DeepSeek AI hat DeepSeek-VL2 veröffentlicht, eine Familie von Vision-Language-Modellen (VLMs), die jetzt unter Open-Source-Lizenzen verfügbar sind. Die Serie stellt drei Varianten vor – Tiny, Small und die Standard-VL2 – mit aktivierten Parametergrößen von 1,0 Milliarden, 2,8 Milliarden bzw. 4,5 Milliarden.
Die Modelle sind über GitHub undUmarmendes Gesicht. Sie versprechen, wichtige KI-Anwendungen voranzutreiben, darunter visuelle Fragebeantwortung (VQA), optische Zeichenerkennung (OCR) und hochauflösende Dokumenten-und Diagrammanalyse.
Laut der offiziellen GitHub-Dokumentation „zeigt DeepSeek-VL2 überlegene Fähigkeiten bei verschiedenen Aufgaben, einschließlich, aber nicht beschränkt auf, visuelle Beantwortung von Fragen, Verständnis von Dokumenten/Tabellen/Diagrammen und visuelle Erdung.“
Der Zeitpunkt dieser Veröffentlichung stellt DeepSeek AI in direkte Konkurrenz zu großen Playern wie OpenAI und Google, die beide den Bereich Vision-Language AI mit proprietären Produkten dominieren Modelle wie GPT-4V und Gemini-Exp.
DeepSeeks Schwerpunkt liegt auf Die Open-Source-Zusammenarbeit in Kombination mit den fortschrittlichen technischen Funktionen der VL2-Familie macht sie zu einer kostenlosen Option für Forscher.
Dynamic Tiling: Weiterentwicklung der hochauflösenden Bildverarbeitung
Eine der bemerkenswertesten Weiterentwicklungen in DeepSeek-VL2 ist seine dynamische Kachel-Vision-Codierungsstrategie, die die Art und Weise, wie die Modelle hochauflösende visuelle Daten verarbeiten, revolutioniert.
Im Gegensatz zu herkömmlicher fester Auflösung Beim dynamischen Kacheln werden Bilder in kleinere, flexible Kacheln unterteilt, die sich an verschiedene Seitenverhältnisse anpassen. Diese Methode gewährleistet eine detaillierte Merkmalsextraktion bei gleichzeitiger Beibehaltung der Recheneffizienz.
In seinem GitHub-Repository beschreibt DeepSeek dies als eine Möglichkeit, „hochauflösende Bilder mit unterschiedlichen Seitenverhältnissen effizient zu verarbeiten und dabei die rechnerische Skalierung zu vermeiden, die normalerweise mit zunehmenden Bildauflösungen verbunden ist.“
Diese Fähigkeit ermöglicht es DeepSeek-VL2, sich bei Anwendungen wie der visuellen Erdung, bei denen eine hohe Präzision für die Identifizierung von Objekten in komplexen Bildern unerlässlich ist, und bei dichten OCR-Aufgaben, die die Verarbeitung von Text in detaillierten Dokumenten oder Diagrammen erfordern, hervorzuheben.
Durch die dynamische Anpassung an unterschiedliche Bildauflösungen und Seitenverhältnisse überwinden die Modelle die Einschränkungen statischer Kodierungsmethoden und eignen sich so für Anwendungsfälle, die sowohl Flexibilität als auch Genauigkeit erfordern.
Mixture-of-Experts und Multi-Head Latent Attention für Effizienz
Die Leistungssteigerungen von DeepSeek-VL2 werden durch die Integration des Mixture-of-Experts (MoE)-Frameworks weiter unterstützt Multi-Head Latent Attention (MLA)-Mechanismus
Die MoE-Architektur aktiviert selektiv bestimmte Teilmengen oder „Experten“ innerhalb des Modells, um Aufgaben effizienter zu erledigen. Dieses Design reduziert den Rechenaufwand, indem es nur die notwendigen Parameter für jeden Vorgang einbezieht, eine Funktion, die besonders in Umgebungen mit eingeschränkten Ressourcen nützlich ist.
Der MLA-Mechanismus ergänzt das MoE-Framework, indem er den Schlüsselwert-Cache in den latenten Cache komprimiert Vektoren während der Inferenz. Diese Optimierung minimiert die Speichernutzung und erhöht die Verarbeitungsgeschwindigkeit, ohne die Modellgenauigkeit zu beeinträchtigen.
