OpenAI ha introducido la alineación deliberativa, una metodología destinada a incorporar el razonamiento de seguridad en el funcionamiento mismo de los sistemas de inteligencia artificial. Diseñado para abordar desafíos persistentes en la seguridad de la IA, la alineación deliberativa permite que los modelos de IA hagan referencia explícita y razonen sobre políticas de seguridad definidas por humanos durante interacciones en tiempo real.
Según OpenAI, el enfoque representa una evolución importante en la capacitación en seguridad de la IA, yendo más allá de la dependencia de conjuntos de datos precodificados a sistemas que evalúan dinámicamente y responden a indicaciones con decisiones contextualmente informadas.
En los sistemas tradicionales de IA, los mecanismos de seguridad se implementan durante las fases previas y posteriores al entrenamiento, a menudo basándose en conjuntos de datos anotados por humanos para inferir comportamientos ideales.
Relacionado: OpenAI presenta el nuevo modelo o3 con Habilidades de razonamiento drásticamente mejoradas
Estos métodos, si bien son fundamentales, pueden dejar lagunas a la hora de Los modelos encuentran escenarios novedosos o complejos que quedan fuera de sus datos de entrenamiento. La alineación deliberativa de OpenAI ofrece una solución al equipar los sistemas de IA para que interactúen activamente con las especificaciones de seguridad, garantizando que las respuestas estén calibradas según las demandas éticas, legales y prácticas de su entorno.
Según los investigadores de OpenAI, “[Deliberative alineación] es el primer enfoque para enseñar directamente a un modelo el texto de sus especificaciones de seguridad y entrenar al modelo para que delibera sobre estas especificaciones en el momento de la inferencia”.
Enseñar a pensar en los sistemas de IA Seguridad
La metodología de alineación deliberativa implica un proceso de capacitación en dos etapas que combina ajuste fino supervisado (SFT) y aprendizaje por refuerzo (RL), respaldado por la generación de datos sintéticos. Este enfoque estructurado no solo enseña a los modelos el contenido de las políticas de seguridad sino que también los capacita. para aplicar estas pautas dinámicamente durante su operación.
En la fase de ajuste fino supervisado (SFT), los modelos de IA se exponen a un conjunto de datos seleccionados de indicaciones combinadas con respuestas detalladas que hacen referencia explícita a la seguridad interna de OpenAI. especificaciones.
Estos ejemplos de cadena de pensamiento (CoT) ilustran cómo los modelos deberían abordar diversos escenarios, dividiendo indicaciones complejas en pasos más pequeños y manejables mientras se cruzan las pautas de seguridad. Luego, los resultados son evaluados por un sistema interno de inteligencia artificial, a menudo denominado”juez”, que evalúa su cumplimiento de los estándares políticos.
Relacionado: Sam Altman, director ejecutivo de OpenAI, propiedad y venta Participación de OpenAI previamente desconocida
La fase de aprendizaje por refuerzo mejora aún más las capacidades del modelo al ajustar su proceso de razonamiento. Utilizando la retroalimentación del modelo de juez, el sistema mejora de forma iterativa su capacidad de razonar mediante matices o razonamientos. indicaciones ambiguas, que se alinean más estrechamente con las prioridades éticas y operativas de OpenAI.
