Το OpenAI εισήγαγε τη διαβουλευτική ευθυγράμμιση, μια μεθοδολογία που στοχεύει στην ενσωμάτωση της λογικής ασφάλειας στην ίδια τη λειτουργία των συστημάτων τεχνητής νοημοσύνης. Σχεδιασμένη για να αντιμετωπίζει επίμονες προκλήσεις στην ασφάλεια της τεχνητής νοημοσύνης, η στοχαστική ευθυγράμμιση επιτρέπει στα μοντέλα τεχνητής νοημοσύνης να αναφέρονται ρητά και να αιτιολογούν τις πολιτικές ασφάλειας που καθορίζονται από τον άνθρωπο κατά τη διάρκεια αλληλεπιδράσεων σε πραγματικό χρόνο.
Σύμφωνα με το OpenAI, η προσέγγιση αντιπροσωπεύει μια σημαντική εξέλιξη στην εκπαίδευση για την ασφάλεια της τεχνητής νοημοσύνης, πέρα από την εξάρτηση από προ-κωδικοποιημένα σύνολα δεδομένων σε συστήματα που αξιολογούν δυναμικά και ανταποκρίνονται σε προτροπές με αποφάσεις που ενημερώνονται με βάση τα συμφραζόμενα.
Σχετικά: Η OpenAI αποκαλύπτει νέο μοντέλο o3 με Δραστικά Βελτιωμένες Δεξιότητες Συλλογισμού
Αυτές οι μέθοδοι, ενώ είναι θεμελιώδες, μπορεί να αφήσει κενά όταν τα μοντέλα αντιμετωπίζουν νέα ή πολύπλοκα σενάρια που δεν εμπίπτουν στα δεδομένα εκπαίδευσής τους. Η διαβουλευτική ευθυγράμμιση του OpenAI προσφέρει μια λύση εξοπλίζοντας συστήματα τεχνητής νοημοσύνης ώστε να εμπλέκονται ενεργά με προδιαγραφές ασφαλείας, διασφαλίζοντας ότι οι απαντήσεις βαθμονομούνται στις ηθικές, νομικές και πρακτικές απαιτήσεις του περιβάλλοντός τους.
Σύμφωνα με τους ερευνητές του OpenAI, «[Deliberative ευθυγράμμιση] είναι η πρώτη προσέγγιση που διδάσκει απευθείας σε ένα μοντέλο το κείμενο των προδιαγραφών ασφαλείας του και εκπαιδεύει το μοντέλο να μελετά αυτές τις προδιαγραφές στο χρόνος συμπερασμάτων.”
Διδάσκοντας συστήματα τεχνητής νοημοσύνης να σκέφτονται την ασφάλεια
Το διαβουλευτική μεθοδολογία ευθυγράμμισης περιλαμβάνει μια εκπαιδευτική διαδικασία δύο σταδίων που συνδυάζει εποπτευόμενη λεπτομέρεια (SFT) και ενισχυτική μάθηση (RL), που υποστηρίζεται από τη δημιουργία συνθετικών δεδομένων. Αυτή η δομημένη προσέγγιση όχι μόνο διδάσκει στα μοντέλα το περιεχόμενο των πολιτικών ασφαλείας αλλά και τους εκπαιδεύει να εφαρμόζουν αυτές τις οδηγίες δυναμικά κατά τη λειτουργία τους.
Στη φάση της εποπτευόμενης λεπτομέρειας (SFT), τα μοντέλα τεχνητής νοημοσύνης εκτίθενται σε ένα επιμελημένο σύνολο δεδομένων προτροπών σε συνδυασμό με λεπτομερείς απαντήσεις που αναφέρονται ρητά στις εσωτερικές προδιαγραφές ασφαλείας του OpenAI.
Αυτά chain-of-tought (CoT) παραδείγματα δείχνουν πώς τα μοντέλα πρέπει να προσεγγίζουν διάφορα σενάρια, αναλύοντας πολύπλοκα μηνύματα σε μικρότερα, διαχειρίσιμα βήματα, ενώ διασταυρώνονται οι οδηγίες ασφαλείας. Στη συνέχεια, τα αποτελέσματα αξιολογούνται από ένα εσωτερικό σύστημα τεχνητής νοημοσύνης, που συχνά αναφέρεται ως «κριτής», το οποίο αξιολογεί την τήρησή τους στα πρότυπα πολιτικής.