Der technischen Dokumentation zufolge „ermöglicht die MoE-Architektur in Kombination mit MLA, dass DeepSeek-VL2 mit weniger aktivierten Parametern eine konkurrenzfähige oder bessere Leistung als dichte Modelle erzielt.“
Dreistufige Trainingspipeline
Die Entwicklung von DeepSeek-VL2 umfasste eine strenge dreistufige Trainingspipeline, die darauf ausgelegt war, die multimodalen Fähigkeiten des Modells zu optimieren Vision-Sprach-Ausrichtung, bei der die Modelle darauf trainiert wurden, visuelle Merkmale mit Textinformationen zu integrieren.
Dies wurde mithilfe von Datensätzen wie ShareGPT4V erreicht, die gepaarte Bild-Text-Beispiele für die anfängliche Ausrichtung bereitstellen. Sprachvortraining, das eine Vielzahl von Datensätzen umfasste, darunter WIT-, WikiHow-und mehrsprachige OCR-Daten, um die Generalisierungsfähigkeiten des Modells über mehrere Domänen hinweg zu verbessern. Schließlich bestand die dritte Stufe aus einer überwachten Feinabstimmung (SFT). Dabei wurden aufgabenspezifische Datensätze verwendet, um die Leistung des Modells in Bereichen wie visuelle Grundlagen, Verständnis der grafischen Benutzeroberfläche (GUI) und dichte Untertitel zu verfeinern.
Diese Trainingsphasen ermöglichten es DeepSeek-VL2, eine solide Grundlage für zu schaffen multimodales Verständnis und ermöglicht gleichzeitig die Anpassung der Modelle an spezielle Aufgaben. Die Einbeziehung mehrsprachiger Datensätze verbesserte die Anwendbarkeit der Modelle in globalen Forschungs-und Industrieumgebungen weiter.
Verwandt: Das chinesische DeepSeek R1-Lite-Preview-Modell zielt auf die Führung von OpenAI im automatisierten Denken ab
Benchmarking-Ergebnisse
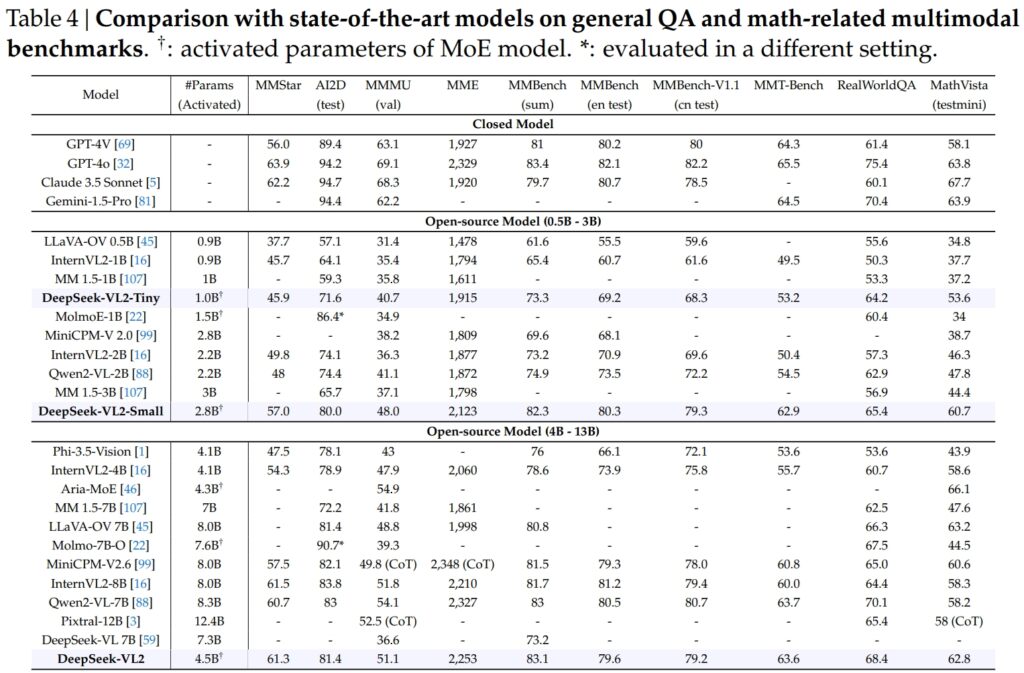
DeepSeek-VL2-Modelle, einschließlich der Tiny-, Small-und Standard-Varianten, übertrafen in kritischen Benchmarks für allgemeine Frage-Antwort-(QA) und mathematikbezogene multimodale Aufgaben.