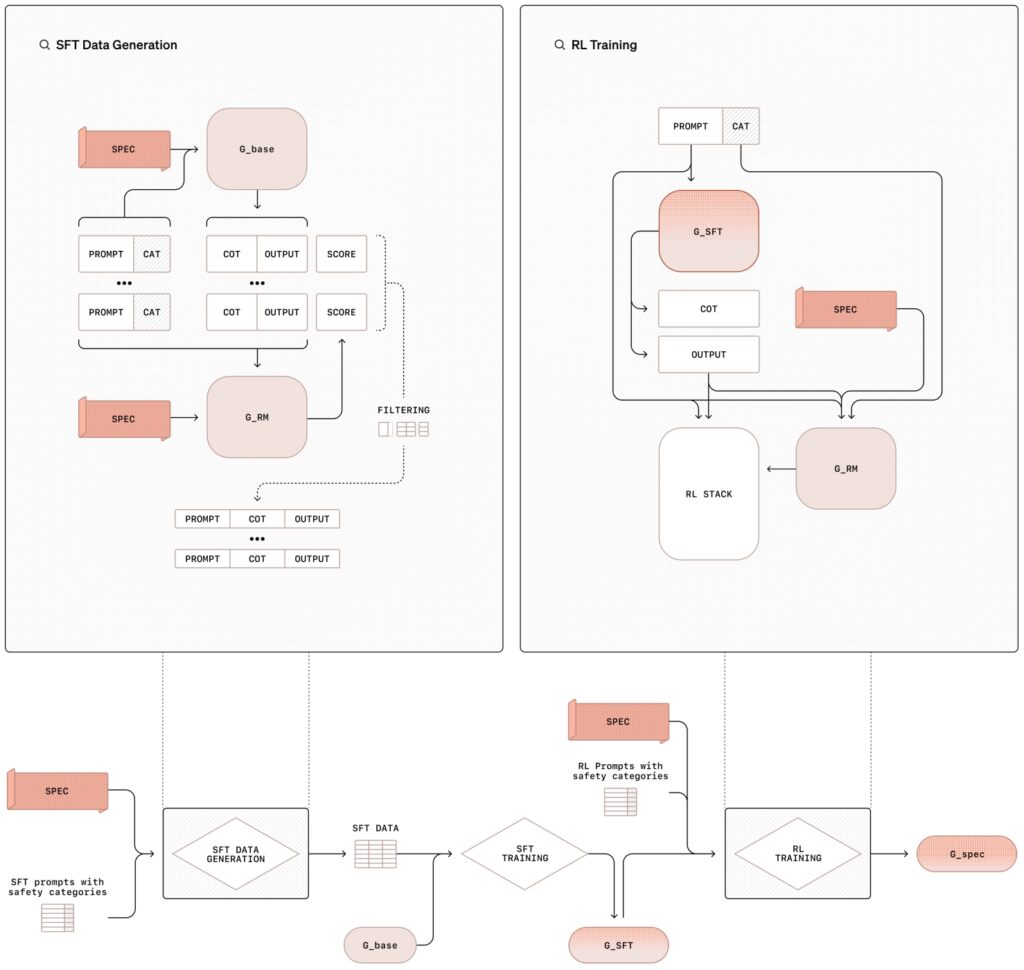 Ilustración de la metodología de alineación deliberada con ajuste fino supervisado (SFT) y aprendizaje por refuerzo (RL (Imagen: OpenAI)
Ilustración de la metodología de alineación deliberada con ajuste fino supervisado (SFT) y aprendizaje por refuerzo (RL (Imagen: OpenAI)
Una innovación clave en esta metodología es el uso de datos sintéticos (ejemplos generados por otros modelos de IA) que reemplazan la necesidad de etiquetado humano. conjuntos de datos. Esto no solo amplía el proceso de capacitación, sino que también garantiza un alto nivel de precisión al alinear los comportamientos del modelo con los requisitos de seguridad.
Como señalan los investigadores de OpenAI, “este método logra un cumplimiento de especificaciones muy preciso, basándose únicamente en datos generados por el modelo. Representa un enfoque escalable para la alineación.”
Abordar los jailbreaks y los rechazos excesivos
Dos de los problemas más persistentes en la seguridad de la IA son la vulnerabilidad del modelo a los intentos de jailbreak. y su tendencia a rechazar en exceso indicaciones benignas. Los jailbreak implican indicaciones adversas diseñadas para eludir las salvaguardas, a menudo disfrazadas o codificadas de manera que su intención sea menos evidente de inmediato. los ajustes de los caracteres utilizados para un mensaje pueden hacer jailbreak a los modelos fronterizos actuales.
Las negativas excesivas, por otro lado, ocurren cuando modelos demasiado cautelosos bloquean consultas inofensivas por precaución, frustrando a los usuarios y limitando la utilidad del sistema..
La alineación deliberativa está diseñada específicamente para abordar estos desafíos. Al equipar a los modelos con la capacidad de razonar a través de la intención y el contexto de las indicaciones, la metodología mejora su capacidad para resistir ataques adversarios mientras se mantienen. capacidad de respuesta a consultas legítimas.