Σχετικά: Ο Διευθύνων Σύμβουλος του OpenAI, Sam Altman, ανήκει και πωλείται. Προηγουμένως Άγνωστο Ποντάρισμα OpenAI
Η φάση της ενίσχυσης εκμάθησης ενισχύει περαιτέρω τις δυνατότητες του μοντέλου βελτιστοποιώντας τη διαδικασία συλλογισμού του χρησιμοποιώντας σχόλια από τον κριτή μοντέλο, το σύστημα βελτιώνει επαναληπτικά την ικανότητά του να συλλογίζεται μέσω αποχρώσεων ή διφορούμενων προτροπών, ευθυγραμμίζοντας πιο στενά με τις ηθικές και λειτουργικές προτεραιότητες του OpenAI.
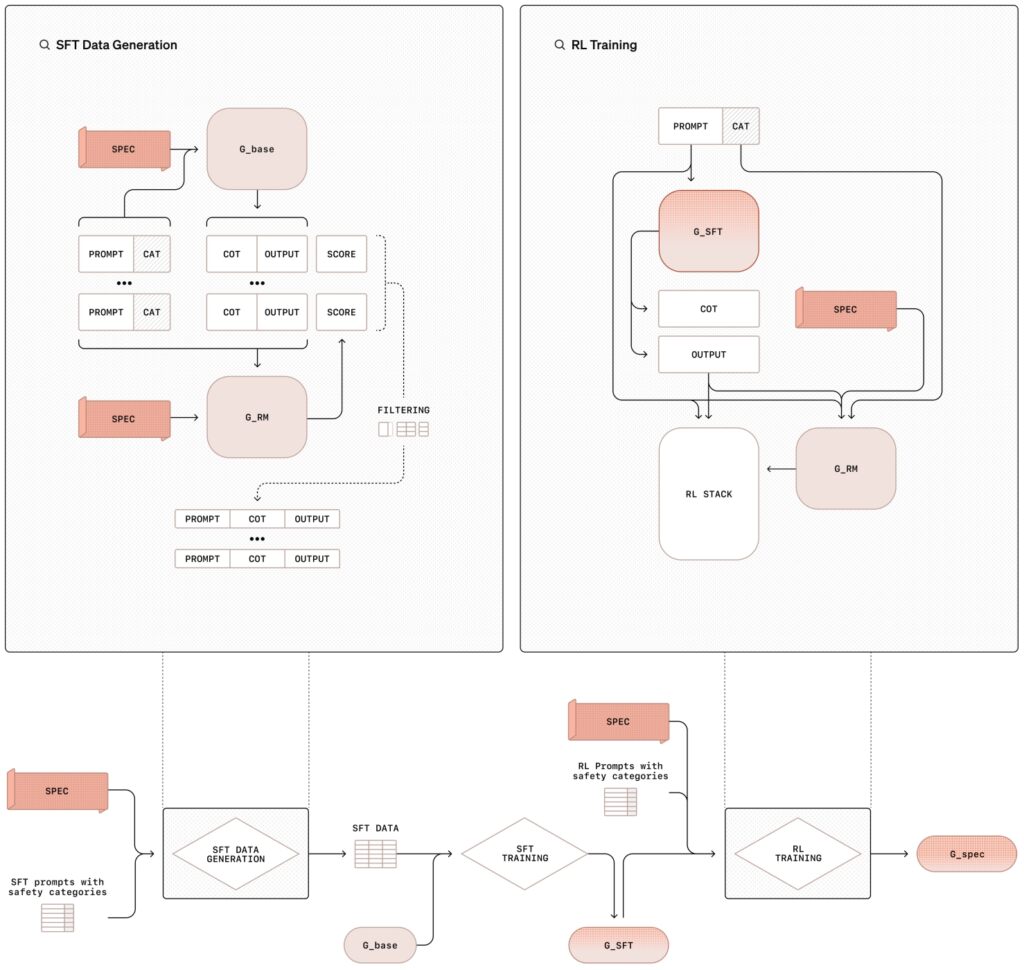 Απεικόνιση της μεθοδολογίας σκόπιμης ευθυγράμμισης με εποπτευόμενη τελειοποίηση (SFT) και ενισχυτική μάθηση (RL). OpenAI)
Απεικόνιση της μεθοδολογίας σκόπιμης ευθυγράμμισης με εποπτευόμενη τελειοποίηση (SFT) και ενισχυτική μάθηση (RL). OpenAI)
Μια βασική καινοτομία σε αυτήν τη μεθοδολογία είναι η χρήση συνθετικών δεδομένων—παραδείγματα που δημιουργούνται από άλλα μοντέλα τεχνητής νοημοσύνης—που αντικαθιστά την ανάγκη για σύνολα δεδομένων με επισήμανση ανθρώπου. Αυτό όχι μόνο κλιμακώνει τη διαδικασία εκπαίδευσης αλλά εξασφαλίζει επίσης υψηλό επίπεδο ακρίβειας στην ευθυγράμμιση των συμπεριφορών του μοντέλου με τις απαιτήσεις ασφάλειας.
