Google DeepMind hat FACTS Grounding eingeführt, einen neuen Benchmark, mit dem große Sprachmodelle (LLMs) auf ihre Fähigkeit getestet werden sollen, sachlich korrekte, dokumentenbasierte Antworten zu generieren.
Der Benchmark, auf Kaggle gehostet, zielt darauf ab, eine der dringendsten Herausforderungen der Welt anzugehen Künstliche Intelligenz: Sicherstellen, dass die KI-Ergebnisse auf den ihnen bereitgestellten Daten basieren, anstatt sich auf externes Wissen zu verlassen oder Halluzinationen hervorzurufen – plausible, aber falsche Informationen.
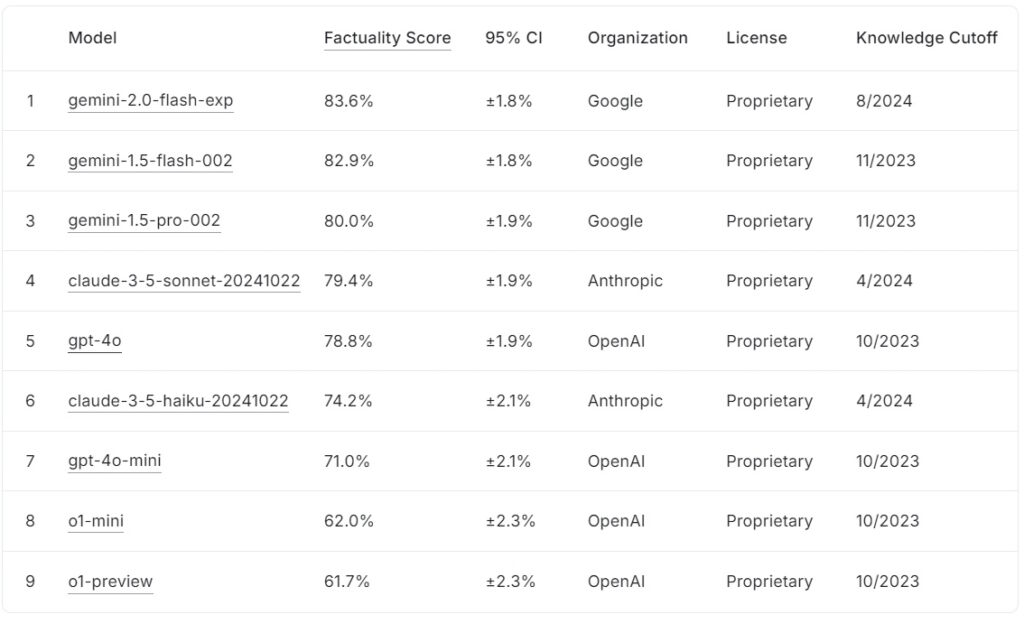
Die aktuelle FACTS Grounding-Bestenliste ordnet große Sprachmodelle basierend auf ihren Faktizitätswerten mit denen von Google ein gemini-2.0-flash-exp liegt mit 83,6 % an der Spitze, dicht gefolgt von gemini-1.5-flash-002 82,9 % und gemini-1.5-pro-002 bei 80,0 %.
Anthropics claude-3.5-sonnet-20241022 belegt mit 79,4 % den vierten Platz, während OpenAI gpt-4o erreicht 78,8 % und liegt damit auf dem fünften Platz. Am unteren Ende der Liste erreicht claude-3.5-haiku-20241022 von Anthropic 74,2 %, gefolgt von gpt-4o-mini mit 71,0 %.
Die kleineren Modelle von OpenAI, o1-mini und o1-preview, runden die Bestenliste mit 62,0 % und o1-preview ab >61,7 %.
 Quelle: Kaggle
Quelle: Kaggle
FACTS Grounding zeichnet sich dadurch aus, dass lange Antworten erforderlich sind, die detaillierte Eingabedokumente synthetisieren, was es zu einem von vielen macht die bislang strengsten Maßstäbe für die Faktizität von KI.
FAKTEN Grounding stellt eine entscheidende Entwicklung für die KI-Branche dar, insbesondere bei Anwendungen, bei denen Vertrauen und Genauigkeit unerlässlich sind. Durch die Bewertung von LLMs in Bereichen wie Medizin, Recht, Finanzen, Einzelhandel und Technologie schafft der Benchmark die Voraussetzungen für eine verbesserte KI-Zuverlässigkeit in realen Szenarien.
