Η
Η Microsoft παρουσίασε το rStar-Math, μια συνέχεια και βελτίωση του προηγούμενου rStar πλαίσιο, για να ωθήσει τα όρια των μοντέλων μικρών γλωσσών (SLM) στο μαθηματικός συλλογισμός.
Σχεδιασμένο για να ανταγωνιστεί μεγαλύτερα συστήματα, όπως η προεπισκόπηση o1 του OpenAI, το rStar-Math επιτυγχάνει αξιοσημείωτα σημεία αναφοράς στην επίλυση προβλημάτων, ενώ δείχνει πώς τα συμπαγή μοντέλα μπορούν να αποδώσουν σε ανταγωνιστικά επίπεδα. Αυτή η εξέλιξη δείχνει μια αλλαγή στις προτεραιότητες της τεχνητής νοημοσύνης, μεταβαίνοντας από την κλιμάκωση στη βελτιστοποίηση της απόδοσης για συγκεκριμένες εργασίες.
Προχωρώντας από το rStar στο rStar-Math
Το rStar. πλαίσιο από το περασμένο καλοκαίρι έθεσε τις βάσεις για την ενίσχυση της συλλογιστικής SLM μέσω του Monte Carlo Tree Search (MCTS), ένας αλγόριθμος που βελτιώνει τις λύσεις προσομοιώνοντας και επικυρώνοντας πολλαπλές διαδρομές.
rStar έδειξε ότι τα μικρότερα μοντέλα μπορούσαν να χειριστούν πολύπλοκες εργασίες, αλλά η εφαρμογή του παρέμεινε γενική. Το rStar-Math βασίζεται σε αυτό το θεμέλιο με στοχευμένες καινοτομίες προσαρμοσμένες για μαθηματικούς συλλογισμούς.
Κεντρικό στοιχείο της επιτυχίας του rStar-Math είναι η μεθοδολογία επαυξημένης κωδικοποιημένης αλυσίδας σκέψης (CoT), όπου το μοντέλο παράγει λύσεις και στα δύο φυσική γλώσσα και εκτελέσιμο κώδικα Python.
Αυτή η δομή διπλής παραγωγής διασφαλίζει ότι τα ενδιάμεσα βήματα συλλογισμού είναι επαληθεύσιμα, μειώνοντας τα σφάλματα και διατηρώντας τη λογική συνέπεια. Οι ερευνητές τόνισαν τη σημασία αυτής της προσέγγισης, δηλώνοντας: «Η αμοιβαία συνέπεια αντικατοπτρίζει την κοινή ανθρώπινη πρακτική απουσία εποπτείας, όπου η συμφωνία μεταξύ των συμμαθητών σχετικά με τις προερχόμενες απαντήσεις υποδηλώνει μεγαλύτερη πιθανότητα ορθότητας».
Σχετικό: Το κινεζικό μοντέλο DeepSeek R1-Lite-Preview στοχεύει στην πρωτοπορία του OpenAI στην αυτοματοποιημένη συλλογιστική
Εκτός από το CoT, Το rStar-Math εισάγει ένα Μοντέλο Προτίμησης Διαδικασιών (PPM), το οποίο αξιολογεί και κατατάσσει τα ενδιάμεσα βήματα με βάση την ποιότητα Σε αντίθεση με τα παραδοσιακά συστήματα ανταμοιβής που συχνά βασίζονται σε θορυβώδη δεδομένα, το PPM δίνει προτεραιότητα στη λογική συνοχή και ακρίβεια, ενισχύοντας περαιτέρω την αξιοπιστία του μοντέλου:
“Το PPM αξιοποιεί το γεγονός ότι, παρόλο που οι τιμές Q δεν είναι ακόμα αρκετά ακριβείς για να βαθμολογήσουν κάθε βήμα συλλογισμού παρά χρησιμοποιώντας εκτεταμένες εκδόσεις MCTS, οι τιμές Q μπορούν να διακρίνουν αξιόπιστα τα θετικά (σωστά) βήματα από τα αρνητικά (άσχετα/λανθασμένα).