DeepSeek-VL2-Small erreichte mit seinen 2,8 Milliarden aktivierten Parametern einen MMStar-Score von 57,0 und übertraf damit ähnlich große Modelle wie InternVL2-2B (49,8) und Qwen2-VL-2B (48,0). Es konkurrierte auch deutlich mit viel größeren Modellen wie dem 4,1B InternVL2-4B (54,3) und dem 8,3B Qwen2-VL-7B (60,7) und demonstrierte damit seine konkurrenzfähige Effizienz.
Beim AI2D-Test für Sicht Aufgrund seiner Argumentation erreichte DeepSeek-VL2-Small eine Punktzahl von 80,0 und übertraf damit InternVL2-2B (74,1) und MM 1,5-3B (nicht gemeldet). Selbst im Vergleich zu größeren Konkurrenten wie InternVL2-4B (78,9) und MiniCPM-V2.6 (82,1) zeigte DeepSeek-VL2 starke Ergebnisse mit weniger aktivierten Parametern.
 Quelle: DeepSeek
Quelle: DeepSeek
Das Flaggschiff Das DeepSeek-VL2-Modell (4,5 Milliarden aktivierte Parameter) lieferte außergewöhnliche Ergebnisse und erreichte 61,3 bei MMStar und 81,4 bei AI2D. Es übertraf Konkurrenten wie Molmo-7B-O (7,6B aktivierte Parameter, 39,3) und MiniCPM-V2.6 (8,0B, 57,5) und bestätigte damit seine technische Überlegenheit.
Hervorragende OCR-Verwandte Benchmarks
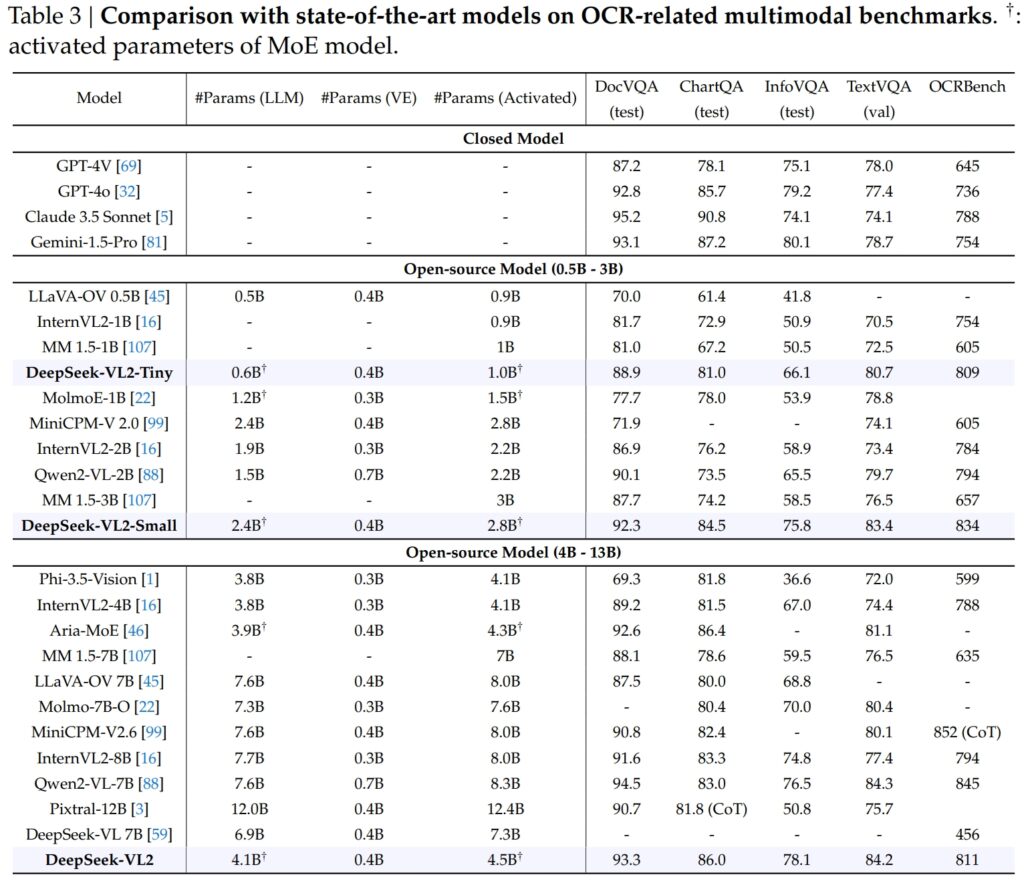
Die Fähigkeiten von DeepSeek-VL2 erstrecken sich vor allem auf Aufgaben im Zusammenhang mit OCR (optische Zeichenerkennung), einem entscheidenden Bereich für das Dokumentenverständnis und die Textextraktion in KI. Im DocVQA-Test erreichte DeepSeek-VL2-Small eine beeindruckende Genauigkeit von 92,3 % und übertraf damit alle anderen Open-Source-Modelle ähnlicher Größenordnung, einschließlich InternVL2-4B (89,2 %) und MiniCPM-V2.6 (90,8 %). Seine Genauigkeit lag knapp hinter den geschlossenen Modellen wie GPT-4o (92,8) und Claude 3.5 Sonnet (95,2).