Laut dem Forschungsteam von DeepMind misst der „Benchmark die Fähigkeit von LLMs, Antworten zu generieren, die ausschließlich auf dem bereitgestellten Kontext basieren … selbst wenn der Kontext im Widerspruch zum Wissen vor dem Training steht.“
Datensatz für die Komplexität der realen Welt
FACTS Grounding besteht aus 1.719 Beispielen, die von menschlichen Annotatoren kuratiert wurden, um Relevanz und Vielfalt zu gewährleisten Detaillierte Dokumente, die bis zu 32.000 Token umfassen, was etwa 20.000 Wörtern entspricht.
Jede Aufgabe fordert LLMs dazu auf, eine Zusammenfassung durchzuführen, Fragen und Antworten zu erstellen oder Inhalte neu zu schreiben, wobei der Benchmark strikt darauf hinweist, nur auf die bereitgestellten Daten zu verweisen Aufgaben, die Kreativität, mathematisches Denken oder Experteninterpretation erfordern, konzentrieren sich stattdessen auf das Testen der Fähigkeit eines Modells, komplexe Informationen zu synthetisieren und zu artikulieren.
Um Transparenz aufrechtzuerhalten und zu verhindern Aufgrund der Überanpassung teilte DeepMind den Datensatz in zwei Segmente auf: 860 öffentliche Beispiele, die für den externen Gebrauch verfügbar sind, und 859 private Beispiele, die für Bestenlistenauswertungen reserviert sind.
Diese duale Struktur schützt die Integrität des Benchmarks und fördert gleichzeitig die Zusammenarbeit von KI-Entwicklern weltweit. „Wir evaluieren unsere automatischen Evaluatoren streng anhand der zurückgehaltenen Testdaten, um ihre Leistung bei unserer Aufgabe zu validieren“, bemerkt das Forschungsteam und hebt das sorgfältige Design hervor, das FACTS Grounding zugrunde liegt.
Beurteilung der Genauigkeit mit Peer KI-Modelle
Im Gegensatz zu herkömmlichen Benchmarks verwendet FACTS Grounding einen Peer-Review-Prozess, an dem drei fortgeschrittene LLMs beteiligt sind: Gemini 1.5 Pro, GPT-4o und Claude 3.5 Sonnet dienen als Juroren und bewerten Antworten auf der Grundlage von zwei kritischen Kriterien:
Antworten müssen zunächst eine Eignungsprüfung bestehen, um zu bestätigen, dass sie die Anfrage des Benutzers sinnvoll beantworten Diejenigen, die sich qualifizieren, werden dann auf ihre Verankerung im Quellmaterial hin bewertet, wobei die Bewertungen über die drei Modelle hinweg aggregiert werden, um Verzerrungen zu minimieren.
Die Forscher von DeepMind betonen die Bedeutung von Diese vielschichtige Bewertung besagt: „Metriken, die sich auf die Bewertung der Faktizität des generierten Textes konzentrieren … können umgangen werden, indem die Absicht hinter der Benutzeranfrage ignoriert wird.“ Indem man kürzere Antworten gibt, die sich der Übermittlung umfassender Informationen entziehen, ist es möglich, eine hohe Faktizitätsbewertung zu erreichen, ohne eine hilfreiche Antwort bereitzustellen , gewährleistet außerdem die Anpassung an das menschliche Urteilsvermögen und die Anpassungsfähigkeit an verschiedene Aufgaben.
Die Herausforderung von KI-Halluzinationen angehen
KI-Halluzinationen gehören zu den größten Hindernissen für die Verbreitung Die Einführung von LLMs in kritischen Bereichen, bei denen Modelle Ergebnisse liefern, die plausibel erscheinen, aber sachlich falsch sind, stellen ernsthafte Risiken in Bereichen wie dem Gesundheitswesen, der Rechtsanalyse und der Finanzberichterstattung dar.
FACTS Grounding geht dieses Problem direkt an Problem, indem die strikte Einhaltung der bereitgestellten Eingabedaten erzwungen wird. Dieser Ansatz bewertet nicht nur die Fähigkeit eines Modells, die Einführung von Unwahrheiten zu vermeiden, sondern stellt auch sicher, dass die Ausgaben mit der Absicht des Benutzers übereinstimmen.
Im Gegensatz dazu Im Vergleich zu Benchmarks wie SimpleQA von OpenAI, das die Faktizität beim Abrufen von Trainingsdaten misst, testet FACTS Grounding, wie gut Modelle neue Informationen synthetisieren.
