Das chinesische KI-Unternehmen Moonshot AI hat ein neues Open-Source-Modell namens Kimi K2 Thinking. Es wurde am 6. November von seinem Stützpunkt in Peking aus gestartet und markiert einen großen Schritt im globalen Wettlauf um die Entwicklung eigenständig agierender KI.
Das Modell ist ein „denkender Agent“. Es kann schwierige Probleme lösen, indem es digitale Werkzeuge in Hunderten von Schritten nutzt. Moonshot will seine Konkurrenten auf Chinas hartem KI-Markt schlagen.
Nach den Billionen-Parameter-Modellen Kimi K2 und Kimi K2 Turbo konzentriert sich diese neue Version auf High-Level-Argumentation und erzielt Spitzenwerte bei Branchentests.
Das Unternehmen hat Kimi K2 Thinking nicht nur als Upgrade positioniert, sondern als eine neue Modellklasse, die sich auf die autonome Ausführung konzentriert. Es ist als „denkender Agent“ konzipiert, der in der Lage ist, Schritt für Schritt zu argumentieren, um komplexe Probleme zu lösen.
Eine wichtige Fähigkeit, die das Unternehmen hervorhebt, ist seine Fähigkeit, zwischen 200 und 300 aufeinanderfolgende Werkzeugaufrufe auszuführen, wodurch es komplizierte, mehrstufige Aufgaben ohne menschliches Eingreifen erledigen kann.
Im Gegensatz zu seinem Vorgänger, Kimi K2 Turbo, der sich auf pure Geschwindigkeit konzentrierte, legt diese neue Version Wert auf kognitive Tiefe. Seine zugrunde liegende Architektur bleibt ein riesiges Mixture-of-Experts-Modell (MoE) mit einer Billion Parametern, das 32 Milliarden Parameter für jeden gegebenen Token aktiviert.
Laut der offiziellen Modellkarte verfügt es über eine erweiterte Kontextlänge von 256 KB. Dieses riesige Fenster ermöglicht die Verarbeitung und Analyse ganzer Codebasen oder Hunderter Seiten von Dokumenten in einem einzigen Durchgang, eine entscheidende Funktion für komplexe Unternehmensaufgaben.
Eine bedeutende technische Innovation ist die native INT4-Quantisierung, die durch eine Methode namens Quantization-Aware Training (QAT) erreicht wird. Dadurch kann das Modell mit Berechnungen mit geringerer Präzision ausgeführt werden, was seine Inferenzgeschwindigkeit effektiv verdoppelt und gleichzeitig die Leistung seiner höherpräzisen Gegenstücke beibehält.
Für Entwickler wird die Bereitstellung eines Billionen-Parameter-Modells rechnerisch durchführbarer und kostengünstiger, wodurch eine große Hürde für die Einführung gesenkt wird.
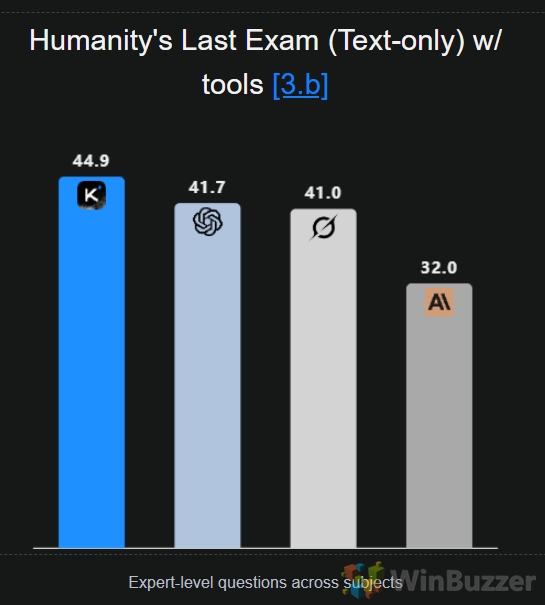
Moonshot berichtet, dass Kimi K2 Thinking beim Humanity’s Last Exam (mit Tools), einem Test des Wissens auf Expertenebene, 44,9 Punkte erzielt hat. Bei Agenten-Such-und Browsing-Aufgaben wie BrowseComp erreichte es 60,2 und beim Agenten-Codierungstest SWE-Bench Verified erreichte es 71,3. (Siehe die vollständige Benchmark-Tabelle am Ende)
Diese Ergebnisse platzieren es an der Spitze der Open-Source-Modelle, die für Agentenfunktionen entwickelt wurden.
