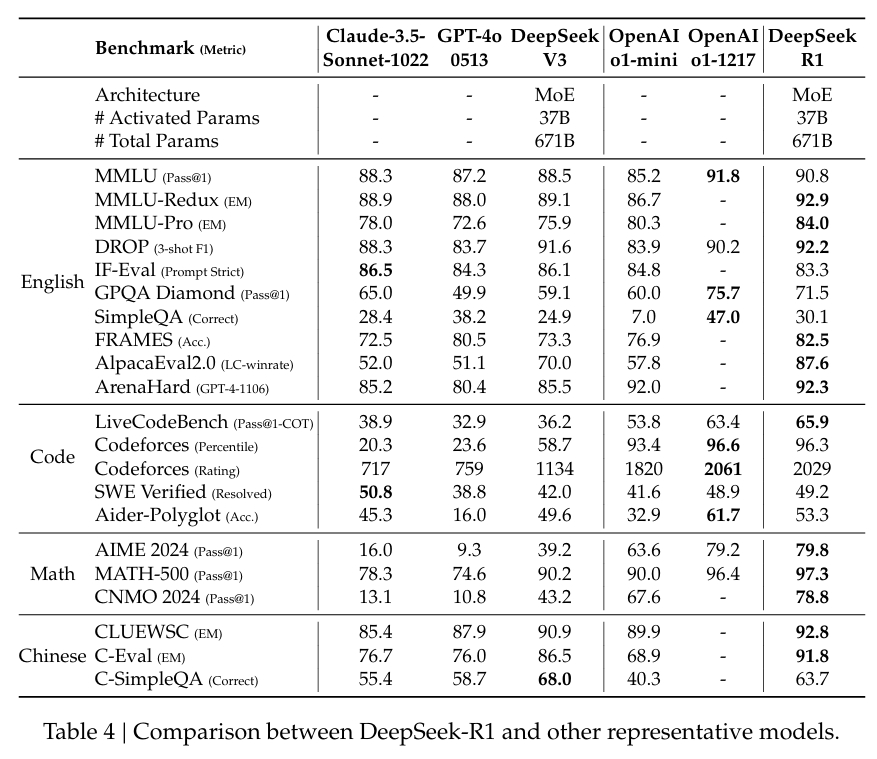
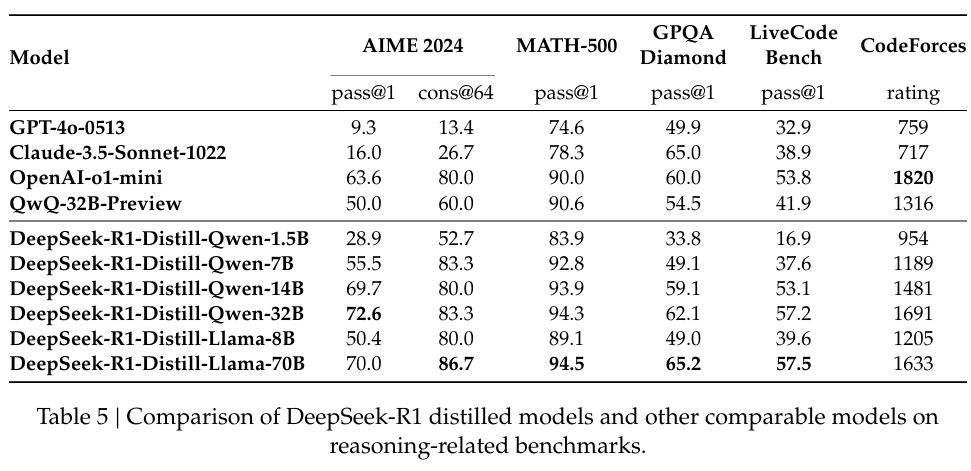
La empresa también ha invertido mucho en destilación, garantizando que las versiones más pequeñas de DeepSeek-R1 conservan gran parte de las capacidades de razonamiento de los modelos más grandes. En particular, el modelo de 32 mil millones de parámetros, DeepSeek-R1-Distill-Qwen-32B, superó al o1-mini de OpenAI en varias categorías y, al mismo tiempo, fue más accesible computacionalmente.
