DeepSeek hat seine neuesten Open-Source-KI-Modelle DeepSeek-R1 und DeepSeek-R1-Zero auf den Markt gebracht und definiert damit neu, wie Argumentationsfähigkeiten durch Reinforcement Learning (RL) erreicht werden können.
Die Neue Modelle stellen die konventionelle KI-Entwicklung in Frage, indem sie beweisen, dass Supervised Fine-Tuning (SFT) nicht unbedingt erforderlich ist Entwicklung fortgeschrittener Fähigkeiten zur Problemlösung. Mit Benchmark-Ergebnissen, die mit proprietären Systemen wie der o1-Serie von OpenAI konkurrieren, veranschaulichen die Modelle von DeepSeek das wachsende Potenzial von Open-Source-KI bei der Bereitstellung wettbewerbsfähiger, leistungsstarker Tools.
Der Erfolg dieser Modelle liegt in ihren einzigartigen Ansätzen zur Verstärkung Lernen (RL), die Einführung von Kaltstartdaten und ein effektiver Destillationsprozess. Diese Innovationen haben zu Denkfähigkeiten in den Bereichen Codierung, Mathematik und allgemeine Logikaufgaben geführt und die Realisierbarkeit von Open-Source-KI als Konkurrent führender proprietärer Modelle unterstrichen.
Verwandt: DeepSeek AI Open Sources VL2-Serie von Vision-Sprachmodellen
Benchmark-Ergebnisse unterstreichen Open-Source-Potenzial
Die Leistung von DeepSeek-R1 in weithin anerkannten Benchmarks bestätigt seine Fähigkeiten:
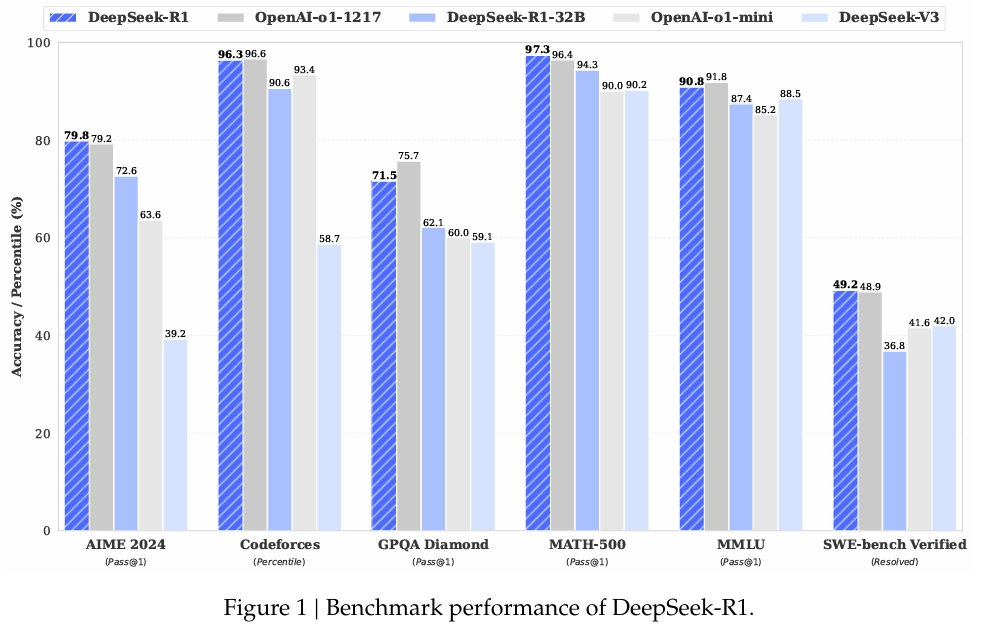
In MATH-500, einem Datensatz zur Bewertung mathematischer Problemlösungen, erreichte DeepSeek-R1 einen Pass@1-Score von 97,3 %, was dem von OpenAI entspricht Modell o1-1217. Beim AIME 2024-Benchmark, der sich auf fortgeschrittene Denkaufgaben konzentriert, erreichte das Modell 79,8 % und übertraf damit leicht die Ergebnisse von OpenAI.
Die Leistung des Modells in LiveCodeBench, einem Benchmark für Codierungs-und Logikaufgaben, war ebenso bemerkenswert ein Pass@1-CoT-Score von 65,9 %. Laut der Untersuchung von DeepSeek ist es damit eines der leistungsstärksten Open-Source-Modelle in dieser Kategorie.