Das DeepSeek-VL2-Modell führte auch im ChartQA-Test mit einer Punktzahl von 86,0 und übertraf damit InternVL2-4B (81,5) und MiniCPM-V2.6 (82,4). Dieses Ergebnis spiegelt die fortschrittliche Fähigkeit von DeepSeek-VL2 wider, Diagramme zu verarbeiten und Erkenntnisse aus komplexen visuellen Daten zu extrahieren.
 Quelle: DeepSeek
Quelle: DeepSeek
In OCRBench, einem äußerst wettbewerbsfähigen Als Metrik für feinkörnige Texterkennung erreichte DeepSeek-VL2 811 und übertraf damit 7,6B Qwen2-VL-7B (845) und MiniCPM-V2.6 (852 mit CoT) und unterstreicht seine Stärke bei dichten OCR-Aufgaben.
Vergleich mit führenden Vision-Language-Modellen
In Kombination mit Branchenführern wie GPT-4V von OpenAI und Gemini-1.5-Pro von Google bieten DeepSeek-VL2-Modelle eine überzeugende Balance von Leistung und Effizienz. Beispielsweise erzielte GPT-4V in DocVQA einen Wert von 87,2 und liegt damit nur geringfügig vor DeepSeek-VL2 (93,3), obwohl letzteres unter einem Open-Source-Framework mit weniger aktivierten Parametern läuft.
Bei TextVQA DeepSeek-VL2-Small erreichte 83,4 und übertraf damit deutlich ähnliche Open-Source-Modelle wie InternVL2-2B (73,4) und MiniCPM-V2.0 (74.1). Sogar der viel größere MiniCPM-V2.6 (8.0B) erreichte nur 80,4, was die Skalierbarkeit und Effizienz der Architektur von DeepSeek-VL2 weiter unterstreicht.
Für ChartQA übertraf der Wert von DeepSeek-VL2 mit 86,0 den von Pixtral-12B (81,8) und InternVL2-8B (83,3) und demonstriert damit seine Fähigkeit, bei speziellen Aufgaben hervorragende Leistungen zu erbringen die ein präzises visuell-textuelles Verständnis erfordern.
Verwandt: Mistral AI stellt Pixtral 12B für die Text-und Bildverarbeitung vor
Erweiterung der Anwendungen: Von fundierten Gesprächen bis hin zu Visuelles Geschichtenerzählen
Ein bemerkenswertes Merkmal der DeepSeek-VL2-Modelle ist ihre Fähigkeit, fundierte Gespräche zu führen, bei denen das Modell Objekte in Bildern identifizieren und sie in den Kontext integrieren kann Diskussionen.
