Microsoft hat rStar-Math eingeführt, eine Fortsetzung und Verfeinerung seines früheren rStar-Framework, um die Grenzen kleiner Sprachmodelle (SLMs) im mathematischen Denken zu erweitern.
RStar-Math wurde entwickelt, um mit größeren Systemen wie o1-preview von OpenAI mithalten zu können. Es erreicht bemerkenswerte Benchmarks bei der Problemlösung und zeigt gleichzeitig, wie kompakte Modelle auf Wettbewerbsniveau funktionieren können. Diese Entwicklung zeigt eine Verschiebung der KI-Prioritäten hin von der Skalierung zur Optimierung der Leistung für bestimmte Aufgaben.
Der Fortschritt von rStar zu rStar-Math
Der rStar Das Framework vom letzten Sommer legte den Grundstein für die Verbesserung der SLM-Argumentation durch die Monte Carlo Tree Search (MCTS), ein Algorithmus, der Lösungen durch Simulation und Validierung mehrerer Pfade verfeinert.
rStar zeigte, dass kleinere Modelle komplexe Aufgaben bewältigen konnten, die Anwendung blieb jedoch allgemein. rStar-Math baut auf dieser Grundlage mit gezielten Innovationen auf, die auf das mathematische Denken zugeschnitten sind.
Im Mittelpunkt des Erfolgs von rStar-Math steht die Code-Augmented Chain-of-Thought (CoT)-Methodik, bei der das Modell in beiden Bereichen Lösungen liefert natürliche Sprache und ausführbarer Python-Code.
Diese Dual-Output-Struktur stellt sicher, dass Zwischenschritte der Argumentation überprüfbar sind, wodurch Fehler reduziert und die logische Konsistenz gewahrt bleibt. Die Forscher betonten die Bedeutung dieses Ansatzes und erklärten: „Gegenseitige Konsistenz spiegelt die übliche menschliche Praxis ohne Aufsicht wider, bei der die Übereinstimmung unter Gleichaltrigen über abgeleitete Antworten eine höhere Wahrscheinlichkeit der Richtigkeit nahelegt.“
Verwandt: Das chinesische DeepSeek R1-Lite-Preview-Modell zielt auf den Vorsprung von OpenAI im automatisierten Denken ab
Zusätzlich zu CoT führt rStar-Math ein Process Preference Model (PPM) ein, das Bewertet und ordnet Zwischenschritte basierend auf der Qualität. Im Gegensatz zu herkömmlichen Belohnungssystemen, die häufig auf verrauschten Daten basieren, legt das PPM Wert auf logische Kohärenz und Genauigkeit und verbessert so die Zuverlässigkeit des Modells:
„Das PPM nutzt die.“ Tatsache ist, dass Q-Werte zwar immer noch nicht präzise genug sind, um jeden Argumentationsschritt zu bewerten, trotz der Verwendung umfangreicher MCTS-Rollouts, die Q-Werte jedoch zuverlässig positive (richtige) Schritte von negativen (irrelevant/falsch) unterscheiden können. Einsen.
Daher erstellt die Trainingsmethode Präferenzpaare für jeden Schritt auf der Grundlage von Q-Werten und nutzt einen paarweisen Ranking-Verlust, um die Score-Vorhersage von PPM für jeden Argumentationsschritt zu optimieren und so eine zuverlässige Kennzeichnung zu erreichen. Dieser Ansatz vermeidet herkömmliche Methoden, die Q-Werte direkt als Belohnungsbezeichnungen verwenden, die bei der schrittweisen Belohnungszuweisung von Natur aus verrauscht und ungenau sind Richtlinienmodell und PPM von Grund auf.
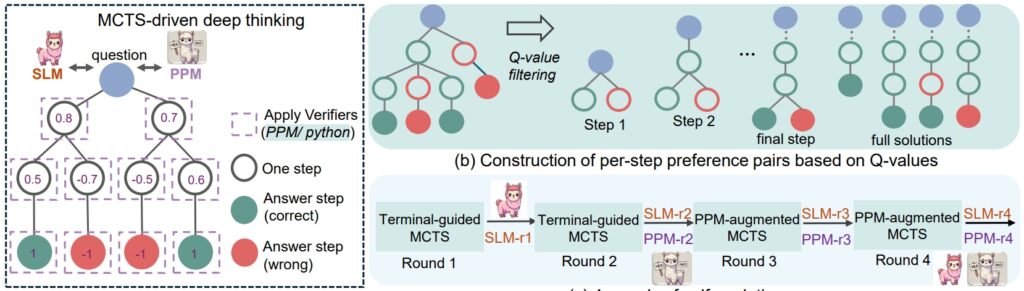 rSTar-Math-Argumentationsverfahren (Quelle: Forschungsarbeit)
rSTar-Math-Argumentationsverfahren (Quelle: Forschungsarbeit)
Leistung, die größere Modelle herausfordert
rStar-Math setzt neue Maßstäbe bei Benchmarks für mathematisches Denken und erzielt Ergebnisse, die konkurrieren mit denen größerer KI-Systeme und übertreffen sie in einigen Fällen.
