Forscher von Sakana AI, einem in Tokio ansässigen KI-Startup, haben ein neuartiges Speicheroptimierungssystem eingeführt, das die Effizienz von Transformer-basierten Modellen, einschließlich großer Sprachmodelle (LLMs), steigert.
Die Methode genannt Neural Attention Memory Models (NAMMs) ist über den vollständigen Trainingscode auf GitHub reduziert die Speichernutzung um bis zu 75 % und verbessert gleichzeitig die Gesamtleistung. Durch die Konzentration auf wesentliche Token und die Entfernung redundanter Informationen bewältigen NAMMs eine der ressourcenintensivsten Herausforderungen der modernen KI: die Verwaltung langer Kontextfenster.
Transformer-Modelle, das Rückgrat von LLMs, basieren auf „Kontextfenster“. um Eingabedaten zu verarbeiten. Diese Kontextfenster speichern „Schlüssel-Wert-Paare“ (KV-Cache) für jedes Token in der Eingabesequenz.
Mit zunehmender Fensterlänge – die nun Hunderttausende von Token erreicht – wird die Der Rechenaufwand steigt sprunghaft an. Frühere Lösungen versuchten, diese Kosten durch manuelles Token-Pruning oder heuristische Strategien zu reduzieren, führten jedoch häufig zu Leistungseinbußen. NAMMs nutzen jedoch neuronale Netze, die durch evolutionäre Optimierung trainiert wurden, um den Speicherverwaltungsprozess zu automatisieren und zu verfeinern.
Speicheroptimierung mit NAMMs
NAMMs analysieren die Aufmerksamkeitswerte Wird von Transformers generiert, um die Wichtigkeit des Tokens zu bestimmen. Sie verarbeiten diese Werte zu Spektrogrammen – frequenzbasierten Darstellungen, die häufig in der Audio-und Signalverarbeitung verwendet werden –, um Schlüsselmerkmale der Aufmerksamkeitsmuster zu komprimieren und zu extrahieren.
Diese Informationen werden dann durch ein leichtes neuronales Netzwerk geleitet, das jedem Token eine Punktzahl zuordnet und entscheidet, ob es beibehalten oder verworfen werden soll.
Sakana AI zeigt, wie evolutionäre Algorithmen die Leistung von NAMMs vorantreiben. Erfolg. Im Gegensatz zu herkömmlichen, auf Gradienten basierenden Methoden, die mit binären Entscheidungen wie „merken“ oder „vergessen“ nicht kompatibel sind, testet und verfeinert die evolutionäre Optimierung Speicherstrategien iterativ, um die nachgelagerte Leistung zu maximieren.
„Evolution überwindet von Natur aus die Nichtdifferenzierbarkeit.“ unserer Speicherverwaltungsvorgänge, die binäre „Erinnern“-oder „Vergessen“-Ergebnisse beinhalten“, erklären die Forscher.
Nachgewiesene Ergebnisse über Benchmarks hinweg
Zur Validierung Um die Leistung und Effizienz von Neural Attention Memory Models (NAMMs) zu verbessern, führte Sakana AI umfangreiche Tests mit mehreren branchenführenden Benchmarks durch, um die Langkontextverarbeitung und Multitasking-Fähigkeiten zu bewerten. Die Ergebnisse unterstrichen die Fähigkeit von NAMMs, die Leistung bei gleichzeitiger Speicherreduzierung deutlich zu verbessern Anforderungen und beweisen ihre Wirksamkeit in verschiedenen Bewertungsrahmen.