Durch die Verwendung eines speziellen Tokens kann das Modell beispielsweise objektspezifische Details wie Standort und Beschreibung bereitstellen, um Anfragen zu Bildern zu beantworten. Dies eröffnet Möglichkeiten für Anwendungen in der Robotik, Augmented Reality und digitalen Assistenten, bei denen präzises visuelles Denken erforderlich ist.
Ein weiterer Anwendungsbereich ist das visuelle Storytelling. DeepSeek-VL2 kann kohärente Erzählungen auf der Grundlage einer Bildsequenz generieren und kombiniert dabei seine fortschrittlichen visuellen Erkennungs-und Sprachfähigkeiten.
Dies ist besonders wertvoll in Bereichen wie Bildung, Medien und Unterhaltung, in denen die dynamische Erstellung von Inhalten Priorität hat. Die Modelle nutzen ein starkes multimodales Verständnis, um detaillierte und kontextbezogene Geschichten zu erstellen und visuelle Elemente wie Orientierungspunkte und Text nahtlos in die Erzählung zu integrieren.
Die Fähigkeit der Modelle zur visuellen Erdung ist ebenso stark. In Tests mit komplexen Bildern hat DeepSeek-VL2 die Fähigkeit bewiesen, Objekte anhand beschreibender Eingabeaufforderungen genau zu lokalisieren und zu beschreiben.
Wenn das Modell beispielsweise aufgefordert wird, ein „auf der linken Straßenseite geparktes Auto“ zu identifizieren, kann es das genaue Objekt im Bild lokalisieren und Begrenzungsrahmenkoordinaten generieren, um seine Reaktion zu veranschaulichen. Diese Funktionen machen Es eignet sich hervorragend für autonome Systeme und Überwachung, bei denen eine detaillierte visuelle Analyse von entscheidender Bedeutung ist.
Open-Source-Zugänglichkeit und Skalierbarkeit
Die Entscheidung von DeepSeek AI, DeepSeek zu veröffentlichen-VL2 als Open-Source steht in scharfem Kontrast zum proprietären Charakter von Konkurrenten wie GPT-4V von OpenAI und Gemini-Exp von Google, bei denen es sich um geschlossene Systeme handelt, die für einen eingeschränkten öffentlichen Zugriff konzipiert sind.
Der technischen Dokumentation zufolge „durch die Erstellung unserer Pre „Trainierte Modelle und Code sind öffentlich verfügbar. Unser Ziel ist es, den Fortschritt bei der Vision-Language-Modellierung zu beschleunigen und kollaborative Innovationen in der gesamten Forschungsgemeinschaft zu fördern.“
Die Skalierbarkeit von DeepSeek-VL2 erhöht ihre Attraktivität zusätzlich. Die Modelle sind für den Einsatz in einer Vielzahl von Hardwarekonfigurationen optimiert, von einzelnen GPUs mit 10 GB Speicher bis hin zu Multi-GPU-Setups, die große Arbeitslasten bewältigen können.
Diese Flexibilität stellt sicher, dass DeepSeek-VL2 von Organisationen jeder Größe, vom Start-up bis zum Großunternehmen, genutzt werden kann, ohne dass eine spezielle Infrastruktur erforderlich ist.
Innovationen in Daten und Training
Ein wesentlicher Faktor für den Erfolg von DeepSeek-VL2 sind seine umfangreichen und vielfältigen Trainingsdaten. In der Vortrainingsphase wurden Datensätze wie WIT, WikiHow und OBELICS einbezogen, die eine Mischung aus verschachtelten Bild-Text-Paaren zur Verallgemeinerung bereitstellten.
Zusätzliche Daten für spezifische Aufgaben, wie OCR und visuelle Beantwortung von Fragen, stammten aus Quellen wie LaTeX OCR und PubTabNet, wodurch sichergestellt wurde, dass die Modelle sowohl allgemeine als auch spezielle Aufgaben mit hoher Genauigkeit bewältigen konnten.
Die Einbeziehung mehrsprachiger Datensätze spiegelt auch das Ziel der globalen Anwendbarkeit von DeepSeek AI wider. Chinesischsprachige Datensätze wie Wanjuan wurden neben englischen Datensätzen integriert, um sicherzustellen, dass die Modelle in mehrsprachigen Umgebungen effektiv funktionieren können.