Επομένως, η μέθοδος εκπαίδευσης δημιουργεί ζεύγη προτιμήσεων για κάθε βήμα με βάση τις τιμές Q και τις χρήσεις απώλεια κατάταξης ανά ζεύγη για τη βελτιστοποίηση της πρόβλεψης βαθμολογίας του PPM για κάθε βήμα συλλογισμού, επιτυγχάνοντας αξιόπιστη επισήμανση. Αυτή η προσέγγιση αποφεύγει τις συμβατικές μεθόδους που χρησιμοποιούν απευθείας τις τιμές Q ως ετικέτες ανταμοιβής, οι οποίες είναι εγγενώς θορυβώδεις και ανακριβείς στη σταδιακή ανάθεση ανταμοιβής.”
Τέλος, μια συνταγή αυτοεξέλιξης τεσσάρων γύρων που σταδιακά χτίζει και τα δύο σύνορα μοντέλο πολιτικής και PPM από την αρχή.
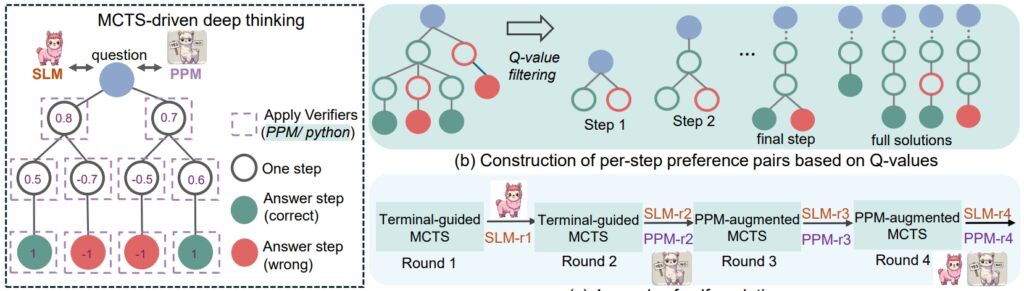 rSTar-Math διαδικασία συλλογισμού (Πηγή: ερευνητική εργασία)
rSTar-Math διαδικασία συλλογισμού (Πηγή: ερευνητική εργασία)
Επιδόσεις που προκαλούν τα μεγαλύτερα μοντέλα
Το
rStar-Math θέτει νέα πρότυπα στα σημεία αναφοράς μαθηματικών συλλογισμών, επιτυγχάνοντας αποτελέσματα που ανταγωνίζονται και σε ορισμένες περιπτώσεις ξεπερνούν αυτά των μεγαλύτερων συστημάτων τεχνητής νοημοσύνης
Στο σύνολο δεδομένων GSM8K, ένα τεστ για μαθηματικούς συλλογισμούς η ακρίβεια ενός μοντέλου 7 δισεκατομμυρίων παραμέτρων βελτιώθηκε από 12,51% σε 63,91% μετά την ενσωμάτωση rStar-Math Στην Αμερικανική Προσκλητήρια Μαθηματική Εξέταση (AIME), το μοντέλο έλυσε το 53,3% των προβλημάτων, τοποθετώντας το μεταξύ των κορυφαίων 20% των συμμετεχόντων στο γυμνάσιο.
Τα αποτελέσματα του συνόλου δεδομένων MATH ήταν εξίσου εντυπωσιακά, με το rStar-Math να επιτυγχάνει ποσοστό ακρίβειας 90%, ξεπερνώντας την προεπισκόπηση o1 του OpenAI.
