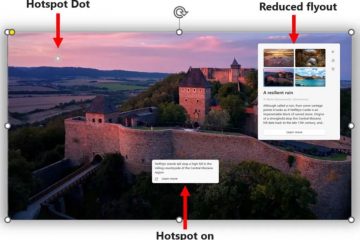
Η
Η EleutherAI, σε συνεργασία με το Stability AI και άλλους οργανισμούς, παρουσίασε το Λόγισμα αξιολόγησης μοντέλου γλώσσας (lm-eval), μια βιβλιοθήκη ανοιχτού κώδικα με στόχο τη βελτίωση της αξιολόγησης των μοντέλων γλώσσας. Αυτό το εργαλείο επιδιώκει να παρέχει ένα τυποποιημένο και προσαρμόσιμο πλαίσιο για την αξιολόγηση των γλωσσικών μοντέλων, την αντιμετώπιση ζητημάτων όπως η αναπαραγωγιμότητα και η διαφάνεια. Το EleutherAI είναι ένα μη κερδοσκοπικό ερευνητικό εργαστήριο αφιερωμένο στην ερμηνευσιμότητα και την ευθυγράμμιση μοντέλων τεχνητής νοημοσύνης μεγάλης κλίμακας.
Προκλήσεις στην αξιολόγηση μοντέλων γλώσσας
Αξιολόγηση μοντέλων γλώσσας. , ιδιαίτερα τα LLMs, συνεχίζει να αποτελεί σημαντική πρόκληση για τους ερευνητές. Τα κοινά ζητήματα περιλαμβάνουν την ευαισθησία σε διαφορετικές ρυθμίσεις αξιολόγησης και τις δυσκολίες στην πραγματοποίηση ακριβών συγκρίσεων μεταξύ διαφόρων μεθόδων. Η έλλειψη αναπαραγωγιμότητας και διαφάνειας περιπλέκει περαιτέρω τη διαδικασία αξιολόγησης, οδηγώντας σε δυνητικά μεροληπτικά ή αναξιόπιστα αποτελέσματα.
lm-eval ως ολοκληρωμένη λύση
Σύμφωνα με το το αντίστοιχο χαρτί, το εργαλείο lm-eval ενσωματώνει πολλά βασικά χαρακτηριστικά για τη βελτίωση της διαδικασίας αξιολόγησης. Επιτρέπει τη σπονδυλωτή υλοποίηση των εργασιών αξιολόγησης, επιτρέποντας στους ερευνητές να μοιράζονται και να αναπαράγουν τα αποτελέσματα πιο αποτελεσματικά. Η βιβλιοθήκη υποστηρίζει πολλαπλά αιτήματα αξιολόγησης, όπως log-likelihoods υπό όρους, προβληματισμοί και δημιουργία κειμένου, διασφαλίζοντας μια ενδελεχή αξιολόγηση των δυνατοτήτων ενός μοντέλου. Για παράδειγμα, το lm-eval μπορεί να υπολογίσει την πιθανότητα δεδομένων συμβολοσειρών εξόδου με βάση τις παρεχόμενες εισόδους ή να μετρήσει τη μέση πιθανότητα καταγραφής παραγωγής διακριτικών σε ένα σύνολο δεδομένων. Αυτά τα χαρακτηριστικά καθιστούν το lm-eval ένα ευέλικτο εργαλείο για την αξιολόγηση μοντέλων γλώσσας σε διαφορετικά περιβάλλοντα.

Η βιβλιοθήκη lm-eval παρέχει επίσης δυνατότητες που υποστηρίζουν ποιοτική ανάλυση και στατιστικές δοκιμές, ζωτικής σημασίας για εις βάθος αξιολογήσεις μοντέλων. Διευκολύνει τους ποιοτικούς ελέγχους, επιτρέποντας στους ερευνητές να αξιολογήσουν την ποιότητα των αποτελεσμάτων του μοντέλου πέρα από τις αυτοματοποιημένες μετρήσεις. Αυτή η ολιστική προσέγγιση εγγυάται ότι οι αξιολογήσεις δεν είναι απλώς αναπαραγώγιμες, αλλά παρέχουν επίσης μια πιο βαθιά εικόνα για την απόδοση του μοντέλου.
Περιορισμοί των τρεχουσών μεθόδων αξιολόγησης
Υπάρχουσες μέθοδοι για την απόδοση του μοντέλου. η αξιολόγηση μοντέλων γλώσσας εξαρτάται συχνά από εργασίες συγκριτικής αξιολόγησης και αυτοματοποιημένες μετρήσεις όπως το BLEU και το ROUGE. Ενώ αυτές οι μετρήσεις προσφέρουν οφέλη όπως η αναπαραγωγιμότητα και το χαμηλότερο κόστος σε σύγκριση με τις ανθρώπινες αξιολογήσεις, έχουν επίσης αξιοσημείωτα μειονεκτήματα. Οι αυτοματοποιημένες μετρήσεις μπορούν να μετρήσουν την επικάλυψη μεταξύ μιας δημιουργούμενης απόκρισης και ενός κειμένου αναφοράς, αλλά ενδέχεται να μην αποτυπώνουν πλήρως τις λεπτές λεπτομέρειες της ανθρώπινης γλώσσας ή την ακρίβεια των απαντήσεων που δημιουργούνται από τα μοντέλα.
Απόδοση και συνέπεια του lm.-eval
Η χρήση του lm-eval έχει αποδειχθεί αποτελεσματική στην υπέρβαση τυπικών εμποδίων στην αξιολόγηση του γλωσσικού μοντέλου. Αυτό το εργαλείο βοηθά στον εντοπισμό προβλημάτων όπως η εξάρτηση από ασήμαντες λεπτομέρειες εφαρμογής που μπορούν να επηρεάσουν σε μεγάλο βαθμό την αξιοπιστία των αξιολογήσεων. Προσφέροντας ένα ενιαίο πλαίσιο, το lm-eval εγγυάται ότι οι αξιολογήσεις πραγματοποιούνται ομοιόμορφα, ανεξάρτητα από τα συγκεκριμένα μοντέλα ή δείκτες αναφοράς που χρησιμοποιούνται. Αυτή η συνέπεια είναι ζωτικής σημασίας για τις δίκαιες συγκρίσεις μεταξύ διαφόρων τεχνικών και μοντέλων, με αποτέλεσμα πιο αξιόπιστα και ακριβή ευρήματα έρευνας.