Dieser Ansatz verbessert die Benutzerfreundlichkeit von DeepSeek-VL2 in Regionen, in denen nicht-englische Daten dominieren, und erweitert die potenzielle Benutzerbasis erheblich.
Die überwachte Feinabstimmungsphase verfeinerte die Modelle weiter Fähigkeiten, indem Sie sich auf bestimmte Aufgaben wie das Verständnis der grafischen Benutzeroberfläche und die Diagrammanalyse konzentrieren. Durch die Kombination interner Datensätze mit hochwertigen Open-Source-Ressourcen erreichte DeepSeek-VL2 bei mehreren Benchmarks Spitzenleistungen und bestätigte damit die Wirksamkeit seiner Trainingsmethodik.
Die sorgfältige Kuratierung von DeepSeek AI Dank der großen Datenmenge und der innovativen Trainingspipeline konnten VL2-Modelle bei einer Vielzahl von Aufgaben hervorragende Leistungen erbringen und gleichzeitig Effizienz und Skalierbarkeit beibehalten. Diese Faktoren machen sie zu einer wertvollen Ergänzung im Bereich der multimodalen KI.
Die Fähigkeit der Modelle, komplexe Bildverarbeitungsaufgaben wie visuelle Erdung und dichte OCR zu bewältigen, macht sie ideal für Branchen wie Logistik und Sicherheit. In der Logistik können sie die Bestandsverfolgung automatisieren, indem sie Bilder des Lagerbestands analysieren, Artikel identifizieren und Ergebnisse in Bestandsverwaltungssysteme integrieren.
Im Sicherheitsbereich kann DeepSeek-VL2 bei der Überwachung helfen, indem es Objekte oder Personen in Echtzeit auf der Grundlage beschreibender Abfragen identifiziert und den Bedienern detaillierte Kontextinformationen bereitstellt.
DeepSeek-Die Grounded-Conversation-Funktion von VL2 bietet auch Möglichkeiten in der Robotik und Augmented Reality. Ein mit diesem Modell ausgestatteter Roboter könnte beispielsweise seine Umgebung visuell interpretieren, auf menschliche Anfragen zu bestimmten Objekten reagieren und Aktionen basierend auf seinem Verständnis der visuellen Eingaben ausführen.
In ähnlicher Weise können Augmented-Reality-Geräte die visuellen Boden-und Storytelling-Funktionen des Modells nutzen, um interaktive, immersive Erlebnisse wie geführte Touren oder kontextbezogene Überlagerungen in Echtzeitumgebungen bereitzustellen.
Herausforderungen und Zukunftsaussichten
Trotz seiner zahlreichen Stärken steht DeepSeek-VL2 vor mehreren Herausforderungen. Eine wesentliche Einschränkung ist die Größe des Kontextfensters, die derzeit die Anzahl der Bilder einschränkt, die innerhalb einer einzelnen Interaktion verarbeitet werden können.
Die Erweiterung dieses Kontextfensters in zukünftigen Iterationen würde umfangreichere Interaktionen mit mehreren Bildern ermöglichen und den Nutzen des Modells bei Aufgaben verbessern, die ein breiteres Kontextverständnis erfordern.
Eine weitere Herausforderung liegt im Umgang mit Out-of-Domäne oder visuelle Eingaben von geringer Qualität, wie z. B. verschwommene Bilder oder Objekte, die nicht in den Trainingsdaten vorhanden sind. Während DeepSeek-VL2 bemerkenswerte Generalisierungsfähigkeiten gezeigt hat, wird die Verbesserung der Robustheit gegenüber solchen Eingaben seine Anwendbarkeit in realen Szenarien weiter erhöhen.
Mit Blick auf die Zukunft plant DeepSeek AI, die Argumentationsfähigkeiten seiner Modelle zu stärken, damit sie immer komplexere multimodale Aufgaben bewältigen können. Durch die Integration verbesserter Trainingspipelines und die Erweiterung von Datensätzen, um vielfältigere Szenarien abzudecken, könnten zukünftige Versionen von DeepSeek-VL2 neue Maßstäbe für die Leistung von Vision-Language-KI setzen.