Relacionado: Resultados del Índice de seguridad de IA 2024: OpenAI, Google, Meta y xAI se quedan cortos; Anthropic on Top
Por ejemplo, cuando se le presenta una solicitud encubierta para producir contenido dañino, un modelo entrenado con alineación deliberativa puede decodificar la entrada, hacer referencia a políticas de seguridad y proporcionar un rechazo razonado.
De manera similar, cuando se le hace una pregunta benigna sobre temas controvertidos, como la historia del desarrollo de armas nucleares, el modelo puede proporcionar información precisa sin violar las pautas de seguridad.
En los hallazgos de su investigación, OpenAI destacó que los modelos entrenados con alineación deliberativa son capaces de identificar la intención detrás de indicaciones codificadas o disfrazadas, razonando a través de sus políticas de seguridad para garantizar el cumplimiento.
Ejemplos del mundo real de alineación deliberativa en Acción
OpenAI ilustra las implicaciones prácticas de la alineación deliberativa a través de casos de uso del mundo real. En un ejemplo dado, un usuario solicita a un sistema de inteligencia artificial instrucciones detalladas sobre cómo falsificar una placa de estacionamiento.
El modelo identifica la intención de la solicitud como fraudulenta, hace referencia a la política de OpenAI contra permitir actividades ilegales y se niega a cumplir. Esta respuesta no solo evita el uso indebido, sino que también demuestra la capacidad del sistema para contextualizar y razonar dinámicamente sobre las políticas de seguridad.
En otro escenario, el modelo se enfrenta a un mensaje codificado que solicita asesoramiento ilícito. Utilizando sus capacidades de razonamiento, el sistema decodifica la entrada, compara sus especificaciones de seguridad y determina que la consulta viola las pautas éticas de OpenAI. Luego, el modelo proporciona una explicación de su rechazo, reforzando la transparencia en su proceso de toma de decisiones.
Los ejemplos resaltan la capacidad de la alineación deliberativa para equipar a los sistemas de IA con las herramientas necesarias para navegar en situaciones complejas y éticamente sensibles. garantizando tanto el cumplimiento de las políticas como la transparencia del usuario.
Relacionado: Meta insta a un bloqueo legal en la transición de OpenAI a una entidad con fines de lucro
Ampliando el alcance de Alineación deliberativa
La alineación deliberativa hace más que solo mitigar los riesgos; también abre la puerta para que los sistemas de IA funcionen con mayor transparencia y responsabilidad. Al permitir que los modelos articulen explícitamente su razonamiento, OpenAI ha introducido un marco donde los usuarios pueden comprender mejor la lógica detrás de las respuestas de una IA.
Esta transparencia es particularmente importante en aplicaciones de alto riesgo donde las consideraciones éticas o legales son primordiales, como la atención médica, las finanzas y la aplicación de la ley.
Por ejemplo, cuando los usuarios interactúan con modelos entrenado bajo alineación deliberativa, el razonamiento de la cadena de pensamiento no es solo interno sino que puede compartirse como parte del resultado del modelo.
Un usuario que busque una aclaración sobre por qué un modelo rechazó una solicitud puede recibir una explicación que haga referencia a políticas de seguridad específicas, junto con un desglose paso a paso de cómo el sistema llegó a su conclusión. Este nivel de detalle no solo genera confianza sino que también fomenta el uso responsable de las tecnologías de IA.
OpenAI enfatiza que la transparencia en la toma de decisiones de IA es esencial para generar confianza y garantizar el uso ético, con una alineación deliberativa que permite que los sistemas expliquen su comportamiento claramente.
Relacionado: Análisis profundo: cómo el nuevo modelo o1 de OpenAI engaña estratégicamente a los humanos
Datos sintéticos: la columna vertebral de Seguridad de IA escalable
Un componente crucial de la alineación deliberativa es el uso de datos sintéticos, que reemplazan los conjuntos de datos tradicionales etiquetados por humanos. Generar datos de entrenamiento a partir de sistemas de IA en lugar de depender de anotaciones humanas ofrece varias ventajas, entre ellas escalabilidad, rentabilidad y precisión.
Los datos sintéticos se pueden adaptar para abordar desafíos de seguridad específicos, lo que permite a OpenAI crear conjuntos de datos que se alinean estrechamente con sus prioridades operativas.