Auf dem GSM8K-Datensatz Bei einem Test für mathematisches Denken verbesserte sich die Genauigkeit eines 7-Milliarden-Parameter-Modells von 12,51 % auf 63,91 % nach der Integration von rStar-Math href=”https://en.wikipedia.org/wiki/American_Invitational_Mathematics_Examination”>American Invitational Mathematics Examination (AIME) löste das Modell 53,3 % der Probleme und gehörte damit zu den besten 20 % der High-School-Teilnehmer.
Die Ergebnisse des MATH-Datensatzes waren gleichermaßen beeindruckend: rStar-Math erreichte eine Genauigkeitsrate von 90 % und übertraf damit die o1-Vorschau von OpenAI.
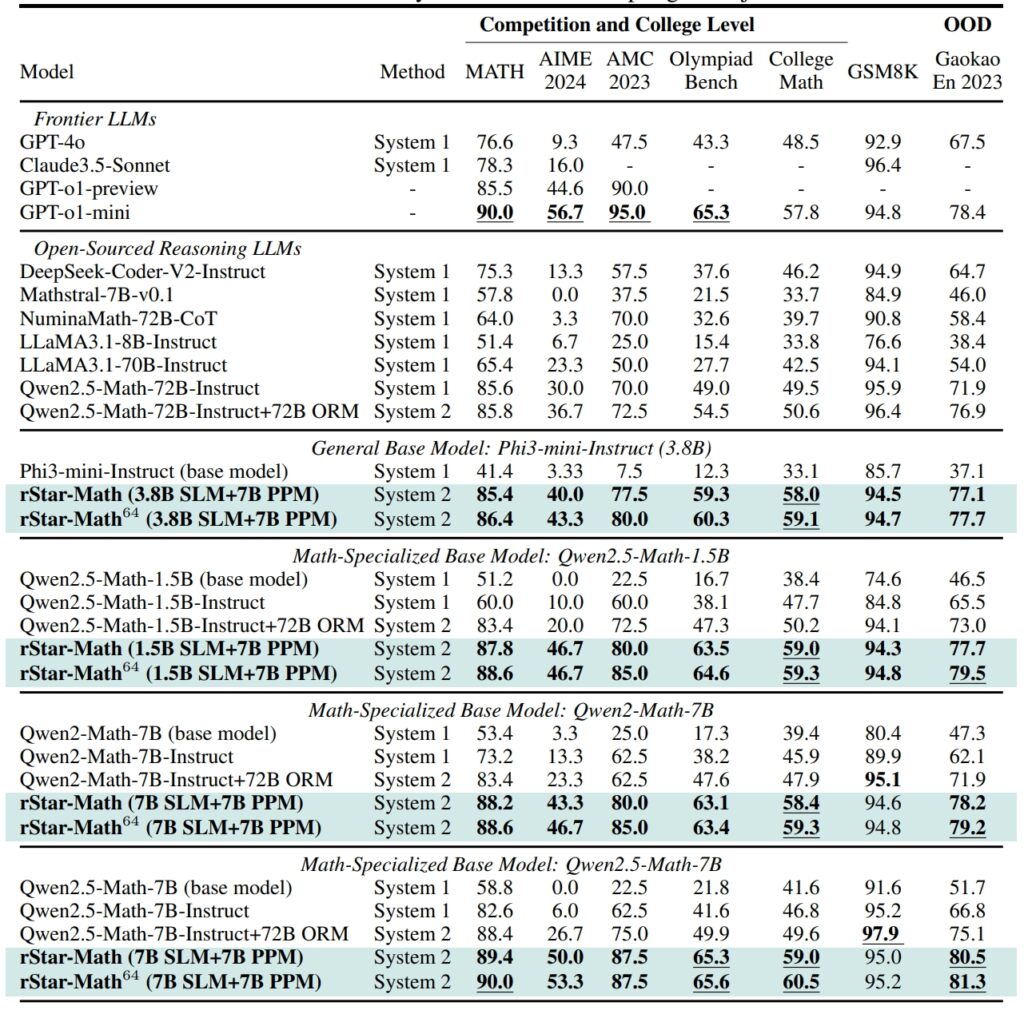 Leistung von rStar-Math und anderen Frontier-LLMs bei den anspruchsvollsten Mathe-Benchmarks (Quelle: Forschungsbericht)
Leistung von rStar-Math und anderen Frontier-LLMs bei den anspruchsvollsten Mathe-Benchmarks (Quelle: Forschungsbericht)
Diese Erfolge unterstreichen die Fähigkeit des Frameworks, SLMs in die Lage zu versetzen, Aufgaben zu bewältigen, die zuvor von ressourcenintensiven großen Modellen dominiert wurden. Durch die Betonung der logischen Konsistenz und überprüfbarer Zwischenschritte geht rStar-Math eine der hartnäckigsten Herausforderungen der KI an: die Gewährleistung zuverlässiger Argumentation über komplexe Problembereiche hinweg.
