Hugging Face hat zwei leichte KI-Modelle vorgestellt, SmolVLM-256M-Instruct und SmolVLM-500M-Instruct, die darauf abzielen, neu zu definieren, wie KI auf Geräten mit begrenzter Rechenleistung funktionieren kann.
Die Modelle verwenden 256 Millionen bzw. 500 Millionen Parameter und sind darauf ausgelegt, die Herausforderungen zu bewältigen, denen sich Entwickler gegenübersehen, die mit eingeschränkter Hardware oder umfangreichen Datenanalysen bei minimalen Kosten arbeiten.
Die Veröffentlichung stellt einen Durchbruch in der Effizienz und Zugänglichkeit der KI-Verarbeitung dar. SmolVLM-Modelle bieten erweiterte multimodale Funktionen und ermöglichen Aufgaben wie die Beschreibung von Bildern, die Analyse kurzer Videos und die Beantwortung von Fragen zu PDFs oder wissenschaftlichen Diagrammen.
Wie Hugging Face erklärt: „SmolVLM macht es schneller und kostengünstiger, durchsuchbar zu erstellen Datenbanken, mit Geschwindigkeiten, die mit Modellen konkurrieren, die das Zehnfache ihrer Größe haben.“
Multimodale KI mit kleineren Modellen neu definieren
SmolVLM-256M-Instruct und SmolVLM-500M-Instruct sind darauf ausgelegt, die Leistung zu maximieren und gleichzeitig den Ressourcenverbrauch zu minimieren Mehrere Formen von Daten – wie Text und Bilder – gleichzeitig, was sie für verschiedene Anwendungen vielseitig macht.
Trotz ihrer reduzierten Größe erreichen die Modelle vergleichbare Leistungsniveaus oder besser als viel größere Modelle wie Idefics 80B, laut Benchmarks wie AI2D, das die Fähigkeit zum Verstehen und Denken bewertet mit wissenschaftlichen Diagrammen.
Idefics 80B ist eine Open-Access-Reproduktion von DeepMinds Closed-Source-Bildsprachenmodell Flamingo, entwickelt von Hugging Face, das sowohl Bilder als auch Texteingaben verarbeiten kann.
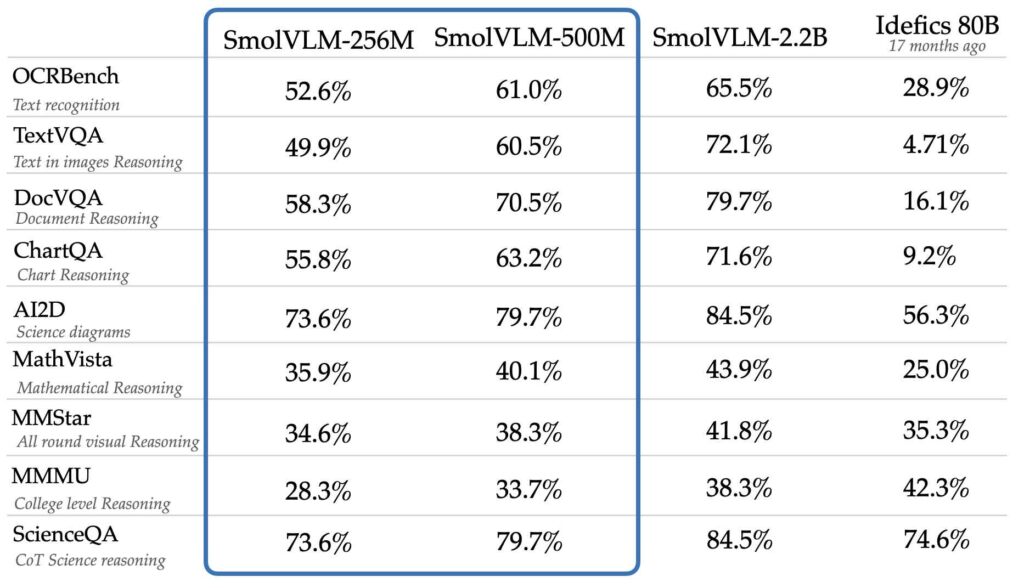 Quelle: Hugging Face
Quelle: Hugging Face
Die Entwicklung dieser Modelle stützte sich auf zwei proprietäre Datensätze: The Cauldron und Docmatix. „The Cauldron“ ist eine kuratierte Sammlung von 50 hochwertigen Bild-und Textdatensätzen, die den Schwerpunkt auf multimodales Lernen legt, während Docmatix auf das Verständnis von Dokumenten zugeschnitten ist und gescannte Dateien mit detaillierten Bildunterschriften kombiniert, um das Verständnis zu verbessern.
