Das chinesische Labor für künstliche Intelligenz DeepSeek hat DeepSeek V3 vorgestellt, sein nächstes Gen-Open-Source-Sprachmodell. Das Modell verfügt über 671 Milliarden Parameter und nutzt eine sogenannte Mixture-of-Experts (MoE)-Architektur, um Recheneffizienz mit hoher Leistung zu kombinieren.
Die technischen Fortschritte von DeepSeek V3 machen es zu einem der leistungsstärksten KI-Systeme überhaupt Sowohl Open-Source-Konkurrenten wie Metas Llama 3.1 als auch proprietäre Modelle wie OpenAIs GPT-4o.
Die Veröffentlichung markiert einen wichtigen Moment in der KI und zeigt, dass Open-Source-Systeme konkurrieren können mit teureren, geschlossenen Alternativen – und in einigen Fällen sogar besser als diese.
Verwandt:
Das chinesische DeepSeek R1-Lite-Preview-Modell zielt auf den Vorsprung von OpenAI ab Automatisiertes Denken
Alibaba Qwen veröffentlicht QVQ-72B-Preview Multimodal Reasoning AI Model
Effiziente und innovative Architektur
Die Architektur von DeepSeek V3 kombiniert zwei fortschrittliche Konzepte Erreichen Sie außergewöhnliche Effizienz und Leistung: Multi-Head Latent Attention (MLA) und Mixture-of-Experts (MoE).
MLA verbessert die Fähigkeit des Modells, komplexe Prozesse zu verarbeiten Eingaben durch den Einsatz mehrerer Aufmerksamkeitsköpfe, um sich auf verschiedene Aspekte der Daten zu konzentrieren und umfangreiche und vielfältige Kontextinformationen zu extrahieren.
MoE hingegen aktiviert nur eine Teilmenge der insgesamt 671 Milliarden Parameter des Modells – etwa 37 Milliarden pro Aufgabe – wodurch sichergestellt wird, dass Rechenressourcen effektiv genutzt werden, ohne dass die Genauigkeit beeinträchtigt wird. Zusammen ermöglichen diese Mechanismen DeepSeek V3, qualitativ hochwertige Ergebnisse zu liefern und gleichzeitig den Infrastrukturbedarf zu reduzieren.
Um häufige Herausforderungen in MoE-Systemen, wie z. B. die ungleichmäßige Arbeitslastverteilung unter Experten, zu bewältigen, führte DeepSeek eine zusätzliche, verlustfreie Last ein. Ausgleichsstrategie. Diese dynamische Methode verteilt Aufgaben im gesamten Expertennetzwerk, sorgt für Konsistenz und maximiert die Aufgabengenauigkeit.
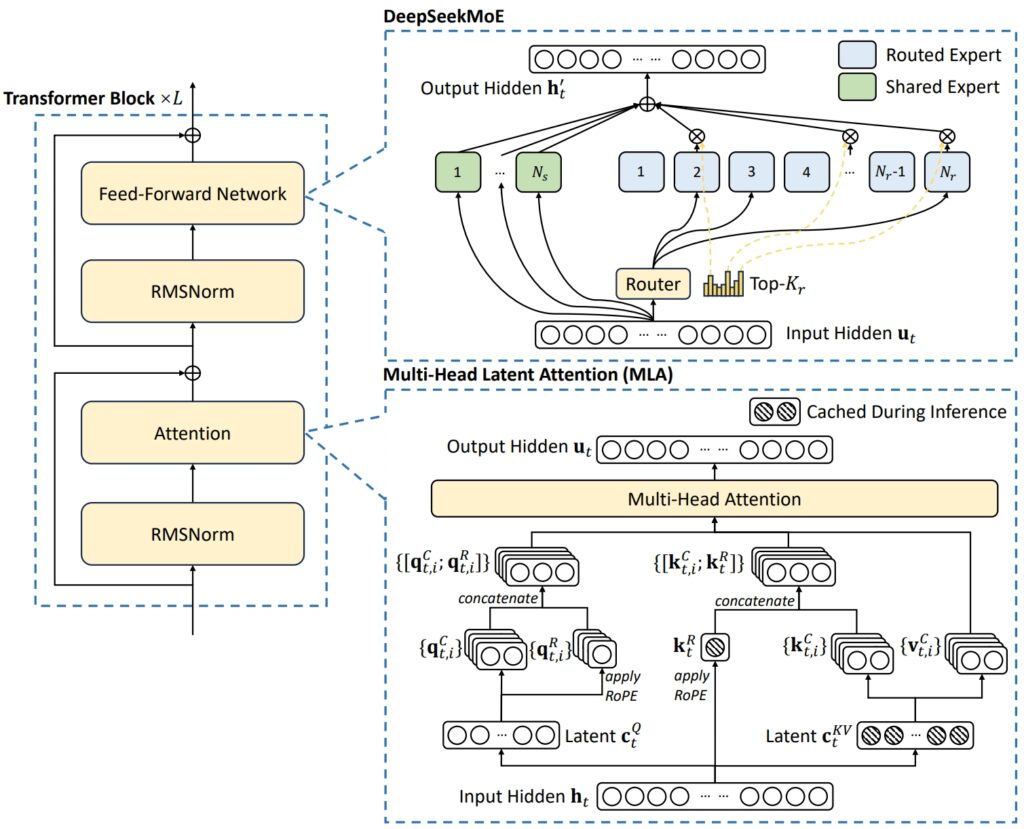 Darstellung der Grundarchitektur von DeepSeek-V3 (Bild: DeepSeek)
Darstellung der Grundarchitektur von DeepSeek-V3 (Bild: DeepSeek)