Όπως σημειώνουν οι ερευνητές του OpenAI, «Αυτή η μέθοδος επιτυγχάνει εξαιρετικά ακριβή τήρηση προδιαγραφών, βασιζόμενη μόνο σε δεδομένα που δημιουργούνται από μοντέλα. Αντιπροσωπεύει μια επεκτάσιμη προσέγγιση για την ευθυγράμμιση.”
Αντιμετώπιση jailbreaks και υπεράρνησης
Δύο από τα πιο επίμονα ζητήματα στην ασφάλεια της τεχνητής νοημοσύνης είναι η ευπάθεια του μοντέλου σε απόπειρες jailbreak και η τάση του να απορρίπτει υπερβολικά τις καλοήθεις προτροπές συγκαλυμμένα ή κωδικοποιημένα με τρόπους που κάνουν την πρόθεσή τους λιγότερο άμεσα εμφανή Οι ερευνητές τεκμηρίωσαν πρόσφατα πώς ακόμη και μικρές τροποποιήσεις των χαρακτήρων που χρησιμοποιούνται για μια προτροπή μπορούν να παραβιάσουν τα τρέχοντα μοντέλα συνόρων.
Οι υπερβολικές αρνήσεις, από την άλλη πλευρά, συμβαίνουν όταν είναι υπερβολικά. προσεκτικά μοντέλα μπλοκάρουν τα αβλαβή ερωτήματα λόγω μεγάλης προσοχής, απογοητεύοντας τους χρήστες και περιορίζοντας το σύστημα χρησιμότητα.
Η διαβουλευτική ευθυγράμμιση έχει σχεδιαστεί ειδικά για την αντιμετώπιση αυτών των προκλήσεων Εξοπλίζοντας τα μοντέλα με την ικανότητα να συλλογίζονται μέσω της πρόθεσης και του πλαισίου των προτροπών, η μεθοδολογία ενισχύει την ικανότητά τους να αντιστέκονται σε αντίθετες επιθέσεις διατηρώντας παράλληλα την ανταπόκριση σε νόμιμα ερωτήματα..
Σχετικά: Αποτελέσματα AI Safety Index 2024: OpenAI, Google, Meta, xAI Fall Short; Anthropic on Top
Για παράδειγμα, όταν παρουσιάζεται ένα συγκεκαλυμμένο αίτημα για παραγωγή επιβλαβούς περιεχομένου, ένα μοντέλο που έχει εκπαιδευτεί με στοχαστική ευθυγράμμιση μπορεί να αποκωδικοποιήσει τα δεδομένα εισόδου, να αναφέρει τις πολιτικές ασφαλείας και να παράσχει αιτιολογημένη άρνηση.
Ομοίως, όταν τίθεται μια καλοήθης ερώτηση σχετικά με αμφιλεγόμενα θέματα, όπως η ιστορία της ανάπτυξης πυρηνικών όπλων, το μοντέλο μπορεί να παρέχει ακριβείς πληροφορίες χωρίς να παραβιάζει τις κατευθυντήριες γραμμές για την ασφάλεια.
Στα ερευνητικά τους ευρήματα, Το OpenAI τόνισε ότι τα μοντέλα που έχουν εκπαιδευτεί με στοχαστική ευθυγράμμιση είναι σε θέση να προσδιορίσουν την πρόθεση πίσω από κωδικοποιημένες ή συγκαλυμμένες προτροπές, συλλογίζοντας μέσω των πολιτικών ασφαλείας τους για να εξασφαλίσουν συμμόρφωση.