Das Forschungspapier unterstreicht diesen Unterschied: „Die Gewährleistung der sachlichen Genauigkeit bei der Generierung von LLM-Antworten ist eine Herausforderung. Die Hauptherausforderungen bei der LLM-Faktizität sind Modellierung (d. h. Architektur, Training und Inferenz) und Messung (d. h. Bewertungsmethodik, Daten und Metriken).“
Technische Herausforderungen und Benchmark-Design
Die Komplexität langer Eingaben bringt einzigartige technische Herausforderungen mit sich, insbesondere bei der Entwicklung automatisierter Bewertungsmethoden, die solche Antworten genau bewerten können.
FACTS Grounding verlässt sich darauf rechenintensive Prozesse zur Validierung von Antworten unter Verwendung strenger Kriterien zur Gewährleistung der Zuverlässigkeit. Die Einbeziehung mehrerer Richtermodelle mildert potenzielle Verzerrungen und stärkt den gesamten Bewertungsrahmen.
Das Forschungsteam betont, wie wichtig es ist, vage oder irrelevante Antworten zu disqualifizieren. Er stellte fest: „Das Ausschließen unzulässiger Antworten führt zu einer Kürzung … da diese Antworten als ungenau behandelt werden.“
Diese strikte Durchsetzung der Relevanz stellt sicher, dass Models nicht dafür belohnt werden, dass sie den Geist der Aufgabe umgehen.
Förderung der Zusammenarbeit durch Transparenz
Die Entscheidung von DeepMind, FACTS Grounding auf Kaggle auszurichten, spiegelt sein Engagement für die Förderung der Zusammenarbeit in der gesamten KI-Branche wider. Durch die Zugänglichkeit des öffentlichen Segments des Datensatzes lädt das Projekt KI-Forscher und-Entwickler dazu ein, ihre Modelle anhand eines robusten Standards zu bewerten und zur Weiterentwicklung von Faktizitäts-Benchmarks beizutragen.
Dieser Ansatz steht im Einklang mit den umfassenderen Zielen der Transparenz und des gemeinsamen Fortschritts in der KI und stellt sicher, dass Verbesserungen in Bezug auf Genauigkeit und Bodenständigkeit nicht auf eine einzelne Organisation beschränkt sind.
Abgrenzung von anderen Benchmarks
FAKTEN Grounding unterscheidet sich von anderen Benchmarks durch seinen Fokus auf die Verankerung neu eingeführter Eingaben und nicht auf vorab trainiertem Wissen.
Während Benchmarks wie SimpleQA von OpenAI bewerten, wie gut ein Modell Informationen aus seinem Trainingskorpus abruft und nutzt, bewertet FACTS Grounding Modelle anhand ihrer Fähigkeit, Antworten ausschließlich auf der Grundlage der bereitgestellten Daten zu synthetisieren und zu artikulieren.
Diese Unterscheidung ist von entscheidender Bedeutung bei der Bewältigung von Herausforderungen, die durch Modellvorurteile oder inhärente Vorurteile entstehen. Durch die Isolierung der Aufgabe der Verarbeitung externer Eingaben stellt FACTS Grounding sicher, dass Leistungsmetriken die Fähigkeit eines Modells widerspiegeln, in dynamischen, realen Szenarien zu arbeiten, anstatt einfach vorab gelernte Informationen wiederzugeben.
Wie DeepMind in seinem Forschungsbericht erklärt, ist der Benchmark darauf ausgelegt, LLMs hinsichtlich ihrer Fähigkeit zu bewerten, komplexe, lange Abfragen mit sachlicher Grundlage zu verwalten und Aufgaben zu simulieren, die für reale Anwendungen relevant sind.
Alternative Methoden zur Erdung von LLMs
Mehrere Methoden bieten ähnliche Erdungsfunktionen wie die FACTS-Erdung, jede mit ihren Stärken und Schwächen. Diese Methoden zielen darauf ab, die LLM-Ergebnisse zu verbessern, indem sie entweder den Zugang zu genauen Informationen verbessern oder ihre Trainings-und Ausrichtungsprozesse verfeinern.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) verbessert die Genauigkeit von LLM-Ausgaben durch dynamisches Abrufen relevanter Daten Informationen aus externen Wissensdatenbanken oder Datenbanken und deren Einbindung in die Antworten des Modells. Anstatt das gesamte LLM neu zu trainieren, fängt RAG Benutzereingaben ab und reichert sie mit aktuellen Informationen an.
Fortgeschrittene RAG-Implementierungen nutzen oft den entitätsbasierten Abruf, bei dem Daten, die bestimmten Entitäten zugeordnet sind, vereinheitlicht werden stellen hochrelevanten Kontext für LLM-Antworten bereit.