Um die Effizienz weiter zu steigern, verwendet DeepSeek V3 Multi-Token Vorhersage (MTP), eine Funktion, die es dem Modell ermöglicht, mehrere Token gleichzeitig zu generieren und so die Textgenerierung erheblich zu beschleunigen.
Diese Funktion verbessert nicht nur die Trainingseffizienz, sondern positioniert das Modell auch für schnellere Anwendungen in der realen Welt und stärkt so seine Effizienz gilt als führend im Bereich Open-Source-KI-Innovation.
Benchmark-Leistung: Ein Marktführer in Mathematik und Codierung
Die Benchmark-Ergebnisse von DeepSeek V3 zeigen seine außergewöhnlichen Fähigkeiten auf ganzer Linie A breites Aufgabenspektrum und festigt seine Position als Marktführer unter den Open-Source-KI-Modellen.
Durch die Nutzung seiner fortschrittlichen Architektur und seines umfangreichen Trainingsdatensatzes hat das Modell Spitzenleistungen in Mathematik, Codierung und mehrsprachigen Benchmarks erzielt und gleichzeitig wettbewerbsfähige Ergebnisse in Bereichen präsentiert, die traditionell von Closed-Source-Modellen wie dem GPT von OpenAI dominiert werden-4o und Anthropics Claude 3.5 Sonnet.
🚀 Wir stellen DeepSeek-V3 vor!
Größter Sprung nach vorne bisher:
⚡ 60 Token/Sekunde (3x schneller als V2!)
💪 Erweiterte Funktionen
🛠 API-Kompatibilität intakt
🌍 Vollständig Open-Source-Modelle und-Papiere🐋 1/n pic.twitter.com/p1dV9gJ2Sd
– DeepSeek (@deepseek_ai) Dezember 26, 2024
Mathematisches Denken
Über das Im Math-500-Test, einem Benchmark zur Bewertung mathematischer Problemlösungsfähigkeiten, erreichte DeepSeek V3 eine beeindruckende Punktzahl von 90,2. Mit dieser Punktzahl liegt es vor allen Open-Source-Konkurrenten: Qwen 2.5 erzielte 80 Punkte und Llama 3.1 lag mit 73,8 Punkten zurück. Sogar GPT-4o, ein Closed-Source-Modell, das für seine allgemeinen Fähigkeiten bekannt ist, schnitt mit 74,6 etwas schlechter ab. Diese Leistung unterstreicht die fortgeschrittenen Denkfähigkeiten von DeepSeek V3, insbesondere bei rechenintensiven Aufgaben, bei denen Präzision und Logik von entscheidender Bedeutung sind.
Darüber hinaus schnitt DeepSeek V3 in anderen mathematikspezifischen Tests hervor, wie zum Beispiel:
MGSM (Math Grade School Math): Bewertet 79,8 und übertrifft damit Llama 3,1 (69,9) und Qwen 2,5 (76,2). CMath (Chinesische Mathematik): Erreichte 90,7 und übertraf damit sowohl Llama 3,1 (77,3) als auch GPT-4o (84,5).
Diese Ergebnisse unterstreichen nicht nur seine Stärke im englischsprachigen mathematischen Denken, aber auch in Aufgaben, die eine sprachspezifische numerische Problemlösung erfordern.