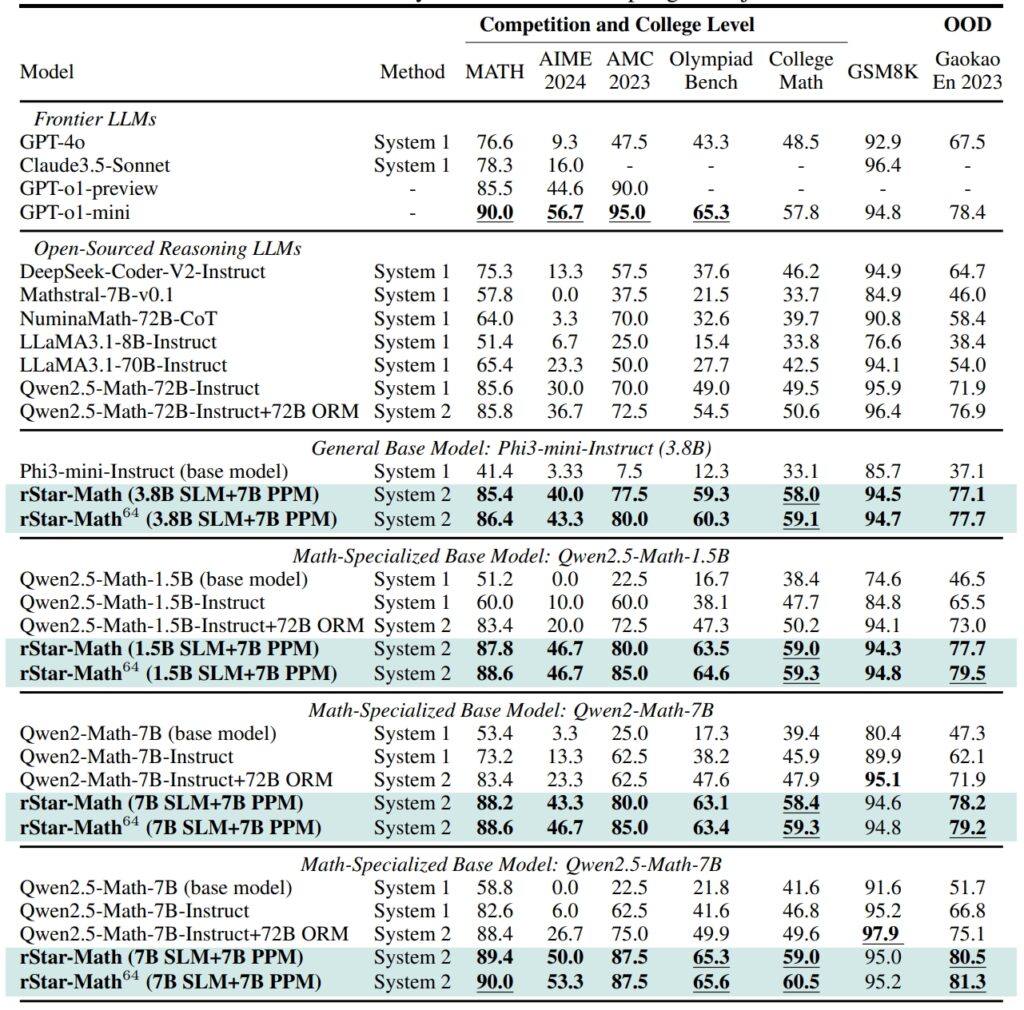 Απόδοση του rStar-Math και άλλων προηγμένων LLM στα πιο απαιτητικά μαθηματικά σημεία αναφοράς (Πηγή: ερευνητική εργασία)
Απόδοση του rStar-Math και άλλων προηγμένων LLM στα πιο απαιτητικά μαθηματικά σημεία αναφοράς (Πηγή: ερευνητική εργασία)
Αυτά τα επιτεύγματα υπογραμμίζουν την ικανότητα του πλαισίου να επιτρέπει στα SLM να χειρίζονται εργασίες που προηγουμένως κυριαρχούσαν από μεγάλα μοντέλα με ένταση πόρων. Δίνοντας έμφαση στη λογική συνέπεια και τα επαληθεύσιμα ενδιάμεσα βήματα, το rStar-Math αντιμετωπίζει μια από τις πιο επίμονες προκλήσεις της τεχνητής νοημοσύνης: τη διασφάλιση αξιόπιστης συλλογιστικής σε σύνθετους χώρους προβλημάτων.
Τεχνικές καινοτομίες Driving rStar-Math
Η εξέλιξη από το rStar στο rStar-Math εισάγει πολλές βασικές εξελίξεις. Η ενσωμάτωση του MCTS παραμένει στο επίκεντρο του πλαισίου, επιτρέποντας στο μοντέλο να διερευνήσει διάφορες συλλογιστικές διαδρομές και να δώσει προτεραιότητα στις πιο υποσχόμενες.