Das M4-Team von Hugging Face, bekannt für seine Expertise in multimodaler KI, war federführend bei der Erstellung dieser Datensätze.
In seiner Ankündigung betonte Hugging Face, wie wichtig es sei, KI zugänglicher zu machen. „Entwickler teilten uns mit, dass sie Modelle für Laptops oder sogar Browser benötigten, und dass das Feedback die Entwicklung dieser Modelle vorangetrieben hat“, erklärte das Team. Diese Modelle adressieren praktische Einschränkungen, mit denen viele Entwickler konfrontiert sind, insbesondere wenn sie mit Verbrauchergeräten oder budgetbewussten Vorgängen arbeiten.
Technische Innovationen in SmolVLM-Modellen
Ein entscheidender Faktor für den Erfolg der Modelle liegt in ihrem zugrunde liegenden Design. Hugging Face traf strategische Entscheidungen zur Verbesserung sowohl der Effizienz als auch Genauigkeit. Eine solche Entscheidung war die Einführung eines kleineren Vision-Encoders, SigLIP-Basispatch-16/512, anstelle des größeren SigLIP 400M SO verwendet in früheren Modellen wie SmolVLM 2B.
Dieser kleinere Encoder verarbeitet Bilder mit höheren Auflösungen, ohne den Rechenaufwand wesentlich zu erhöhen.
Eine weitere Innovation betrifft die Tokenisierung, einen Schlüsselprozess in KI-Modellen, bei dem Daten in kleinere Einheiten unterteilt werden ( Token) zur Analyse. Durch die Optimierung der Verarbeitung von Bild-Tokens reduzierte Hugging Face die Redundanz und verbesserte die Fähigkeit der Modelle, komplexe Daten zu verarbeiten.
Zum Beispiel werden Teilbild-Trennzeichen, die zuvor mehreren Tokens zugeordnet waren, jetzt mit einem einzigen Token dargestellt, was sowohl die Trainingsstabilität als auch die Inferenzqualität verbessert. „Mit SmolVLM definieren wir neu, was kleinere KI-Modelle erreichen können“, erklärte das Team in seiner Ankündigung.
Diese Designoptionen ermöglichen es SmolVLM-Modellen, Bilder mit einer Rate von 4.096 Pixeln pro Token zu kodieren, was eine beachtliche Zahl darstellt Verbesserung gegenüber den 1.820 Pixeln pro Token in früheren Versionen. Das Ergebnis ist ein schärferes visuelles Verständnis und schnellere Verarbeitungsgeschwindigkeiten.
SmolVLM-Perspektive für Anwendungen
Die praktischen Vorteile von SmolVLM gehen über typische KI-Anwendungsfälle hinaus. Entwickler können diese Modelle mithilfe von Tools wie Transformers, MLX und ONNX nahtlos integrieren Fein abgestimmte Prüfpunkte für beide Modelle ermöglichen eine einfache Anpassung an bestimmte Aufgaben.
Die Modelle eignen sich besonders gut für die Dokumentenanalyse und den Abruf. In Zusammenarbeit mit IBM wurde Hugging Face angewendet SmolVLM-256M für ihr Docling-System und demonstriert sein Potenzial bei der Automatisierung von Arbeitsabläufen und der Gewinnung von Erkenntnissen aus gescannten Dateien. Die ersten Ergebnisse dieser Partnerschaft waren vielversprechend und unterstreichen die Vielseitigkeit des Modells.
Darüber hinaus sind SmolVLM-Modelle unter einer Apache verfügbar 2.0-Lizenz, die den offenen Zugriff für Entwickler weltweit gewährleistet. Dieses Engagement für Open-Source-Entwicklung steht im Einklang mit der Mission von Hugging Face, KI zu demokratisieren und es mehr Organisationen zu ermöglichen, fortschrittliche Technologien einzuführen, ohne übermäßige Kosten in Kauf nehmen zu müssen.
Kosten und Leistung in Einklang bringen
Die Einführung von SmolVLM-256M und SmolVLM-500M vervollständigt die SmolVLM-Familie, die nun eine vollständige Palette kleinerer Vision Language-Modelle umfasst, die für verschiedene Anwendungen entwickelt wurden.
Diese Modelle sind besonders effektiv für Umgebungen mit begrenzten Ressourcen, wie z. B. Consumer-Laptops oder browserbasierte Anwendungen. Die 256M-Variante zeichnet sich als kleinstes jemals veröffentlichtes Vision-Language-Modell durch ihre Fähigkeit aus, robuste Leistung auf Geräten mit weniger als 1 GB RAM zu liefern.
Hugging Face stellt sich vor, dass SmolVLM eine praktische Lösung für Entwickler wird, die große Herausforderungen angehen-Skalieren Sie die Datenverarbeitung mit kleinem Budget.