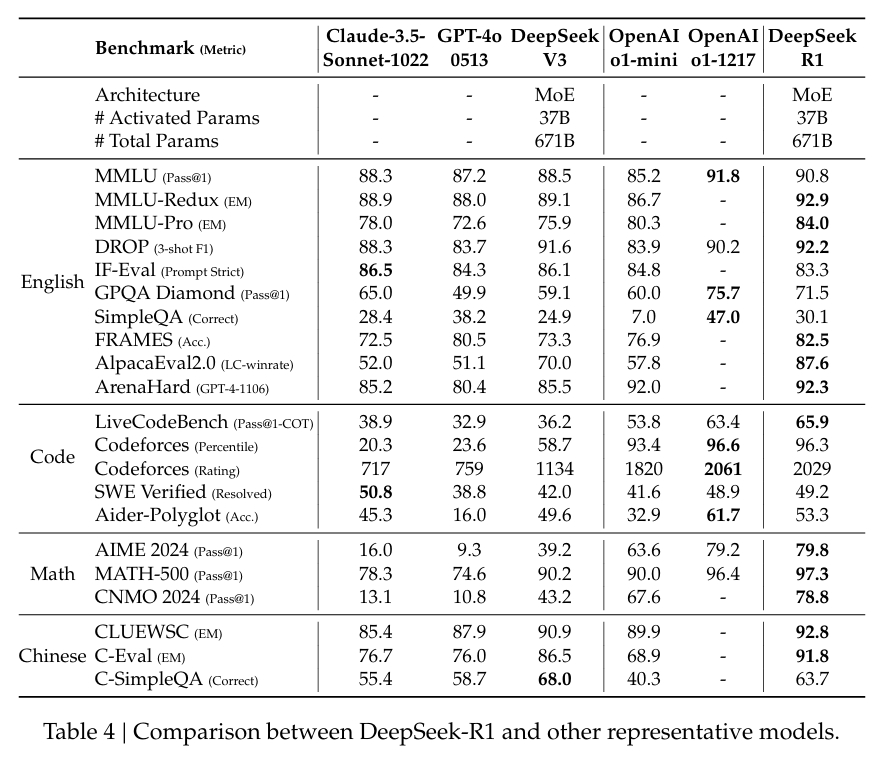
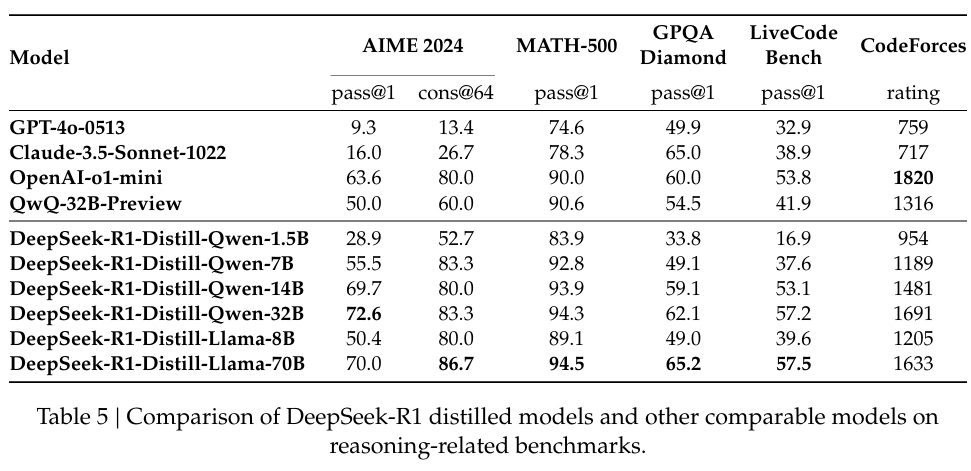
Das Unternehmen hat auch stark in die Destillation investiert, um sicherzustellen, dass kleinere Versionen verfügbar sind von DeepSeek-R1 behalten einen Großteil der Argumentationsfunktionen der größeren Modelle bei. Bemerkenswert ist, dass das 32-Milliarden-Parameter-Modell DeepSeek-R1-Distill-Qwen-32B das o1-mini von OpenAI in mehreren Kategorien übertraf und gleichzeitig rechnerisch zugänglicher war.