RAG verwendet typischerweise semantische Suchtechniken zum Abrufen von Informationen. Dokumente oder ihre Fragmente werden basierend auf ihrer semantischen Einbettung indiziert, sodass das System die Anfrage des Benutzers mit den kontextuell relevantesten Einträgen abgleichen kann. Dieser Ansatz stellt sicher, dass LLMs Antworten generieren, die auf den neuesten und relevantesten Daten basieren.
Die Wirksamkeit von RAG hängt stark von der Qualität und Organisation der Wissensdatenbank sowie der Präzision der Abrufalgorithmen ab. Während FACTS Grounding die Fähigkeit eines LLM bewertet, in einem bereitgestellten Kontextdokument verankert zu bleiben, ergänzt RAG dies, indem es LLMs ermöglicht, ihr Wissen dynamisch zu erweitern und dabei auf externe Quellen zurückzugreifen, um die Faktizität und Relevanz zu verbessern.
Wissensdestillation
Wissensdestillation beinhaltet die Übertragung der Fähigkeiten von von einem großen, komplexen Modell (als Lehrer bezeichnet) zu einem kleineren, aufgabenspezifischen Modell (dem Schüler). Diese Methode verbessert die Effizienz und behält gleichzeitig einen Großteil der Genauigkeit des Originalmodells bei. Bei der Wissensdestillation werden zwei Hauptansätze verwendet:
Antwortbasierte Wissensdestillation: Konzentriert sich auf die Replikation der Ergebnisse des Lehrermodells und stellt sicher, dass das Schülermodell für gegebene Eingaben ähnliche Ergebnisse liefert.
Feature-basierte Wissensdestillation: Extrahiert interne Darstellungen und Features aus dem Lehrermodell, sodass das Schülermodell tiefere Erkenntnisse reproduzieren kann.
Durch Verfeinerung kleinerer Modelle , Wissensdestillation ermöglicht den Einsatz von LLMs in ressourcenbeschränkten Umgebungen ohne nennenswerte Leistungseinbußen. Im Gegensatz zu FACTS Grounding, das die Genauigkeit der Erdung bewertet, geht es bei der Wissensdestillation mehr um die Skalierung der LLM-Fähigkeiten und deren Optimierung für bestimmte Aufgaben.
Feinabstimmung mit geerdeten Datensätzen
Feinabstimmung beinhaltet die Anpassung vorab trainierter Inhalte LLMs für bestimmte Bereiche oder Aufgaben, indem Sie sie anhand kuratierter Datensätze trainieren, bei denen eine sachliche Grundlage von entscheidender Bedeutung ist. Beispielsweise können Datensätze aus wissenschaftlicher Literatur oder historischen Aufzeichnungen verwendet werden, um die Fähigkeit des Modells zu verbessern, genaue und domänenspezifische Ergebnisse zu erzeugen. Diese Technik verbessert die LLM-Leistung für spezielle Anwendungen, wie z. B. die Analyse medizinischer oder juristischer Dokumente.
Die Feinabstimmung ist jedoch ressourcenintensiv und birgt das Risiko eines katastrophalen Vergessens, bei dem das Modell Wissen verliert, das während seines anfänglichen Trainings erworben wurde. FACTS Grounding konzentriert sich auf die Prüfung der Faktizität in isolierten Kontexten, während die Feinabstimmung darauf abzielt, die grundlegende Leistung von LLMs in bestimmten Bereichen zu verbessern.
Reinforcement Learning with Human Feedback (RLHF)
Reinforcement Learning with Human Feedback (RLHF) bezieht menschliche Vorlieben in den Ausbildungsprozess von LLMs ein. Durch iteratives Training des Modells, um seine Antworten an menschlichem Feedback auszurichten, verfeinert RLHF die Qualität, Faktizität und Nützlichkeit der Ergebnisse. Menschliche Bewerter bewerten die Ergebnisse des LLM und diese Bewertungen werden als Signale zur Optimierung des Modells verwendet.
RLHF war besonders erfolgreich bei der Steigerung der Benutzerzufriedenheit und der Sicherstellung, dass die generierten Antworten den menschlichen Erwartungen entsprechen. Während FACTS Grounding die sachliche Begründung anhand spezifischer Dokumente bewertet, legt RLHF Wert darauf, LLM-Ergebnisse an menschlichen Werten und Vorlieben auszurichten.