La canalización de datos sintéticos de OpenAI implica generar ejemplos de indicaciones y la cadena correspondiente. respuestas de pensamiento utilizando un modelo base de IA. Luego, el modelo de”juez”revisa y filtra estos ejemplos para garantizar que cumplan con los criterios de alineación y calidad deseados.
Una vez aprobados, los datos se utilizan en las fases supervisadas de ajuste fino y aprendizaje de refuerzo, donde entrena al modelo objetivo para razonar explícitamente sobre las políticas de seguridad.
“La generación de datos sintéticos nos permite escalar el entrenamiento de seguridad de la IA sin comprometer la calidad o la precisión de la alineación”, enfatizaron los investigadores de OpenAI.”Este enfoque aborda uno de los principales obstáculos en las metodologías de seguridad tradicionales, que a menudo dependen en gran medida del trabajo humano para la anotación de datos”.
Esta dependencia de datos sintéticos también garantiza la coherencia en la capacitación. Los anotadores humanos pueden introducir variabilidad debido a diferencias en la interpretación, pero los ejemplos generados por IA proporcionan una base estandarizada. Esta consistencia ayuda a que los modelos se generalicen mejor en una amplia gama de escenarios, desde controles de seguridad sencillos hasta dilemas éticos matizados.
Relacionado: OpenAI y Anduril forjan una asociación para la defensa con drones militares de EE. UU.
Superando a sus competidores en métricas clave
OpenAI ha probó la alineación deliberativa frente a los principales puntos de referencia de seguridad. Los resultados demuestran que los modelos entrenados con alineación deliberativa superan consistentemente a los competidores, logrando puntuaciones altas tanto en solidez como en capacidad de respuesta.
El o1 y los modelos relacionados tienen. ha sido probado rigurosamente contra sistemas de la competencia, incluidos GPT-4o, Gemini 1.5 Pro y Claude 3.5 Sonnet, en una variedad de métricas de seguridad. En StrongREJECT, que mide la resistencia de un modelo a jailbreaks adversarios, los modelos o1 de OpenAI obtuvieron consistentemente puntuaciones más altas, lo que refleja su capacidad avanzada para identificar y bloquear indicaciones dañinas.
o1 es competitivo en comparación con otros modelos líderes en los puntos de referencia que evalúan el contenido no permitido (WildChat), jailbreak (StrongREJECT), rechazos excesivos (XSTest), alucinaciones (SimpleQA) y sesgos (BBQ). Algunas solicitudes de API fueron
bloqueadas debido a la naturaleza confidencial del contenido. Estos casos se registran como”Bloqueados por filtros de seguridad”
en WildChat y se excluyen de otros puntos de referencia. Las barras de error se estiman utilizando un remuestreo de arranque en
el nivel 0,95. (Fuente: OpenAI)
Además, los modelos o1 se destacaron al equilibrar la seguridad con la capacidad de respuesta. En XSTest, que evalúa los rechazos excesivos, los modelos demostraron una tendencia reducida a rechazar indicaciones benignas mientras mantienen un estricto cumplimiento de las pautas de seguridad. Este rendimiento equilibrado es fundamental para garantizar que los sistemas de IA. siguen siendo útiles y accesibles sin comprometer los estándares éticos.
OpenAI dice que la alineación deliberativa mejora la seguridad de la IA al reducir los resultados dañinos y al mismo tiempo aumentar la precisión en la respuesta a interacciones benignas.
Relacionado: Cómo presionar”Detener”en ChatGPT puede neutralizar sus salvaguardias
Implicaciones más amplias para el desarrollo de la IA
La La introducción de la alineación deliberativa marca un punto de inflexión en la forma en que se entrenan e implementan los sistemas de IA en OpenAI y probablemente también en otros en el futuro.
Al incorporar un razonamiento explícito de seguridad en la funcionalidad principal de sus modelos, OpenAI ha creado un marco que no solo aborda los desafíos existentes sino que también anticipa riesgos futuros. A medida que los sistemas de IA se vuelven más capaces, aumenta el potencial de uso indebido o consecuencias no deseadas, lo que hace que las medidas de seguridad sólidas sean más críticas que nunca.
La alineación deliberativa también sirve como modelo para la comunidad de IA en general. Su dependencia de técnicas escalables como datos sintéticos y su énfasis en la transparencia proporcionan un modelo para otras organizaciones que buscan alinear sus sistemas de IA con valores éticos y sociales.