Google DeepMind ha lanzado FACTS Grounding, un nuevo punto de referencia diseñado para probar modelos de lenguaje de gran tamaño (LLM) en cuanto a su capacidad para generar respuestas objetivas y basadas en documentos.
La prueba comparativa, alojada en Kaggle, tiene como objetivo abordar uno de los desafíos más apremiantes en Inteligencia artificial: garantizar que los resultados de la IA se basen en los datos que se les proporcionan, en lugar de depender del conocimiento externo o introducir alucinaciones (información plausible pero incorrecta).
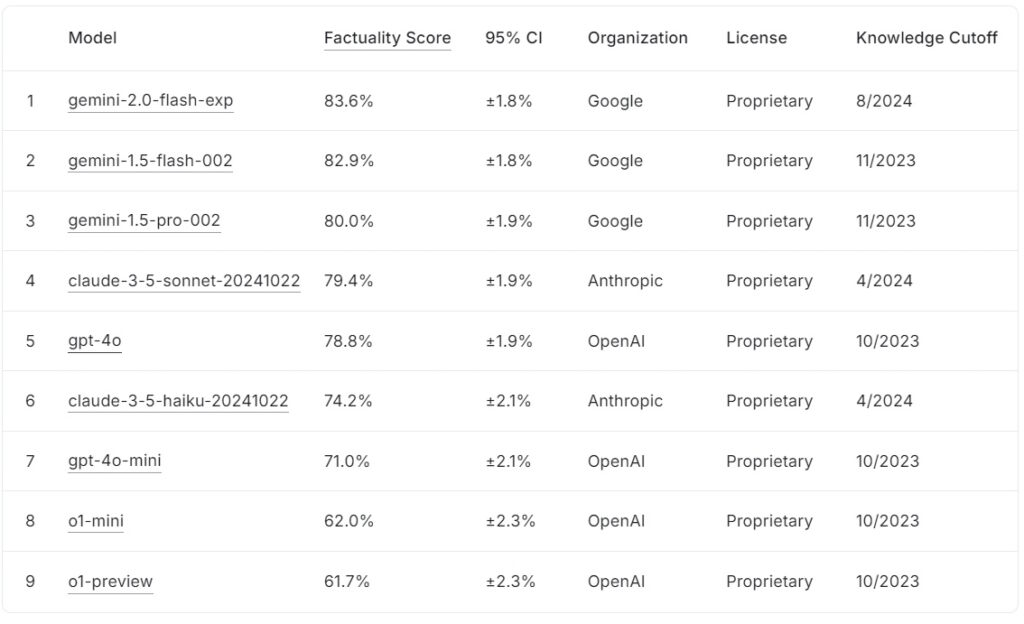
La tabla de clasificación de FACTS Grounding actual clasifica los modelos de lenguaje grandes según sus puntuaciones de factibilidad, con Google gemini-2.0-flash-exp lidera con un 83,6 % seguido de cerca por gemini-1.5-flash-002 con 82,9% y gemini-1.5-pro-002 con 80,0%.
claude-3.5-soneto-20241022 de Anthropic ocupa el cuarto lugar con un 79,4%, mientras que OpenAI gpt-4o logra un 78,8%, ubicándose en quinto lugar. Más abajo en la lista, claude-3.5-haiku-20241022 de Anthropic obtiene un 74,2%, seguido de gpt-4o-mini con un 71,0%.
Los modelos más pequeños de OpenAI, o1-mini y o1-preview, completan la clasificación con un 62,0% y 61,7%, respectivamente.
 Fuente: Kaggle
Fuente: Kaggle
FACTS Grounding se distingue por requerir respuestas extensas que sinteticen documentos de entrada detallados, lo que hace Es uno de los puntos de referencia más rigurosos para la factibilidad de la IA hasta la fecha.
FACTS Grounding representa un desarrollo crítico para la industria de la IA, particularmente en aplicaciones donde la confianza y la precisión son esenciales. Al evaluar los LLM en dominios como medicina, derecho, finanzas, comercio minorista y tecnología, el punto de referencia sienta las bases para mejorar la confiabilidad de la IA en escenarios del mundo real.
Según el equipo de investigación de DeepMind, el”punto de referencia mide la capacidad de los LLM para generar respuestas basadas exclusivamente en el contexto proporcionado… incluso cuando el contexto entra en conflicto con el conocimiento previo a la capacitación”.
Conjunto de datos para la complejidad del mundo real
FACTS Grounding consta de 1.719 ejemplos, seleccionados por anotadores humanos para garantizar la relevancia y la diversidad. Estos ejemplos se extraen de información detallada. documentos que abarcan hasta 32 000 tokens, equivalentes a aproximadamente 20 000 palabras
Cada tarea desafía a los LLM a realizar resúmenes, generación de preguntas y respuestas o reescritura de contenido, con instrucciones estrictas para hacer referencia solo a los datos proporcionados. que requieren creatividad, razonamiento matemático o interpretación experta, centrándose en cambio en probar la capacidad de un modelo para sintetizar y articular información compleja.