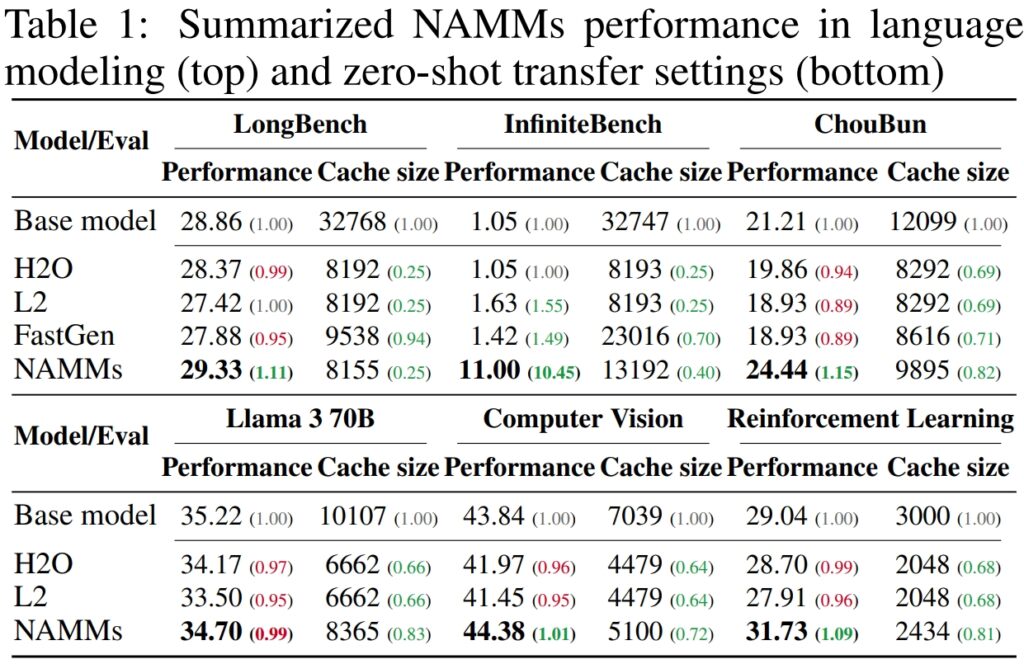
Auf LongBench, einem Benchmark, der speziell zur Messung der Leistung von Modellen erstellt wurde Bei Aufgaben mit langem Kontext erzielten NAMMs eine Verbesserung der Genauigkeit um 11 % im Vergleich zum Vollkontext-Basismodell. Diese Verbesserung wurde bei gleichzeitiger Reduzierung der Speichernutzung um 75 % erreicht, was die Effizienz der Methode bei der Verwaltung des Schlüsselwert-Cache (KV) unterstreicht.
Durch die intelligente Beschneidung weniger relevanter Token ermöglichten NAMMs dem Modell, sich auf den kritischen Kontext zu konzentrieren, ohne dass die Ergebnisse darunter litten. Dies machte es ideal für Szenarien, die erweiterte Eingaben erfordern, wie z. B. die Analyse von Dokumenten oder die Beantwortung langer Fragen.
Für InfiniteBench, ein Benchmark, der Modelle an ihre Grenzen bringt Mit extrem langen Sequenzen – einige übersteigen 200.000 Token – haben NAMMs ihre Fähigkeit zur effektiven Skalierung unter Beweis gestellt.
Während Basismodelle mit den Rechenanforderungen solch langer Eingaben zu kämpfen hatten, erzielten NAMMs eine dramatische Leistungssteigerung und erhöhten die Genauigkeit von 1,05 % auf 11,00 %.
Dieses Ergebnis ist besonders bemerkenswert, weil es die Fähigkeit von NAMMs zeigt, extrem lange Kontexte zu verarbeiten, eine Fähigkeit, die für Anwendungen wie die Verarbeitung wissenschaftlicher Literatur, juristischer Dokumente oder großer Code-Repositories, bei denen die Token-Eingabegrößen immens sind, immer wichtiger wird.
Auf Sakana AIs eigenem ChouBun-Benchmark, der das Denken über lange Kontexte für japanischsprachige Aufgaben bewertet, NAMMs lieferten eine Verbesserung um 15 % gegenüber dem Ausgangswert. ChouBun schließt eine Lücke in bestehenden Benchmarks, die sich tendenziell auf Englisch und Chinesisch konzentrieren, indem es Modelle für erweiterte japanische Texteingaben testet.
Der Erfolg von NAMMs auf ChouBun unterstreicht ihre sprachübergreifende Vielseitigkeit und beweist ihre Robustheit im Umgang mit nicht-englischen Eingaben – ein Schlüsselmerkmal für globale KI-Anwendungen. NAMMs waren in der Lage, kontextspezifische Inhalte effizient beizubehalten und gleichzeitig grammatikalische Redundanzen und weniger aussagekräftige Token zu verwerfen, wodurch das Modell Aufgaben wie lange Zusammenfassungen und Verständnis auf Japanisch effektiver bewältigen konnte.
 Quelle: Sakana AI
Quelle: Sakana AI
The Die Ergebnisse zeigen insgesamt, dass NAMMs die Speichernutzung hervorragend optimieren, ohne die Genauigkeit zu beeinträchtigen. Unabhängig davon, ob sie an Aufgaben evaluiert werden, die extrem lange Sequenzen erfordern, oder in nicht-englischsprachigen Kontexten, übertreffen NAMMs stets die Basismodelle und erzielen sowohl Recheneffizienz als auch verbesserte Ergebnisse.
Diese Kombination aus Speichereinsparungen und Genauigkeitsgewinnen macht NAMMs zu einem großen Fortschritt für KI-Systeme in Unternehmen, die große und komplexe Eingaben verarbeiten müssen.
Die Ergebnisse sind besonders bemerkenswert im Vergleich zu früheren Methoden wie H₂O und L2, bei dem Leistung zugunsten der Effizienz geopfert wurde. NAMMs hingegen erreichen beides.
„Unsere Ergebnisse zeigen, dass NAMMs im Vergleich zu Basistransformatoren erfolgreich konsistente Verbesserungen sowohl auf der Leistungs-als auch auf der Effizienzebene liefern“, erklären die Forscher.