Πραγματικά παραδείγματα διαβουλευτικής ευθυγράμμισης σε δράση
Το OpenAI απεικονίζει τις πρακτικές συνέπειες της διαβουλευτικής ευθυγράμμισης μέσω πραγματικών περιπτώσεων χρήσης. Σε ένα δεδομένο παράδειγμα, ένας χρήστης ζητά από ένα σύστημα τεχνητής νοημοσύνης λεπτομερείς οδηγίες σχετικά με την παραχάραξη μιας πινακίδας στάθμευσης.
Το μοντέλο προσδιορίζει την πρόθεση του αιτήματος ως δόλια, αναφέρεται στην πολιτική του OpenAI κατά της ενεργοποίησης της παράνομης δραστηριότητας και αρνείται να συμμορφωθεί. Αυτή η απόκριση όχι μόνο αποτρέπει την κακή χρήση, αλλά καταδεικνύει επίσης την ικανότητα του συστήματος να ενσωματώνει και να αιτιολογεί δυναμικά τις πολιτικές ασφάλειας.
Σε ένα άλλο σενάριο, το μοντέλο αντιμετωπίζει μια κωδικοποιημένη προτροπή που ζητά παράνομες συμβουλές. Χρησιμοποιώντας τις δυνατότητες συλλογιστικής του, το σύστημα αποκωδικοποιεί την είσοδο, διασταυρώνει τις προδιαγραφές ασφαλείας του και προσδιορίζει ότι το ερώτημα παραβιάζει τις δεοντολογικές οδηγίες του OpenAI. Στη συνέχεια, το μοντέλο παρέχει μια εξήγηση της άρνησής του, ενισχύοντας τη διαφάνεια στη διαδικασία λήψης αποφάσεων.
Τα παραδείγματα υπογραμμίζουν την ικανότητα της στοχαστικής ευθυγράμμισης για τον εξοπλισμό των συστημάτων AI με τα εργαλεία που απαιτούνται για την πλοήγηση σε περίπλοκες και ηθικά ευαίσθητες καταστάσεις. διασφαλίζοντας τόσο τη συμμόρφωση με τις πολιτικές όσο και τη διαφάνεια των χρηστών.
Σχετικά: Η Meta Urges Legal Block on Η μετάβαση του OpenAI σε κερδοσκοπική οντότητα
Επέκταση του εύρους της διαβουλευτικής ευθυγράμμισης
Η διαβουλευτική ευθυγράμμιση κάνει περισσότερα από απλώς τον μετριασμό των κινδύνων. Ανοίγει επίσης την πόρτα για τα συστήματα τεχνητής νοημοσύνης να λειτουργούν με μεγαλύτερη διαφάνεια και υπευθυνότητα. Επιτρέποντας στα μοντέλα να διατυπώνουν ρητά το σκεπτικό τους, το OpenAI εισήγαγε ένα πλαίσιο όπου οι χρήστες μπορούν να κατανοήσουν καλύτερα τη λογική πίσω από τις απαντήσεις ενός AI.
Αυτή η διαφάνεια είναι ιδιαίτερα σημαντική σε εφαρμογές υψηλού κινδύνου όπου οι ηθικοί ή νομικοί παράγοντες είναι υψίστης σημασίας, όπως η υγειονομική περίθαλψη, τα οικονομικά και η επιβολή του νόμου.
Για παράδειγμα, όταν οι χρήστες αλληλεπιδρούν με μοντέλα. Εκπαιδευμένο υπό διασκεδαστική ευθυγράμμιση, ο συλλογισμός της αλυσίδας σκέψης δεν είναι μόνο εσωτερικός, αλλά μπορεί να μοιραστεί ως μέρος της παραγωγής του μοντέλου.
Ένας χρήστης που ζητά διευκρίνιση σχετικά με το γιατί ένα μοντέλο απέρριψε ένα αίτημα μπορεί να λάβει μια εξήγηση που αναφέρεται σε συγκεκριμένες πολιτικές ασφάλειας, μαζί με μια αναλυτική ανάλυση βήμα προς βήμα του τρόπου με τον οποίο το σύστημα κατέληξε στο συμπέρασμα. Αυτό το επίπεδο λεπτομέρειας όχι μόνο οικοδομεί εμπιστοσύνη αλλά ενθαρρύνει επίσης την υπεύθυνη χρήση των τεχνολογιών τεχνητής νοημοσύνης.