Para mantener la transparencia y evitar el sobreajuste, DeepMind dividió el conjunto de datos en dos segmentos: 860 ejemplos públicos disponibles para uso externo y 859 ejemplos privados reservados para evaluaciones de clasificación.
Esta estructura dual salvaguarda la integridad del punto de referencia al tiempo que fomenta la colaboración de los desarrolladores de IA en todo el mundo.”Evaluamos rigurosamente nuestros evaluadores automáticos basándose en datos de pruebas disponibles para validar su desempeño en nuestra tarea”, señala el equipo de investigación, destacando el diseño cuidadoso que sustenta FACTS Grounding.
Juzgar la precisión con pares Modelos de IA
A diferencia de los puntos de referencia convencionales, FACTS Grounding emplea un proceso de revisión por pares que involucra tres LLM avanzados: Gemini 1.5 Pro, GPT-4o y Claude. 3.5 Sonnet estos modelos sirven como jueces, calificando las respuestas según dos criterios críticos: elegibilidad y precisión objetiva.
Las respuestas primero deben pasar una verificación de elegibilidad para confirmar que abordan la consulta del usuario de manera significativa. evaluados por su base en el material original, con puntuaciones agregadas en los tres modelos para minimizar el sesgo.
Los investigadores de DeepMind enfatizan la importancia de esta evaluación de múltiples capas, afirmando, “Las métricas que se centran en evaluar la factibilidad del texto generado… pueden eludirse ignorando la intención detrás de la solicitud del usuario. Al dar respuestas más breves que evaden transmitir información exhaustiva… es posible lograr una puntuación alta de factibilidad sin proporcionar una respuesta útil”.
El uso de múltiples plantillas de puntuación, incluidos enfoques de nivel de intervalo y basados en JSON , garantiza aún más la alineación con el juicio humano y la adaptabilidad a diversas tareas.
Afrontar el desafío de las alucinaciones de IA
Las alucinaciones de IA se encuentran entre los obstáculos más importantes para la generalización adopción de LLM en campos críticos, donde los modelos generan resultados que parecen plausibles pero que en realidad son incorrectos, plantean riesgos graves en dominios como la atención médica, el análisis legal y los informes financieros.
FACTS Grounding aborda directamente este problema. al imponer un estricto cumplimiento de los datos de entrada proporcionados. Este enfoque no solo evalúa la capacidad de un modelo para evitar la introducción de falsedades, sino que también garantiza que los resultados permanezcan alineados con la intención del usuario.
A diferencia de puntos de referencia como. SimpleQA de OpenAI, que mide la factibilidad en la recuperación de datos de entrenamiento, FACTS Grounding prueba qué tan bien los modelos sintetizan nueva información.
El artículo de investigación subraya esta distinción: “Garantizar la precisión de los hechos al generar respuestas de LLM es un desafío. Los principales desafíos en la factualidad de LLM son el modelado (es decir, arquitectura, capacitación e inferencia) y la medición (es decir, metodología de evaluación, datos y métricas)”.
Desafíos técnicos y diseño de referencia
La complejidad de las entradas de formato largo presenta desafíos técnicos únicos, particularmente en el diseño de métodos de evaluación automatizados que puedan evaluar con precisión dichas respuestas en las que
FACTS Grounding se basa. procesos computacionalmente intensivos para validar las respuestas, empleando criterios rigurosos para garantizar la confiabilidad. La inclusión de múltiples modelos de jueces mitiga los posibles sesgos y fortalece el marco de evaluación general.
El equipo de investigación destaca la importancia de descalificar respuestas vagas o irrelevantes. señalando:”Descalificar respuestas no elegibles conduce a una reducción… ya que estas respuestas se tratan como inexactas”.
Esta estricta aplicación de la relevancia garantiza que los modelos no sean recompensados por eludir el espíritu de la tarea.
Fomentar la colaboración a través de la transparencia
La decisión de DeepMind de albergar FACTS Grounding en Kaggle refleja su compromiso de fomentar la colaboración en toda la industria de la IA. Al hacer accesible el segmento público del conjunto de datos, el proyecto invita a los investigadores y desarrolladores de IA a evaluar sus modelos frente a un estándar sólido y contribuir a mejorar los puntos de referencia de factibilidad.
Este enfoque se alinea con los objetivos más amplios de transparencia y progreso compartido en IA, asegurando que las mejoras en precisión y conexión no se limiten a una sola organización.