Verwandt: DeepSeek AI Open Sources VL2 Series of Vision Language Models
Programmierung und Codierung
DeepSeek V3 zeigte bemerkenswerte Ergebnisse Kompetenz in Codierung und Problemlösungs-Benchmarks. Auf Codeforces, einer wettbewerbsfähigen Programmierplattform, erreichte das Modell ein 51,6-Perzentil-Ranking, was seine Fähigkeit widerspiegelt, komplexe algorithmische Aufgaben zu bewältigen. Diese Leistung übertrifft Open-Source-Konkurrenten wie Llama 3.1, das nur 25,3 erreichte, deutlich und fordert sogar Claude 3.5 Sonnet heraus, das ein niedrigeres Perzentil verzeichnete. Der Erfolg des Modells wurde durch seine hohen Ergebnisse in codierungsspezifischen Benchmarks weiter bestätigt:
HumanEval-Mul: Erzielte einen Wert von 82,6, übertraf damit Qwen 2,5 (77,3) und erreichte GPT-4o (80,5). LiveCodeBench (Pass@1): Erzielte 37,6, vor Llama 3,1 (30,1) und Claude 3,5 Sonnet (32,8). CRUXEval-I: Erzielte 67,3, deutlich besser als Qwen 2,5 (59,1) und Llama 3,1 (58,5).
Diese Ergebnisse unterstreichen die Eignung des Modells für Anwendungen in der Softwareentwicklung und in realen Codierungsumgebungen, in denen effiziente Problemlösung und Codegenerierung von größter Bedeutung sind.
Mehrsprachige und nicht-englische Aufgaben
DeepSeek V3 sticht auch in mehrsprachigen Benchmarks hervor und zeigt seine Fähigkeit, ein breites Spektrum an Sprachen zu verarbeiten und zu verstehen. Beim CMMLU-Test (Chinese Multilingual Language Understanding) erreichte das Modell eine außergewöhnliche Punktzahl von 88,8 und übertraf damit Qwen 2,5 (89,5) und dominierte Lama 3,1, das mit 73,7 zurückblieb. Auch beim C-Eval, einem chinesischen Bewertungsbenchmark, erzielte DeepSeek V3 einen Wert von 90,1, deutlich vor Llama 3.1 (72,5).
Bei nicht-englischsprachigen mehrsprachigen Aufgaben:
Englischspezifische Benchmarks
Während DeepSeek V3 in Mathematik, Codierung und anderen Bereichen glänzt Trotz der mehrsprachigen Leistung weisen die Ergebnisse in bestimmten englischspezifischen Benchmarks auf Verbesserungspotenzial hin. Beispielsweise erzielte DeepSeek V3 beim SimpleQA-Benchmark, der die Fähigkeit eines Modells bewertet, einfache Sachfragen auf Englisch zu beantworten, 24,9 Punkte und fällt hinter GPT-4o zurück, das 38,2 erreichte. In ähnlicher Weise erzielte GPT-4o bei FRAMES, einem Benchmark für das Verständnis komplexer Erzählstrukturen, einen Wert von 80,5, verglichen mit 73,3 von DeepSeek.
Trotz dieser Lücken bleibt die Leistung des Modells äußerst wettbewerbsfähig, insbesondere angesichts seines Open-Source-Charakters und seiner Kosteneffizienz. Die leichte Unterleistung bei englischspezifischen Aufgaben wird durch seine Dominanz in Mathematik und mehrsprachigen Benchmarks ausgeglichen, Bereiche, in denen es Closed-Source-Konkurrenten ständig herausfordert und oft übertrifft.
Die Benchmark-Ergebnisse von DeepSeek V3 zeigen nicht nur seine technische Raffinesse, sondern auch Positionieren Sie es außerdem als vielseitiges, leistungsstarkes Modell für ein breites Aufgabenspektrum. Seine Überlegenheit in Mathematik, Codierung und mehrsprachigen Benchmarks unterstreicht seine Stärken, während seine wettbewerbsfähigen Ergebnisse bei englischen Aufgaben zeigen, dass es mit Branchenführern wie GPT-4o und Claude 3.5 Sonnet mithalten kann.
Indem DeepSeek V3 diese Ergebnisse zu einem Bruchteil der Kosten liefert, die mit proprietären Systemen verbunden sind, verdeutlicht es das Potenzial von Open-Source-KI, mit Closed-Source-Alternativen mithalten und diese in einigen Fällen sogar übertreffen zu können.