Aprendizaje por refuerzo sin supervisión: DeepSeek-R1-Zero
DeepSeek-R1-Zero es el audaz intento de la compañía de explorar Entrenamiento solo RL. Emplea un algoritmo único, Optimización de políticas relativas al grupo (GRPO), que agiliza el entrenamiento de RL al eliminar la necesidad de un modelo crítico separado.
En su lugar, utiliza puntuaciones agrupadas para estimar líneas base, lo que reduce significativamente los costos computacionales y al mismo tiempo manteniendo la calidad de la formación. Este enfoque permite que el modelo desarrolle comportamientos de razonamiento, incluido el razonamiento en cadena de pensamiento (CoT) y la autorreflexión.
En su artículo de investigación, el equipo de DeepSeek declaró:
“DeepSeek-R1-Zero demuestra capacidades como la autoverificación, la reflexión y la generación de CoT largos. Sin embargo, tiene problemas con la repetición, la legibilidad y la combinación de idiomas, lo que lo hace menos adecuado para casos de uso del mundo real”.
Si bien estos comportamientos emergentes fueron prometedores, las limitaciones del modelo resaltaron la necesidad de perfeccionarlo. Por ejemplo , sus resultados eran ocasionalmente repetitivos o mostraban problemas de lenguaje mixto, lo que reducía la usabilidad en escenarios prácticos.
De solo RL a capacitación híbrida: DeepSeek-R1
Para abordar estos desafíos, DeepSeek desarrolló DeepSeek-R1, combinando RL con ajuste fino supervisado. El proceso comenzó con un conjunto de datos de arranque en frío seleccionados de CoT largos y legibles por humanos. diseñado para mejorar la coherencia y la legibilidad de la línea base. Al entrenarse sobre esta base, el modelo ingresó a la realidad virtual con una capacidad mejorada para cumplir con las expectativas humanas de claridad y relevancia.
Relacionado: LLaMA AI Under Fire: Lo que Meta no le dice sobre los modelos de “código abierto”
DeepSeek describió este enfoque en su documentación:
“A diferencia de R1-Zero, para evitar la fase temprana de arranque en frío inestable del entrenamiento de RL desde el modelo base, para R1 construimos y recopilamos una pequeña cantidad de datos CoT largos para ajustar el modelo como el actor de RL inicial”.
El proceso también incluyó RL iterativo para refinar capacidades de razonamiento y resolución de problemas, produciendo un modelo capaz de manejar escenarios complejos como codificación y pruebas matemáticas.
Accesibilidad del código abierto y desafíos futuros
DeepSeek ha lanzado sus modelos bajo la licencia MIT, enfatizando su compromiso con los principios de código abierto. Este modelo de licencia permite a los investigadores y desarrolladores utilizar, modificar y desarrollar libremente el trabajo de DeepSeek, fomentando la colaboración y la innovación en la comunidad de IA.
A pesar de sus éxitos, el equipo reconoce que persisten desafíos. Los resultados en idiomas mixtos, la sensibilidad rápida y la necesidad de mejores capacidades de ingeniería de software son áreas de mejora. Las iteraciones futuras de DeepSeek-R1 tendrán como objetivo abordar estas limitaciones y al mismo tiempo expandir su funcionalidad a nuevos dominios.
Los investigadores han expresado optimismo sobre su progreso y afirmaron:
“Al diseñar cuidadosamente el patrón para el frío-Al iniciar datos con antecedentes humanos, observamos un mejor rendimiento frente a DeepSeek-R1-Zero. Creemos que el entrenamiento iterativo es una mejor manera de razonar modelos.”
Implicaciones para la industria de la IA
El trabajo de DeepSeek señala un cambio en el panorama de la investigación de la IA , donde los modelos de código abierto ahora pueden competir con los líderes propietarios. Al demostrar que RL puede lograr un razonamiento de alto nivel sin SFT y enfatizar la destilación para escalar la accesibilidad, DeepSeek ha establecido un punto de referencia para futuras investigaciones en IA.
A medida que la IA de código abierto continúa evolucionando, los avances de DeepSeek-R1 proporcionan un modelo para aprovechar la RL para producir modelos prácticos y de alto rendimiento.