Diferenciarse de otras Puntos de referencia
HECHOS Grounding se distingue de otros puntos de referencia por su enfoque en la base en insumos recién introducidos en lugar de conocimientos previamente entrenados.
Mientras que los puntos de referencia como SimpleQA de OpenAI evalúan qué tan bien un modelo recupera y utiliza información de su corpus de entrenamiento, FACTS Grounding evalúa los modelos en función de su capacidad para sintetizar y articular respuestas basadas exclusivamente en los datos proporcionados.
Esta distinción es crucial para abordar los desafíos que plantean las ideas preconcebidas del modelo o los sesgos inherentes. Al aislar la tarea de procesar entradas externas, FACTS Grounding garantiza que las métricas de rendimiento reflejen la capacidad de un modelo para operar en escenarios dinámicos del mundo real en lugar de simplemente regurgitar información aprendida previamente.
Como explica DeepMind en su artículo de investigación, el punto de referencia está diseñado para evaluar la capacidad de los LLM para gestionar consultas complejas y de formato largo con base objetiva, simulando tareas relevantes para aplicaciones del mundo real.
Métodos alternativos para conectar a tierra los LLM
Varios métodos ofrecen características de conexión a tierra similares a FACTS Grounding, cada uno con sus fortalezas y debilidades. Estos métodos tienen como objetivo mejorar los resultados de LLM, ya sea mejorando su acceso a información precisa o refinando sus procesos de capacitación y alineación.
Generación de recuperación aumentada (RAG)
Generación de recuperación aumentada (RAG) mejora la precisión de los resultados de LLM al recuperar dinámicamente información relevante de bases de datos o bases de conocimiento externas e incorporarla a las respuestas del modelo. En lugar de volver a capacitar a todo el LLM, RAG funciona interceptando las indicaciones de los usuarios y enriqueciéndolas con información actualizada.
Las implementaciones avanzadas de RAG a menudo aprovechan la recuperación basada en entidades, donde los datos asociados con entidades específicas se unifican para proporcionan un contexto muy relevante para las respuestas de LLM.
RAG normalmente utiliza técnicas de búsqueda semántica para recuperar información. Los documentos o sus fragmentos se indexan en función de sus incrustaciones semánticas, lo que permite que el sistema haga coincidir la consulta del usuario con las entradas más contextualmente relevantes. Este enfoque garantiza que los LLM generen respuestas informadas con los datos más recientes y pertinentes.
La eficacia de RAG depende en gran medida de la calidad y organización de la base de conocimientos, así como de la precisión de los algoritmos de recuperación. Mientras que FACTS Grounding evalúa la capacidad de un LLM para permanecer anclado a un documento de contexto proporcionado, RAG complementa esto permitiendo a los LLM ampliar su conocimiento de forma dinámica, basándose en fuentes externas para mejorar la factibilidad y la relevancia.
Destilación del conocimiento
La destilación del conocimiento implica transferir el capacidades de un modelo grande y complejo (denominado profesor) a un modelo más pequeño y específico para tareas (el estudiante). Este método mejora la eficiencia al tiempo que conserva gran parte de la precisión del modelo original. Se utilizan dos enfoques principales en la destilación de conocimientos:
Destilación de conocimientos basada en respuestas: se centra en replicar los resultados del modelo docente, garantizando que el modelo de los estudiantes produzca resultados similares para determinadas entradas.
Destilación de conocimiento basada en características: extrae representaciones y características internas del modelo del profesor, lo que permite que el modelo del estudiante replique conocimientos más profundos.
Al refinar lo más pequeño modelos, la destilación del conocimiento permite la implementación de LLM en entornos con recursos limitados sin pérdidas significativas en el rendimiento. A diferencia de FACTS Grounding, que evalúa la fidelidad de la conexión a tierra, la destilación del conocimiento se preocupa más por escalar las capacidades de LLM y optimizarlas para tareas específicas.
Ajuste con conjuntos de datos fundamentados
El ajuste implica adaptar personas previamente capacitadas LLM en dominios o tareas específicas capacitándolos en conjuntos de datos seleccionados donde la base objetiva es fundamental. Por ejemplo, se pueden utilizar conjuntos de datos que comprenden literatura científica o registros históricos para mejorar la capacidad del modelo para producir resultados precisos y específicos de un dominio. Esta técnica mejora el rendimiento del LLM para aplicaciones especializadas, como el análisis de documentos médicos o legales.
Sin embargo, el ajuste requiere muchos recursos y corre el riesgo de un olvido catastrófico, donde el modelo pierde el conocimiento adquirido durante su entrenamiento inicial. FACTS Grounding se centra en probar la factualidad en contextos aislados, mientras que el ajuste busca mejorar el rendimiento básico de los LLM en áreas específicas.