Anweisungen befolgen und kontextbezogenes Lernen
Anweisungen befolgen und kontextbezogenes Lernen erfordern das Vorführen Einführung in LLMs durch sorgfältig ausgearbeitete Beispiele innerhalb der Benutzeraufforderung. Diese Methoden basieren auf der Fähigkeit des Modells, aus einer Demonstration mit wenigen Schüssen zu verallgemeinern. Obwohl dieser Ansatz zu schnellen Verbesserungen führen kann, erreicht er möglicherweise nicht das gleiche Maß an Erdungsqualität wie Feinabstimmungs-oder abrufbasierte Methoden.
Externe Tools und APIs
LLMs können in externe Tools und APIs integriert werden, um Echtzeitzugriff auf externe Daten zu ermöglichen und so ihre Erdungsfunktionen erheblich zu verbessern. Beispiele hierfür sind:
Browsing-Fähigkeit: Ermöglicht LLMs, auf Echtzeitinformationen aus dem Internet zuzugreifen und diese abzurufen, um bestimmte Fragen zu beantworten oder ihr Wissen zu aktualisieren.
API-Aufrufe: Ermöglicht LLMs die Interaktion mit strukturierten Datenbanken oder Diensten und bereichert Antworten mit präzisen und aktuellen Informationen.
Diese Tools erweitern den Nutzen von LLMs, indem sie sie mit realen verbinden-Weltweite Wissensquellen, Verbesserung ihre Fähigkeit, genaue und geerdete Ausgänge zu erzeugen. Während FACTS Grounding die interne Erdungstreue bewertet, bieten externe Tools eine alternative Möglichkeit, die Faktizität zu erweitern und zu überprüfen.
Open-Source Model Grounding Optionen
Für die oben besprochenen alternativen Erdungsmethoden stehen mehrere Open-Source-Implementierungen zur Verfügung:
Implikationen für High-Stakes-Anwendungen
Die Bedeutung präziser und fundierter KI-Reaktionen wird besonders deutlich bei anspruchsvollen Anwendungen wie medizinischer Diagnostik, rechtlichen Überprüfungen und Finanzanalysen. In diesen Kontexten können selbst geringfügige Ungenauigkeiten erhebliche Konsequenzen haben, sodass die Zuverlässigkeit der von der KI generierten Ergebnisse eine nicht verhandelbare Anforderung ist.
FAKTEN Der Schwerpunkt von Grounding auf Faktizität und Einhaltung des Quellenmaterials stellt sicher, dass Modelle unter Bedingungen getestet werden, die den Anforderungen der realen Welt möglichst genau entsprechen.
In medizinischen Kontexten wird beispielsweise ein LLM damit beauftragt Bei der Zusammenfassung von Patientenakten müssen Fehler vermieden werden, die zu falschen Behandlungsentscheidungen führen könnten. Ebenso erfordert die Erstellung von Zusammenfassungen oder Analysen der Rechtsprechung im juristischen Bereich eine genaue Untermauerung der bereitgestellten Dokumente.
FACTS Grounding bewertet nicht nur Modelle hinsichtlich ihrer Fähigkeit, diese strengen Anforderungen zu erfüllen, sondern legt auch einen Maßstab für Entwickler fest, den sie bei der Entwicklung von Systemen anstreben, die für solche Anwendungen geeignet sind.
Expanding der FACTS-Datensatz und zukünftige Richtungen
DeepMind hat FACTS Grounding als „lebenden Maßstab“ positioniert, der sich parallel zu den Fortschritten in der KI weiterentwickeln wird. Zukünftige Updates werden den Datensatz wahrscheinlich um Folgendes erweitern Neue Domänen und Aufgabentypen stellen sicher, dass seine Relevanz bei zunehmenden LLM-Fähigkeiten erhalten bleibt.
Darüber hinaus könnte die Einführung vielfältigerer Bewertungsvorlagen die Robustheit des Bewertungsprozesses weiter verbessern, Randfälle berücksichtigen und verbleibende Verzerrungen reduzieren.
Wie das Forschungsteam von DeepMind anerkennt, kann kein Benchmark die Komplexität realer Anwendungen vollständig erfassen. Durch die Iteration von FACTS Grounding und die Einbindung der breiteren KI-Community zielt das Projekt jedoch darauf ab, diese zu verbessern die Messlatte für Faktizität und Bodenständigkeit in KI-Systemen.
Wie das Team von DeepMind feststellt: „Faktizität und Erdung gehören zu den Schlüsselfaktoren, die den zukünftigen Erfolg und die Nützlichkeit von LLMs und umfassenderen KI-Systemen prägen werden, und wir wollen FACTS Grounding im Verlauf des Feldes weiterentwickeln und iterieren.“ die Messlatte immer höher legen.“