Το OpenAI τονίζει ότι η διαφάνεια στη λήψη αποφάσεων τεχνητής νοημοσύνης είναι απαραίτητη για την οικοδόμηση εμπιστοσύνης και τη διασφάλιση ηθικής χρήσης, με τη διαβουλευτική ευθυγράμμιση που επιτρέπει στα συστήματα να εξηγούν τη συμπεριφορά τους ξεκάθαρα.
Σχετικά: Deep Dive: Πώς το νέο μοντέλο o1 του OpenAI εξαπατά τους ανθρώπους Στρατηγικά
Συνθετικά δεδομένα: Η ραχοκοκαλιά της κλιμακούμενης ασφάλειας τεχνητής νοημοσύνης
Ένα κρίσιμο συστατικό της στοχευτικής ευθυγράμμισης είναι η χρήση συνθετικών δεδομένων, τα οποία αντικαθιστούν την παραδοσιακή ανθρώπινη ετικέτα σύνολα δεδομένων. Η δημιουργία δεδομένων εκπαίδευσης από συστήματα τεχνητής νοημοσύνης αντί να βασίζεται σε ανθρώπινους σχολιασμούς προσφέρει πολλά πλεονεκτήματα, όπως η επεκτασιμότητα, η αποδοτικότητα κόστους και η ακρίβεια.
Τα συνθετικά δεδομένα μπορούν να προσαρμοστούν για την αντιμετώπιση συγκεκριμένων προκλήσεων ασφάλειας, επιτρέποντας στο OpenAI να δημιουργεί σύνολα δεδομένων που ευθυγραμμίζονται στενά με τις επιχειρησιακές προτεραιότητές του.
Ο αγωγός συνθετικών δεδομένων του OpenAI περιλαμβάνει τη δημιουργία παραδειγμάτων προτροπών και αντίστοιχης αλυσίδας.-αποκρίσεις σκέψης χρησιμοποιώντας ένα βασικό μοντέλο AI. Αυτά τα παραδείγματα στη συνέχεια εξετάζονται και φιλτράρονται από το μοντέλο”κριτής”για να διασφαλιστεί ότι πληρούν τα επιθυμητά κριτήρια ποιότητας και ευθυγράμμισης.
Μόλις εγκριθούν, τα δεδομένα χρησιμοποιούνται στις εποπτευόμενες φάσεις λεπτομέρειας και ενίσχυσης εκμάθησης, όπου εκπαιδεύει το μοντέλο-στόχο να αιτιολογεί ρητά τις πολιτικές ασφάλειας.
“Η παραγωγή συνθετικών δεδομένων μας δίνει τη δυνατότητα να κλιμακώνουμε την εκπαίδευση σε θέματα ασφάλειας τεχνητής νοημοσύνης χωρίς συμβιβασμούς στην ποιότητα ή ακρίβεια ευθυγράμμισης», τόνισαν οι ερευνητές του OpenAI.”Αυτή η προσέγγιση αντιμετωπίζει ένα από τα βασικά σημεία συμφόρησης στις παραδοσιακές μεθοδολογίες ασφάλειας, οι οποίες συχνά βασίζονται σε μεγάλο βαθμό στην ανθρώπινη εργασία για τον σχολιασμό δεδομένων”.
Αυτή η εξάρτηση από συνθετικά δεδομένα διασφαλίζει επίσης τη συνέπεια στην εκπαίδευση. Οι ανθρώπινοι σχολιαστές ενδέχεται να εισάγουν μεταβλητότητα λόγω σε διαφορές στην ερμηνεία, αλλά τα παραδείγματα που δημιουργούνται από την τεχνητή νοημοσύνη παρέχουν μια τυποποιημένη γραμμή βάσης Αυτή η συνέπεια βοηθά τα μοντέλα να γενικεύονται καλύτερα σε ένα ευρύ φάσμα σεναρίων, από άμεσοι έλεγχοι ασφαλείας σε διακριτικά ηθικά διλήμματα.
