Das KI-Team von Meta steht nach der Veröffentlichung des R1-Modells von DeepSeek, das die KI-Branche mit seiner beispiellosen Effizienz und Leistung herausgefordert hat, unter großem Druck.
Anonyme Beiträge auf der professionellen Netzwerkplattform Blind offenbaren Aufruhr in Metas Reihen. Ingenieure beschreiben einen verzweifelten Versuch, den Erfolg von DeepSeek zu verstehen und nachzubilden, während sie sich gleichzeitig mit internen Ineffizienzen und Fehltritten der Führung auseinandersetzen.
Blind ist eine anonyme professionelle Networking-Plattform, auf der Mitarbeiter Informationen austauschen und über den Arbeitsplatz diskutieren können Probleme zu lösen und sich mit Kollegen aus der gleichen oder einer anderen Branche zu vernetzen. Es verfügt über ein Verifizierungssystem, um sicherzustellen, dass es sich bei den Benutzern um tatsächliche Mitarbeiter der Unternehmen handelt, für die sie angeblich arbeiten, und ist vor allem bei Fachleuten in der Technologiebranche beliebt.
Verwandt: Wie DeepSeek R1 übertrifft ChatGPT o1 unter Sanktionen und definiert die KI-Effizienz mit nur 2.048 GPUs neu
Ein anonymer Meta-Mitarbeiter, Posting unter dem Namen „ngi”fasste die Stimmung innerhalb der GenAI-Abteilung von Meta zusammen:
„Es begann mit DeepSeek V3 [einem im Dezember 2024 veröffentlichten DeepSeek-Modell], das Llama 4 in den Benchmarks bereits hinterherhinkte. Was noch schlimmer wurde, war das „unbekannte chinesische Unternehmen mit 5,5 Millionen Schulungsbudgets“. Wir arbeiten hektisch daran, DeepSeek zu zerlegen und alles zu kopieren, was wir können.
Ich übertreibe nicht einmal. Das Management ist besorgt darüber, die enormen Kosten der GenAI-Organisation zu rechtfertigen. Wie würden sie der Führung gegenübertreten, wenn jeder einzelne „Leiter“ der GenAI-Organisation mehr verdient, als es kostet, DeepSeek V3 vollständig zu trainieren, und wir Dutzende solcher „Leiter“ haben, macht die Sache noch beängstigender.“
Die Kommentare des Mitarbeiters verdeutlichen die interne Unzufriedenheit mit Metas Ansatz zur KI-Entwicklung, den viele als übermäßig bürokratisch, ressourcenintensiv und eher von oberflächlichen Kennzahlen als von sinnvollen Innovationen getrieben beschreiben.
Die Veröffentlichung von DeepSeek R1 hat diese Mängel aufgedeckt und eine Abrechnung für einen der größten Akteure der KI-Branche erzwungen.
Verwandt: LLaMA AI Under Fire – Was Meta Ihnen nicht über „Open-Source“-Modelle sagt
DeepSeek R1 sendet Schockwellen durch den US-amerikanischen Technologiesektor
DeepSeeks Das am 10. Januar 2025 veröffentlichte R1-Modell hat die globale KI-Landschaft auf den Kopf gestellt, indem es gezeigt hat, dass Hochleistungsmodelle zu einem Bruchteil der Kosten entwickelt werden können, die normalerweise mit solchen Projekten verbunden sind.
Unter Verwendung von Nvidia H800-GPUs – minderwertige Chips, die durch US-Exportkontrollen eingeschränkt werden – trainierten DeepSeek-Ingenieure das Modell laut einem im Dezember 2024 veröffentlichten Forschungsbericht für weniger als 6 Millionen US-Dollar.
Diese GPUs, die absichtlich gedrosselt wurden, um US-Sanktionen einzuhalten, stellten besondere Herausforderungen dar, aber die Optimierungstechniken von DeepSeek ermöglichten es dem Team, eine mit branchenführenden Modellen vergleichbare Leistung zu erzielen.