Bestärkendes Lernen ohne Aufsicht: DeepSeek-R1-Zero
DeepSeek-R1-Zero ist der mutige Forschungsversuch des Unternehmens Nur-RL-Training. Es verwendet einen einzigartigen Algorithmus, Group Relative Policy Optimization (GRPO), der das RL-Training optimiert, indem er die Notwendigkeit eines separaten Kritikermodells überflüssig macht.
Stattdessen werden gruppierte Bewertungen zur Schätzung von Basislinien verwendet, wodurch die Rechenkosten erheblich gesenkt werden Aufrechterhaltung der Ausbildungsqualität. Dieser Ansatz ermöglicht es dem Modell, Denkverhalten zu entwickeln, einschließlich Gedankenkettendenken (CoT) und Selbstreflexion.
In ihrem Forschungspapier, das DeepSeek-Team erklärte:
„DeepSeek-R1-Zero demonstriert Fähigkeiten wie Selbstverifizierung, Reflexion und die Generierung langer CoTs.“ Es hat jedoch Probleme mit Wiederholungen, Lesbarkeit und Sprachvermischung, wodurch es für reale Anwendungsfälle weniger geeignet ist.“
Während diese aufkommenden Verhaltensweisen vielversprechend waren, machten die Einschränkungen des Modells deutlich, dass es einer Verfeinerung bedarf. Zum Beispiel , seine Ausgaben wiederholten sich gelegentlich oder zeigten Probleme mit gemischten Sprachen, was die Benutzerfreundlichkeit in praktischen Szenarien verringerte.
Von RL-Only zum Hybrid-Training: DeepSeek-R1
Um diese Herausforderungen anzugehen, entwickelte DeepSeek DeepSeek-R1 und kombinierte RL mit überwachter Feinabstimmung. Der Prozess begann mit einem kuratierten Kaltstart-Datensatz aus langen, für Menschen lesbaren CoTs, der die Basiskohärenz und Lesbarkeit verbessern sollte Auf dieser Grundlage gelangte das Modell in RL mit einer verbesserten Fähigkeit, menschliche Erwartungen an Klarheit und Relevanz zu erfüllen.
Verwandt: LLaMA AI Under Fire: What Meta Isn’t Telling Sie über „Open Source“-Modelle
DeepSeek beschrieb diesen Ansatz in seiner Dokumentation:
„Im Gegensatz zu R1-Zero, um die frühe instabile Kaltstartphase des RL-Trainings vom Basismodell aus zu verhindern, haben wir für R1 Erstellen und sammeln Sie eine kleine Menge langer CoT-Daten, um das Modell als anfänglicher RL-Akteur zu verfeinern der Handhabung komplexe Szenarien wie Codierung und mathematische Beweise.
Open-Source-Zugänglichkeit und zukünftige Herausforderungen
DeepSeek hat seine Modelle unter der MIT-Lizenz veröffentlicht und unterstreicht damit sein Engagement zu Open-Source-Prinzipien. Dieses Lizenzmodell ermöglicht Forschern und Entwicklern die freie Nutzung, Änderung und Weiterentwicklung der Arbeit von DeepSeek und fördert so die Zusammenarbeit und Innovation in der KI-Community.
Trotz seiner Erfolge erkennt das Team an, dass weiterhin Herausforderungen bestehen. Ausgaben in gemischten Sprachen, schnelle Sensibilität und der Bedarf an besseren Software-Engineering-Fähigkeiten sind Bereiche mit Verbesserungsbedarf. Zukünftige Iterationen von DeepSeek-R1 werden darauf abzielen, diese Einschränkungen zu beseitigen und gleichzeitig seine Funktionalität auf neue Domänen auszudehnen.
Die Forscher äußerten sich optimistisch über ihre Fortschritte und erklärten:
„Durch die sorgfältige Gestaltung des Musters für Kalt-Wenn wir Daten mit menschlichen Prioritäten starten, beobachten wir eine bessere Leistung im Vergleich zu DeepSeek-R1-Zero. Wir glauben, dass das iterative Training ein besserer Weg für die Argumentation von Modellen ist , wo Open-Source-Modelle jetzt mit proprietären Marktführern konkurrieren können, indem DeepSeek beweist, dass RL ohne SFT auf hoher Ebene argumentieren kann, und die Destillation zur Skalierung der Zugänglichkeit betont wird.
Während sich Open-Source-KI weiterentwickelt, bieten die Fortschritte von DeepSeek-R1 eine Blaupause für die Nutzung von RL, um praktische, leistungsstarke Modelle zu erstellen.