Σχετικά: Συνεργασία OpenAI και Anduril Forge για την άμυνα στρατιωτικών μη επανδρωμένων αεροσκαφών των ΗΠΑ
Απόδοση από τους ανταγωνιστές σε βασικές μετρήσεις
Το OpenAI έχει δοκιμάσει τη στοχαστική ευθυγράμμιση έναντι των κορυφαίων σημείων αναφοράς ασφαλείας Τα αποτελέσματα δείχνουν ότι τα μοντέλα εκπαιδευμένοι με στοχαστική ευθυγράμμιση ξεπερνούν με συνέπεια τους ανταγωνιστές, επιτυγχάνοντας υψηλές βαθμολογίες τόσο σε στιβαρότητα όσο και σε απόκριση.
Το o1 και τα σχετικά μοντέλα έχουν δοκιμαστεί αυστηρά έναντι ανταγωνιστικών συστημάτων, συμπεριλαμβανομένων των GPT-4o, Gemini 1.5 Pro και Claude 3.5 Sonnet , σε μια ποικιλία μετρήσεων ασφάλειας. Στο StrongREJECT, το οποίο μετρά την αντίσταση ενός μοντέλου σε αντίθετα jailbreak, τα μοντέλα o1 του OpenAI σημείωσαν σταθερά υψηλότερη βαθμολογία, αντικατοπτρίζοντας την προηγμένη ικανότητά τους να αναγνωρίζουν και να αποκλείουν επιβλαβή μηνύματα.
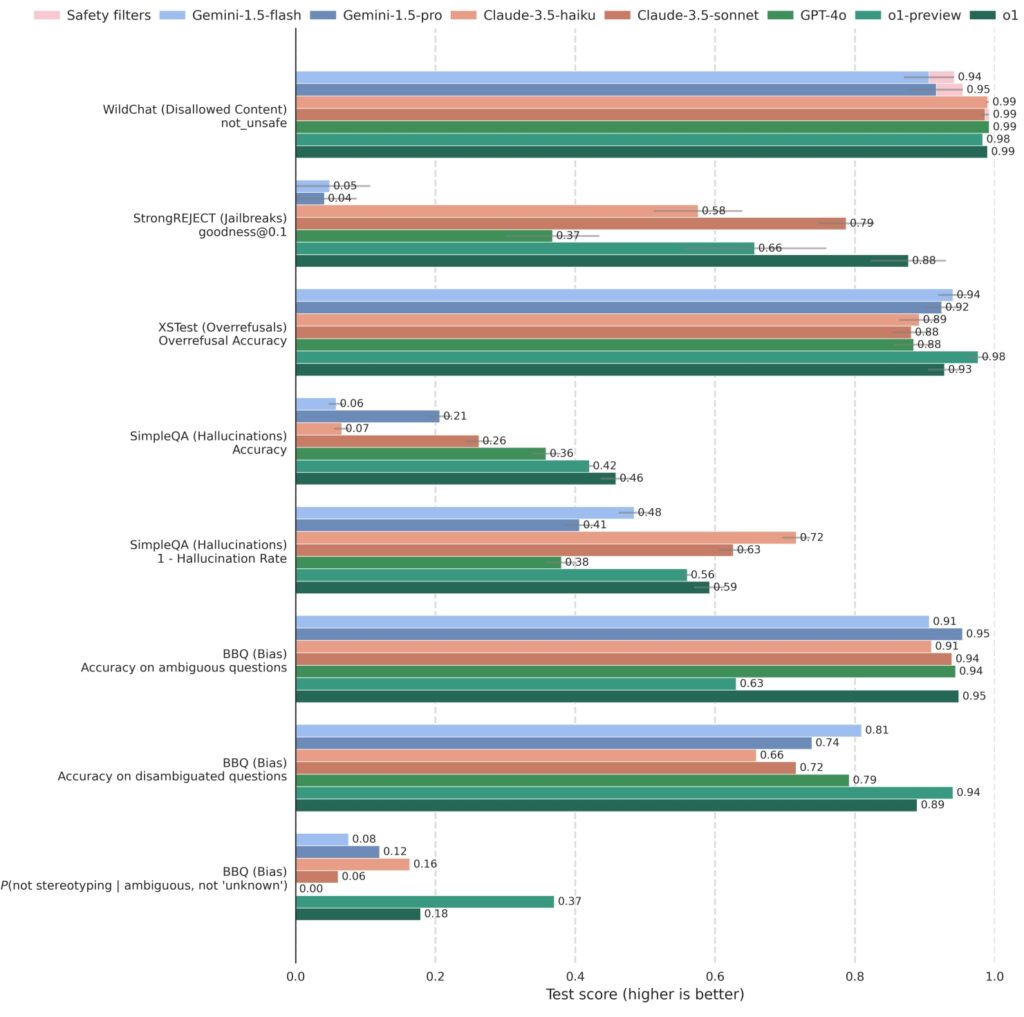 o1 είναι ανταγωνιστικό σε σύγκριση με άλλα κορυφαία μοντέλα σε δείκτες αναφοράς που αξιολογούν το μη επιτρεπόμενο περιεχόμενο (WildChat), jailbreaks (StrongREJECT), υπερβολικές αρνήσεις (XSTest), παραισθήσεις (SimpleQA) και προκατάληψη (BBQ). Ορισμένα αιτήματα API
o1 είναι ανταγωνιστικό σε σύγκριση με άλλα κορυφαία μοντέλα σε δείκτες αναφοράς που αξιολογούν το μη επιτρεπόμενο περιεχόμενο (WildChat), jailbreaks (StrongREJECT), υπερβολικές αρνήσεις (XSTest), παραισθήσεις (SimpleQA) και προκατάληψη (BBQ). Ορισμένα αιτήματα API
αποκλείστηκαν λόγω της ευαίσθητης φύσης του περιεχομένου. Αυτές οι περιπτώσεις καταγράφονται ως”Αποκλεισμένες από φίλτρα ασφαλείας”
στο WildChat και εξαιρούνται από άλλα σημεία αναφοράς. Οι γραμμές σφαλμάτων εκτιμώνται με χρήση επαναδειγματοληψίας bootstrap σε