Cross-Modal Applications: Beyond Language
Eine der beeindruckendsten Erkenntnisse war die Fähigkeit von NAMMs, Zero-Shot auf andere Aufgaben und Eingabemodalitäten zu übertragen
Einer der meisten Bemerkenswerte Aspekte neuronaler Aufmerksamkeitsgedächtnismodelle (NAMMs) sind ihre Fähigkeit, sich nahtlos über verschiedene Aufgaben und Eingabemodalitäten hinweg zu übertragen – über herkömmliche sprachbasierte Anwendungen hinaus.
Im Gegensatz zu anderen Methoden zur Gedächtnisoptimierung, die häufig eine Umschulung oder Feinabstimmung erfordern. Durch die Optimierung für jeden Bereich behalten NAMMs ihre Effizienz-und Leistungsvorteile ohne zusätzliche Anpassungen bei. Die Experimente von Sakana AI haben diese Vielseitigkeit in zwei Schlüsselbereichen gezeigt: Computer Vision und Reinforcement Learning, die beide einzigartige Herausforderungen für Transformer-basierte Systeme darstellen Modelle.
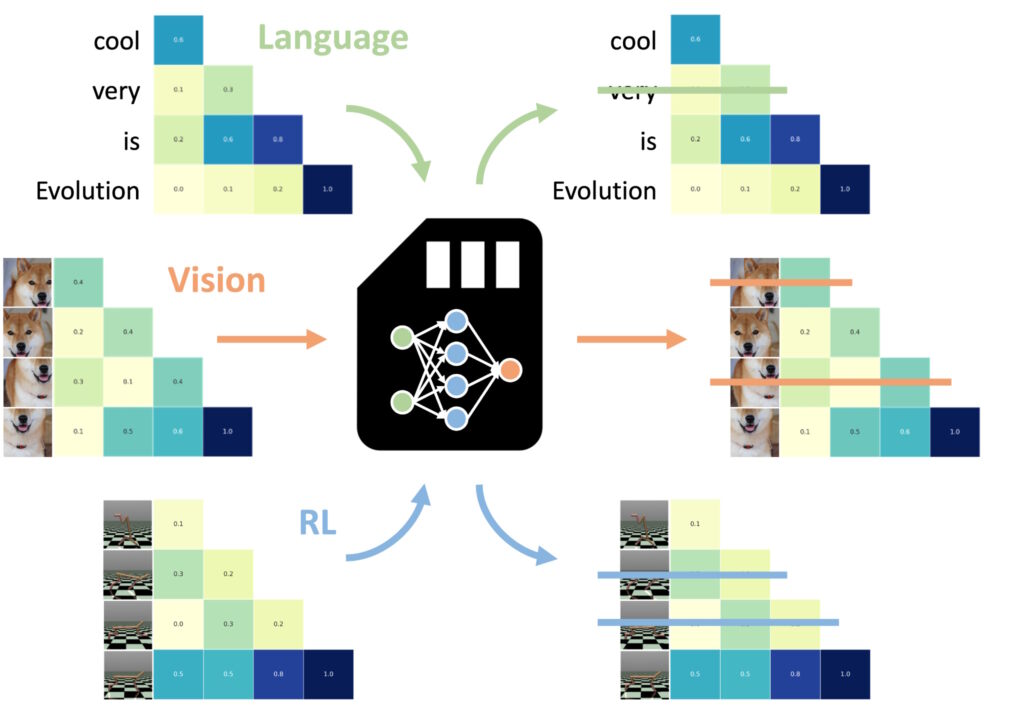 Auf Sprache trainierte NAMMs können null-Der Schuss wird über Eingabemodalitäten und Aufgabendomänen hinweg an andere Transformatoren übertragen. (Bild: Sakana AI)
Auf Sprache trainierte NAMMs können null-Der Schuss wird über Eingabemodalitäten und Aufgabendomänen hinweg an andere Transformatoren übertragen. (Bild: Sakana AI)
In der Computer Vision wurden NAMMs mithilfe des Llava Next Video-Modells bewertet, a Transformator für die Verarbeitung langer Videosequenzen. Videos enthalten von Natur aus große Mengen redundanter Daten, wie z. B. wiederholte Bilder oder geringfügige Abweichungen, die kaum zusätzliche Informationen liefern.
NAMMs identifizierten und verwarfen diese redundanten Frames während der Inferenz automatisch und komprimierten so effektiv das Kontextfenster, ohne die Fähigkeit des Modells zur Interpretation des Videoinhalts zu beeinträchtigen.