Aprendizaje por refuerzo con retroalimentación humana (RLHF)
Aprendizaje por refuerzo con retroalimentación humana (RLHF) incorpora las preferencias humanas en el proceso de formación de los LLM. Al entrenar iterativamente el modelo para alinear sus respuestas con la retroalimentación humana, RLHF refina la calidad, la factibilidad y la utilidad de los resultados. Los evaluadores humanos califican los resultados del LLM y estos puntajes se utilizan como señales para optimizar el modelo.
RLHF ha tenido especial éxito en mejorar la satisfacción del usuario y garantizar que las respuestas generadas estén alineadas con las expectativas humanas. Mientras que FACTS Grounding evalúa los fundamentos fácticos en comparación con documentos específicos, RLHF enfatiza la alineación de los resultados del LLM con los valores y preferencias humanos.
Seguimiento de instrucciones y aprendizaje en contexto
El seguimiento de instrucciones y el aprendizaje en contexto implican demostrar conexión a tierra para los LLM a través de ejemplos cuidadosamente elaborados dentro del mensaje del usuario. Estos métodos se basan en la capacidad del modelo para generalizar a partir de una demostración de unos pocos disparos. Si bien este enfoque puede generar mejoras rápidas, es posible que no logre el mismo nivel de calidad de conexión a tierra que los métodos de ajuste o basados en recuperación.
Herramientas y API externas
Los LLM se pueden integrar con herramientas y API externas para proporcionar acceso en tiempo real a datos externos, mejorando significativamente sus capacidades de conexión a tierra. Los ejemplos incluyen:
Capacidad de navegación: permite a los LLM acceder y recuperar información en tiempo real de la web para responder preguntas específicas o actualizar sus conocimientos.
Llamadas API: permite a los LLM interactuar con bases de datos o servicios estructurados, enriqueciendo las respuestas con información precisa y actualizada.
Estas herramientas amplían la utilidad de los LLM al conectarlos con datos reales.-conocimiento mundial fuentes, mejorando su capacidad para generar resultados precisos y fundamentados. Mientras que FACTS Grounding evalúa la fidelidad de la base interna, las herramientas externas proporcionan un medio alternativo para ampliar y verificar la factualidad.
Model Grounding de código abierto Opciones
Hay varias implementaciones de código abierto disponibles para los métodos de conexión a tierra alternativos discutidos anteriormente:
Implicaciones para aplicaciones de alto riesgo
La importancia de respuestas de IA precisas y fundamentadas se vuelve particularmente evidente en aplicaciones de alto riesgo, como las médicas. diagnósticos, revisiones legales y análisis financieros. En estos contextos, incluso las imprecisiones menores pueden tener consecuencias importantes, lo que hace que la confiabilidad de los resultados generados por la IA sea un requisito no negociable.
HECHOS El énfasis de Grounding en la factualidad y el cumplimiento del material original garantiza que los modelos se prueben en condiciones que reflejan fielmente las demandas del mundo real.
Por ejemplo, en contextos médicos, un LLM encargado de Al resumir los registros de los pacientes se debe evitar introducir errores que puedan desinformar las decisiones de tratamiento. De manera similar, en el ámbito jurídico, generar resúmenes o análisis de jurisprudencia requiere una fundamentación precisa en los documentos proporcionados.
HECHOS Grounding no solo evalúa la capacidad de los modelos para cumplir con estos estrictos requisitos, sino que también establece un punto de referencia al que deben aspirar los desarrolladores al crear sistemas adecuados para dichas aplicaciones.
Expansión el conjunto de datos de FACTS y las direcciones futuras
DeepMind ha posicionado a FACTS Grounding como un”punto de referencia vivo”que evolucionará junto con los avances en IA. Es probable que las actualizaciones futuras amplíen el conjunto de datos para incluir nuevos dominios y tipos de tareas, lo que garantiza su relevancia continua a medida que crecen las capacidades de LLM.
Además, la introducción de plantillas de evaluación más diversas podría mejorar aún más la solidez del proceso de puntuación, abordando casos extremos y reduciendo los sesgos residuales.
Como reconoce el equipo de investigación de DeepMind, ningún punto de referencia puede resumir completamente las complejidades de las aplicaciones del mundo real. Sin embargo, al iterar en FACTS Grounding e involucrar a la comunidad de IA en general, el proyecto apunta a elevar el nivel. factibilidad y fundamento en los sistemas de IA.
Como afirma el equipo de DeepMind, “La factualidad y la conexión a tierra se encuentran entre los factores clave que darán forma al éxito y la utilidad futuros de los LLM y los sistemas de inteligencia artificial más amplios, y nuestro objetivo es crecer e iterar FACTS Grounding a medida que avanza el campo. continuamente subiendo el listón.”