επίπεδο 0,95. (Πηγή: OpenAI)
Επιπλέον, τα μοντέλα o1 διέπρεψαν στην εξισορρόπηση της ασφάλειας με την ανταπόκριση Στο XSTest, το οποίο αξιολογεί τις υπερβολικές αρνήσεις, τα μοντέλα επέδειξαν μειωμένη τάση απόρριψης καλοήθων προτροπών, διατηρώντας παράλληλα αυστηρή τήρηση των κατευθυντήριων γραμμών ασφαλείας παραμένουν χρήσιμα και προσβάσιμα χωρίς συμβιβασμούς στα ηθικά πρότυπα.
Το OpenAI λέει ότι είναι διαβουλευτικό. η ευθυγράμμιση βελτιώνει την ασφάλεια της τεχνητής νοημοσύνης μειώνοντας τις επιβλαβείς εξόδους ενώ αυξάνει την ακρίβεια στην απόκριση σε καλοήθεις αλληλεπιδράσεις.
Σχετικό: Πώς το πάτημα του”Stop”στο ChatGPT μπορεί να εξουδετερώσει τις διασφαλίσεις του
Ευρύτερες επιπτώσεις για την ανάπτυξη της τεχνητής νοημοσύνης
Η εισαγωγή της διαβουλευτικής ευθυγράμμισης σηματοδοτεί σημείο καμπής στον τρόπο με τον οποίο τα συστήματα τεχνητής νοημοσύνης εκπαιδεύονται και αναπτύσσονται στο OpenAI και πιθανώς και από άλλους στο μέλλον.
Με την ενσωμάτωση σαφούς συλλογισμού ασφαλείας στη βασική λειτουργικότητα των μοντέλων του, το OpenAI δημιούργησε ένα πλαίσιο που όχι μόνο αντιμετωπίζει τις υπάρχουσες προκλήσεις αλλά προβλέπει και μελλοντικούς κινδύνους. Καθώς τα συστήματα τεχνητής νοημοσύνης γίνονται πιο ικανά, η πιθανότητα κακής χρήσης ή ακούσιων συνεπειών αυξάνεται, καθιστώντας τα ισχυρά μέτρα ασφαλείας πιο κρίσιμα από ποτέ.
Η διαβουλευτική ευθυγράμμιση χρησιμεύει επίσης ως μοντέλο για την ευρύτερη κοινότητα τεχνητής νοημοσύνης. Η εξάρτησή του από κλιμακούμενες τεχνικές όπως τα συνθετικά δεδομένα και η έμφαση που δίνει στη διαφάνεια παρέχουν ένα σχέδιο για άλλους οργανισμούς που επιδιώκουν να ευθυγραμμίσουν τα συστήματα τεχνητής νοημοσύνης τους με ηθικές και κοινωνικές αξίες.