Verwandt: Apple plant KI-Einführung in China durch Tencent und ByteDance
Kostengünstiges Training in großem Maßstab
One des Herausragenden Der größte Vorteil von DeepSeek V3 ist sein kosteneffizienter Trainingsprozess. Das Modell wurde anhand eines Datensatzes von 14,8 Billionen Token mit Nvidia H800-GPUs trainiert, mit einer Gesamttrainingszeit von 2,788 Millionen GPU-Stunden. Die Gesamtkosten beliefen sich auf 5,576 Millionen US-Dollar, ein Bruchteil der geschätzten 500 Millionen US-Dollar, die für das Training von Metas Llama 3.1 erforderlich waren.
Die NVIDIA H800-GPU ist eine modifizierte Version der H100-GPU, die für den chinesischen Markt entwickelt wurde, um dem Export zu entsprechen Vorschriften. Beide GPUs basieren auf der Hopper-Architektur von NVIDIA und werden vor allem für KI-und High-Performance-Computing-Anwendungen eingesetzt. Die Chip-zu-Chip-Datenübertragungsrate des H800 ist auf etwa die Hälfte der des H100 reduziert.
Der Trainingsprozess nutzte fortschrittliche Methoden, einschließlich FP8-Mixed-Precision-Training. Dieser Ansatz reduziert die Speichernutzung, indem Daten in einem 8-Bit-Gleitkommaformat codiert werden, ohne dass die Genauigkeit darunter leidet. Darüber hinaus optimierte der DualPipe-Algorithmus die Pipeline-Parallelität und sorgte so für eine reibungslose Koordination zwischen GPU-Clustern.
DeepSeek sagt, dass das Vortraining von DeepSeek-V3 nur 180.000 H800-GPU-Stunden pro Billion Token erforderte, wobei ein Cluster von 2.048 GPUs verwendet wurde.
Zugänglichkeit und Bereitstellung
DeepSeek hat V3 unter einer MIT-Lizenz zur Verfügung gestellt und bietet Entwicklern damit Zugriff auf das Modell sowohl für Forschungs-als auch für kommerzielle Anwendungen. Unternehmen können das Modell über die DeepSeek Chat-Plattform oder API integrieren, deren Preis bei 0,27 US-Dollar pro Million Eingabetokens und 1,10 US-Dollar pro Million Ausgabetokens liegt.
Die Vielseitigkeit des Modells erstreckt sich auch auf die Kompatibilität mit verschiedenen Hardwareplattformen, darunter AMD-GPUs und Huawei Ascend NPUs. Dies gewährleistet eine breite Zugänglichkeit für Forscher und Organisationen mit unterschiedlichen Infrastrukturanforderungen.
DeepSeek betonte seinen Fokus auf Zuverlässigkeit und Leistung und erklärte: „Um SLO-Konformität und hohen Durchsatz sicherzustellen, wenden wir eine dynamische Redundanzstrategie für Experten während der Vorbefüllungsphase an, bei der Experten mit hoher Auslastung regelmäßig dupliziert und neu angeordnet werden.“ für optimale Leistung.“
Umfassendere Auswirkungen auf das KI-Ökosystem
Die Veröffentlichung von DeepSeek V3 unterstreicht einen breiteren Trend in Richtung Durch die Bereitstellung eines Hochleistungsmodells zu einem Bruchteil der mit proprietären Systemen verbundenen Kosten stellt DeepSeek die Dominanz von Closed-Source-Anbietern wie OpenAI und Anthropic in Frage. Die Verfügbarkeit solch fortschrittlicher Tools ermöglicht umfassendere Experimente und Innovationen Industrien.
Die Pipeline von DeepSeek integriert Verifizierungs-und Reflexionsmuster aus seinem R1-Modell in DeepSeek-V3 und verbessert so die Argumentationsfähigkeiten, während gleichzeitig die Kontrolle über den Ausgabestil und die Länge erhalten bleibt.
Die Der Erfolg von DeepSeek V3 wirft Fragen über das zukünftige Kräfteverhältnis in der KI-Branche auf. Da Open-Source-Modelle weiterhin die Lücke zu proprietären Systemen schließen, bieten sie Unternehmen wettbewerbsfähige Alternativen, bei denen Zugänglichkeit und Kosteneffizienz im Vordergrund stehen.