Ein strategischer Schachzug in Chinas erbitterten KI-Kriegen
Die Veröffentlichung von Kimi K2 Thinking ist ein kalkulierter Schachzug auf Chinas hart umkämpftem KI-Markt, der oft als „Krieg der hundert Modelle“ bezeichnet wird.
Moonshot AI, einst ein aufstrebender Stern, stand unter starkem Druck von inländischen Konkurrenten wie DeepSeek, Z.ai und Alibaba. Dieses neue Modell ist ein direkter Versuch, die Führung zurückzugewinnen, indem der Wettbewerbsschwerpunkt von Geschwindigkeit und Preis auf ausgefeilte Argumentation und Agentenleistung verlagert wird.
Diese Wende erfolgt nach einer herausfordernden Zeit für das Unternehmen. Sein ursprüngliches Modell Kimi K2, das im Juli auf den Markt kam, war ein mutiges Open-Source-Spiel.
Der Markt wurde jedoch schnell mit kostengünstigen Alternativen gesättigt, insbesondere vom Konkurrenten DeepSeek, was einen heftigen Preiskampf auslöste. Dies wirkte sich direkt auf die Nutzerbasis der Kimi-Chat-Anwendung von Moonshot aus, deren inländisches Ranking abrutschte.
Neue Daten für Oktober 2025 von Statcounter bestätigen die starke Konkurrenz und zeigen, dass Moonshot derzeit nicht zu den bestplatzierten KI-Chatbot-Anbietern in China gehört.
Moonshot geht davon aus, dass überlegene Fähigkeiten im aufstrebenden Bereich der Agenten-KI eine vertretbarere Marktposition aufbauen können, als wenn man nur über die Kosten konkurriert. Allerdings birgt dieser intensive Fokus auf die Leistung in der Bestenliste seine eigenen Risiken.
Wie der KI-Stratege Nate Jones zuvor bemerkte: „In dem Moment, in dem wir uns die Dominanz in der Bestenliste zum Ziel setzen, laufen wir Gefahr, Modelle zu schaffen, die sich in trivialen Übungen auszeichnen und angesichts der Realität scheitern.“ Moonshot möchte beweisen, dass seine Benchmark-Siege in den realen Nutzen umgesetzt werden, der zur Rückgewinnung von Marktanteilen erforderlich ist.
[eingebetteter Inhalt]
Der globale Wettlauf um die Vorherrschaft der Agenten
Moonshots jüngste Bemühungen sind Teil eines grundlegenden globalen Wandels in der KI-Branche. Unternehmen gehen über Chatbots hinaus, die lediglich Text-oder Codevorschläge generieren.
Ihr neues Feld ist die Agentische Intelligenz: die Schaffung autonomer Systeme, die ein übergeordnetes Ziel verstehen, einen Plan formulieren und eine Vielzahl digitaler Tools verwenden können, um es auszuführen. Kimi K2 Thinking ist ausdrücklich darauf ausgelegt, in diesem Bereich zu konkurrieren.
Der Wert dieses Agentenansatzes hat sich bereits in der Unternehmenswelt bewährt. In einem bahnbrechenden Schritt begann die Investmentbank Goldman Sachs mit der Pilotierung des autonomen KI-Programmierers Devin, um eine „hybride Belegschaft“ zu schaffen. Seine Vision besteht darin, dass menschliche Ingenieure Flotten von KI-Agenten überwachen und so die Natur der Softwareentwicklung verändern.
Goldmans Technologiechef Marco Argenti erklärte die Strategie mit den Worten: „Es geht wirklich darum, dass Menschen und KI Seite an Seite arbeiten. Von Ingenieuren wird erwartet, dass sie die Fähigkeit haben, Probleme wirklich kohärent zu beschreiben und sie in Aufforderungen umzuwandeln…“
Ein solcher Wandel spiegelt eine Zukunft wider, in der die primäre menschliche Fähigkeit nicht ermüdend ist Ausführung, aber Problemdefinition und-überwachung auf hohem Niveau.
Durch die Entwicklung eines Modells, das sich durch die Verwendung komplexer, mehrstufiger Werkzeuge auszeichnet, positioniert sich Moonshot AI als Schlüsselakteur in diesem neuen Paradigma. Mit Kimi K2 Thinking geht das Unternehmen eine riskante Wette ein, dass in einer Welt voller leistungsstarker Modelle dasjenige, das am effektivsten argumentieren kann, letztendlich das Entwickler-Ökosystem gewinnen wird.
Kimi K2 Benchmarks
(Quelle: Moonshot AI)