Technische Innovationen treiben rStar-Math voran
Die Entwicklung von rStar zu rStar-Math bringt mehrere wichtige Fortschritte mit sich. Die Integration von MCTS bleibt von zentraler Bedeutung für das Framework und ermöglicht es dem Modell, verschiedene Argumentationspfade zu erkunden und die vielversprechendsten zu priorisieren.
Die Hinzufügung von CoT-Argumentation mit Schwerpunkt auf der Codeüberprüfung stellt sicher, dass die Ausgaben sowohl interpretierbar als auch genau sind.
Verwandt: Alibabas QwQ-32B-Preview schließt sich mit OpenAI dem KI-Modell-Argumentation-Kampf an
Am transformativsten ist vielleicht der selbstevolutionäre Trainingsprozess von rStar-Math. In vier Iterationsrunden verfeinert das Framework sein Richtlinienmodell und sein PPM und bezieht bei jedem Schritt qualitativ hochwertigere Argumentationsdaten ein.
Dieser iterative Ansatz ermöglicht es dem Modell, seine Leistung kontinuierlich zu verbessern und Ergebnisse auf dem neuesten Stand der Technik zu erzielen, ohne auf die Destillation größerer Modelle angewiesen zu sein.
Vergleich von rStar-Math zu OpenAIs o1
Während sich Microsoft auf die Optimierung kleinerer Modelle konzentriert, legt OpenAI weiterhin Wert auf die Skalierung seiner Systeme.
Der o1 Pro-Modus wurde im Dezember 2024 als Teil des ChatGPT Pro-Plans eingeführt und bietet erweiterte Argumentationsfunktionen, die auf anspruchsvolle Anwendungen wie Codierung und wissenschaftliche Forschung zugeschnitten sind. OpenAI berichtete, dass der o1 Pro Mode eine Genauigkeitsrate von 86 % bei AIME und eine Erfolgsquote von 90 % bei Codierungs-Benchmarks wie Codeforces erreichte.
rStar-Math stellt einen Wandel in der KI-Innovation dar und stellt den Fokus der Branche auf größere Modelle in Frage als primäres Mittel zum Erreichen fortgeschrittener Argumentation. Durch die Erweiterung von SLMs mit domänenspezifischen Optimierungen bietet Microsoft eine nachhaltige Alternative, die Rechenkosten und Umweltbelastung reduziert.
Verwandt: Deliberative Ausrichtung: OpenAIs Sicherheitsstrategie für seine o1-und o3-Denkmodelle
Der Erfolg des Frameworks im mathematischen Denken öffnet Türen zu breiteren Anwendungen, von der Bildung zur wissenschaftlichen Forschung.
Die Forscher planen, den Code und die Daten von rStar-Math auf GitHub zu veröffentlichen und so den Weg für die weitere Zusammenarbeit und Entwicklung zu ebnen. Diese Transparenz spiegelt den Ansatz von Microsoft wider, leistungsstarke KI-Tools einem breiteren Publikum zugänglich zu machen, einschließlich akademischen Institutionen und mittelständischen Organisationen.
Verwandt: SemiAnalysis: Nein, AI Scaling Isn Keine Verlangsamung
Während der Wettbewerb zwischen Microsoft und OpenAI zunimmt, unterstreichen die von rStar-Math eingeführten Fortschritte das Potenzial kleinerer Modelle, die Dominanz größerer Systeme herauszufordern. Durch die Priorisierung von Effizienz und Genauigkeit setzt rStar-Math einen neuen Maßstab dafür, was kompakte KI-Systeme leisten können.