Die Benchmarks von R1 umfassen einen Wert von 97,3 % bei MATH-500 und einen Wert von 79,8 % bei AIME 2024, womit es zu den leistungsfähigsten KI-Systemen der Welt gehört.
Die Effizienz von DeepSeek R1, das auch das o1-Modell von OpenAI teilweise übertrifft, hat nicht nur das Vertrauen in US-amerikanische Technologiegiganten wie Meta erschüttert, sondern auch erhebliche Marktreaktionen ausgelöst.
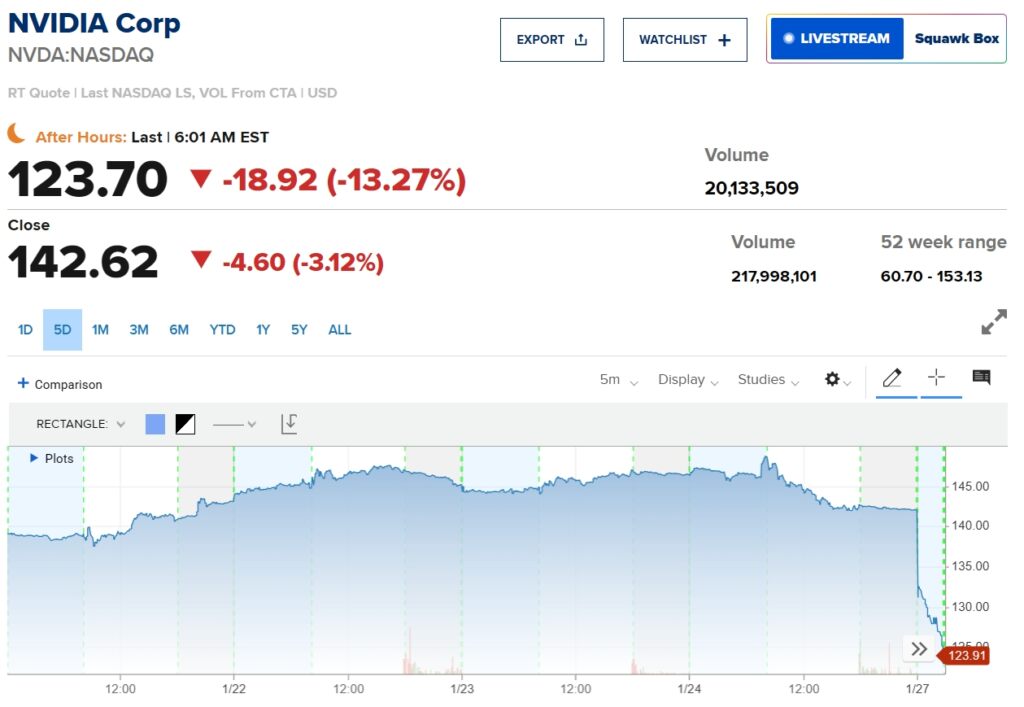
Nvidias Aktien fielen im vorbörslichen Handel nach der Veröffentlichung des Modells um über 13 % und die Nasdaq 100-Futures fielen um mehr als 5 %. Mittlerweile ist DeepSeek im US-App Store von Apple an die Spitze geklettert und hat ChatGPT von OpenAI bei den Downloads übertroffen.
Meta-Ingenieure stellen die Abhängigkeit von teurem computergestütztem KI-Training in Frage
Innerhalb von Meta haben Ingenieure kritisiert, dass sich das Unternehmen auf rohe Rechenleistung verlässt, anstatt effizienzorientierte Innovationen zu verfolgen.
Ein Mitarbeiter bemerkte zu Blind: „Ein Großteil der Führung hat buchstäblich keine Ahnung (nicht einmal viel Technik) von der zugrunde liegenden Technologie und verkauft der Führung ständig ‚mehr GPUs=Gewinn‘.“ Ein anderer teilte mit Frustration über die Kultur des „Impact Chasing“, die sie als einen Wettlauf um Beförderungen und nicht als Verpflichtung zu sinnvollen Fortschritten beschreibt.