Η προσθήκη του συλλογισμού CoT, με έμφαση στην επαλήθευση κώδικα, διασφαλίζει ότι τα αποτελέσματα είναι τόσο ερμηνεύσιμα όσο και ακριβή.
Σχετικά: QwQ-32B της Alibaba.-Η προεπισκόπηση συμμετέχει στη μάχη συλλογισμού μοντέλου AI με το OpenAI
Ίσως το πιο μεταμορφωτικό είναι η αυτο-εξελικτική διαδικασία εκπαίδευσης του rStar-Math. Σε τέσσερις επαναληπτικούς γύρους, το πλαίσιο βελτιώνει το μοντέλο πολιτικής του και το PPM, ενσωματώνοντας δεδομένα συλλογιστικής υψηλότερης ποιότητας σε κάθε βήμα.
Αυτή η επαναληπτική προσέγγιση επιτρέπει στο μοντέλο να βελτιώνει συνεχώς την απόδοσή του, επιτυγχάνοντας αποτελέσματα αιχμής χωρίς να βασίζεται στην απόσταξη από μεγαλύτερα μοντέλα.
Σύγκριση rStar-Math. στο o1 του OpenAI
Ενώ η Microsoft εστιάζει στη βελτιστοποίηση μικρότερων μοντέλων, το OpenAI συνεχίζει να δίνει προτεραιότητα στην κλιμάκωση των συστημάτων του.
o1 Pro Mode, που εισήχθη τον Δεκέμβριο του 2024 ως μέρος του ChatGPT Pro Plan, προσφέρει προηγμένες δυνατότητες συλλογιστικής προσαρμοσμένες για εφαρμογές υψηλού κινδύνου, όπως η κωδικοποίηση και η επιστημονική έρευνα. Το OpenAI ανέφερε ότι το o1 Pro Mode πέτυχε ποσοστό ακρίβειας 86% στο AIME και ποσοστό επιτυχίας 90% σε σημεία αναφοράς κωδικοποίησης όπως το Codeforces.
Το rStar-Math αντιπροσωπεύει μια αλλαγή στην καινοτομία AI, αμφισβητώντας την εστίαση της βιομηχανίας σε μεγαλύτερα μοντέλα ως το πρωταρχικό μέσο για την επίτευξη προχωρημένου συλλογισμού. Βελτιώνοντας τα SLM με βελτιστοποιήσεις για συγκεκριμένο τομέα, η Microsoft προσφέρει μια βιώσιμη εναλλακτική που μειώνει το υπολογιστικό κόστος και τις περιβαλλοντικές επιπτώσεις.
Σχετικά: Διαβουλευτική ευθυγράμμιση: Στρατηγική ασφάλειας του OpenAI για τα μοντέλα σκέψης του o1 και o3
Η επιτυχία του πλαισίου στη μαθηματική συλλογιστική ανοίγει πόρτες σε ευρύτερες εφαρμογές, από την εκπαίδευση στην επιστημονική έρευνα.
Οι ερευνητές σχεδιάζουν να κυκλοφορήσουν τον κώδικα και τα δεδομένα του rStar-Math στο GitHub, ανοίγοντας το δρόμο για περαιτέρω συνεργασία και ανάπτυξη. Αυτή η διαφάνεια αντικατοπτρίζει την προσέγγιση της Microsoft να κάνει τα εργαλεία τεχνητής νοημοσύνης υψηλής απόδοσης προσβάσιμα σε ένα ευρύτερο κοινό, συμπεριλαμβανομένων ακαδημαϊκών ιδρυμάτων και οργανισμών μεσαίου μεγέθους.
Σχετικά: SemiAnalysis: Όχι, AI Scaling Isn’t Slowing Down
Καθώς εντείνεται ο ανταγωνισμός μεταξύ Microsoft και OpenAI, οι εξελίξεις που εισάγει το rStar-Math υπογραμμίζουν τις δυνατότητες μικρότερων μοντέλων για να αμφισβητήσουν την κυριαρχία μεγαλύτερων συστημάτων. Δίνοντας προτεραιότητα στην αποτελεσματικότητα και την ακρίβεια, το rStar-Math θέτει ένα νέο σημείο αναφοράς για το τι μπορούν να επιτύχουν τα συμπαγή συστήματα AI.