Die KI-Bemühungen von Meta wurden auch wegen ihrer mangelnden Agilität im Vergleich zu Wettbewerbern auf den Prüfstand gestellt. Das R1-Modell von DeepSeek ist nicht nur kostengünstig, sondern auch Open Source, sodass Entwickler weltweit die Architektur untersuchen und darauf aufbauen können.
The Blind-Diskussionen offenbaren auch umfassendere Bedenken der Branche. Google-Mitarbeiter erkannten die disruptive Wirkung von DeepSeek an und bemerkten: „Es ist wirklich verrückt, was DeepSeek macht.“ Es ist nicht nur Meta, sie entzünden auch ein Feuer unter OpenAI, Google und Anthropic. Und das ist gut so, denn wir sehen in Echtzeit, wie effektiv ein offener Wettbewerb für Innovationen ist.“
Diese Einschätzung spiegelt die wachsende Erkenntnis wider, dass traditionelle ressourcenintensive Strategien möglicherweise keine Dominanz mehr in der KI-Entwicklung garantieren.
Diese Transparenz wurde von Branchenführern gelobt, darunter Metas Chef-KI-Wissenschaftler Yann LeCun, der auf LinkedIn schrieb: „DeepSeek hat von offener Forschung und Open Source profitiert (z. B. PyTorch und Llama). von Meta). Sie kamen auf neue Ideen und bauten sie auf der Arbeit anderer auf.“
Mark Zuckerberg verdoppelt seine Investitionen in die KI-Infrastruktur
Im krassen Gegensatz dazu hat sich Meta auf groß angelegte Infrastrukturinvestitionen konzentriert. CEO Mark Zuckerberg kündigte kürzlich Pläne an, im Jahr 2025 über 1,3 Millionen GPUs einzusetzen und 60 bis 65 Milliarden US-Dollar in die KI-Entwicklung zu investieren.
„Dies ist eine gewaltige Anstrengung, die in den kommenden Jahren unsere Kernprodukte und unser Geschäft vorantreiben, historische Innovationen freisetzen und die Technologieführerschaft Amerikas ausbauen wird“, sagte Zuckerberg Anfang des Jahres in einer öffentlichen Erklärung. Diese Pläne stehen jedoch zunehmend im Widerspruch zum schlanken, auf Effizienz ausgerichteten Ansatz von DeepSeek.
Der Aufstieg von DeepSeek hat seit 2021 auch die Debatten über US-Exportbeschränkungen für KI-bezogene Technologien nach China neu entfacht. Die Biden-Regierung hat Maßnahmen ergriffen, um Chinas Zugang zu fortschrittlichen Chips, einschließlich der H100-GPUs, einzuschränken.
Die Fähigkeit von DeepSeek, mit eingeschränkter Hardware erstklassige Ergebnisse zu erzielen, unterstreicht jedoch die Grenzen dieser Richtlinien Bevor die Sanktionen ihre volle Wirkung entfalteten und sich auf Effizienz konzentrierte, hat DeepSeek Einschränkungen in Vorteile umgewandelt.
Gründer Liang Wenfeng, ein ehemaliger Hedge Der Fondsmanager beschrieb die Strategie des Unternehmens wie folgt: „Wir gehen davon aus, dass die besten inländischen und ausländischen Modelle in der Modellstruktur und Trainingsdynamik möglicherweise eine Lücke von einem Faktor 1 aufweisen.“ Aus diesem Grund müssen wir viermal mehr Rechenleistung verbrauchen, um den gleichen Effekt zu erzielen. Was wir tun müssen, ist, diese Lücken kontinuierlich zu schließen.“
Während die KI-Branche mit den Auswirkungen des Erfolgs von DeepSeek zu kämpfen hat, steht Meta vor der dringenden Notwendigkeit, sich anzupassen. Die Mitarbeiter des Unternehmens haben ihre Frustration deutlich zum Ausdruck gebracht und gefordert Ein Wandel hin zu effizienteren, innovationsgetriebenen Strategien. Das R1-Modell von DeepSeek ist derzeit ein eindrucksvoller Beweis für einfallsreiches Engineering, das die Wettbewerbsdynamik der globalen KI-Entwicklung neu gestaltet.