Zum Beispiel behielten NAMMs Frames mit wichtigen visuellen Details – wie Aktionsänderungen, Objektinteraktionen oder kritischen Ereignissen – bei, während sich wiederholende oder statische Frames entfernt wurden. Dies führte zu einer verbesserten Verarbeitungseffizienz und ermöglichte es dem Modell, sich auf die relevantesten visuellen Elemente zu konzentrieren, wodurch die Genauigkeit erhalten blieb und gleichzeitig die Rechenkosten gesenkt wurden.
Beim Reinforcement Learning wurden NAMMs auf die angewendet Decision Transformer, ein Modell zur Verarbeitung von Abfolgen von Aktionen, Beobachtungen und Belohnungen zur Optimierung Entscheidungsaufgaben. Verstärkungslernaufgaben umfassen häufig lange Eingabesequenzen mit unterschiedlichem Relevanzniveau, bei denen suboptimale oder redundante Aktionen die Leistung beeinträchtigen können.
NAMMs begegneten dieser Herausforderung, indem sie selektiv Token entfernten, die ineffizienten Aktionen und minderwertigen Informationen entsprachen, während diejenigen beibehalten wurden, die für die Erzielung besserer Ergebnisse von entscheidender Bedeutung sind.
Zum Beispiel bei Aufgaben wie Hopper und Walker2d – bei dem virtuelle Agenten in kontinuierlicher Bewegung gesteuert werden – NAMMs verbesserten die Leistung um über 9 %. Durch das Herausfiltern suboptimaler Bewegungen oder unnötiger Details erzielte der Decision Transformer ein effizienteres und effektiveres Lernen und konzentrierte seine Rechenleistung auf Entscheidungen, die den Erfolg der Aufgabe maximierten.
Diese Ergebnisse unterstreichen die Anpassungsfähigkeit von NAMMs über sehr unterschiedliche Bereiche hinweg. Ob bei der Verarbeitung von Videobildern in Vision-Modellen oder der Optimierung von Aktionssequenzen beim Reinforcement Learning – NAMMs haben ihre Fähigkeit unter Beweis gestellt, die Leistung zu steigern, den Ressourcenverbrauch zu reduzieren und die Modellgenauigkeit aufrechtzuerhalten – und das alles ohne Umschulung.
NAMMs lernen, fast ausschließlich Teile zu vergessen von redundanten Videobildern anstelle von Sprachtokens, die die endgültige Eingabeaufforderung beschreiben, heißt es in dem Papier, was die Anpassungsfähigkeit von NAMMs hervorhebt.
Technische Grundlagen von NAMMs
Die Effizienz und Effektivität von Neural Attention Memory Models (NAMMs) liegt in ihrem optimierten und systematischen Ausführungsprozess, der eine präzise Token-Bereinigung ohne manuelle Eingriffe ermöglicht. Dieser Prozess basiert auf drei Kernkomponenten: Aufmerksamkeitsspektrogramme, Merkmalskomprimierung und automatische Bewertung.
NAMMs passen ihr Verhalten dynamisch an die Aufgabenanforderungen und die Tiefe der Transformer-Ebene an. Frühe Schichten priorisieren „globale“ Kontexte wie Aufgabenbeschreibungen, während tiefere Schichten „lokale“ aufgabenspezifische Details beibehalten. Bei Codierungsaufgaben verwarfen NAMMs beispielsweise Kommentare und Boilerplate-Code; Bei Aufgaben in natürlicher Sprache beseitigten sie grammatikalische Redundanzen und behielten gleichzeitig wichtige Inhalte bei.
Diese adaptive Token-Aufbewahrung stellt sicher, dass sich die Modelle während der gesamten Verarbeitung auf relevante Informationen konzentrieren, wodurch Geschwindigkeit und Genauigkeit verbessert werden.
Das erste Schritt beinhaltet die Erstellung von Aufmerksamkeitsspektrogrammen. Transformatoren berechnen „Aufmerksamkeitswerte“ auf jeder Ebene, um die relative Bedeutung jedes Tokens innerhalb des Kontextfensters zu bestimmen. NAMMs wandeln diese Aufmerksamkeitswerte in um Frequenzbasierte Darstellungen unter Verwendung der Short-Time-Fourier-Transformation (STFT)
STFT ist eine weit verbreitete Signalverarbeitungstechnik, die eine Sequenz über die Zeit in lokalisierte Frequenzkomponenten zerlegt und so eine kompakte und dennoch detaillierte Darstellung der Token-Bedeutung liefert. Durch die Anwendung von STFT wandeln NAMMs rohe Aufmerksamkeitssequenzen in spektrogrammartige Daten um und ermöglichen so eine Eine klarere Analyse, welche Token einen sinnvollen Beitrag zur Modellausgabe leisten.
Als nächstes wird die Merkmalskomprimierung angewendet, um die Dimensionalität der Spektrogrammdaten zu reduzieren und gleichzeitig ihre wesentlichen Eigenschaften beizubehalten wird mithilfe eines exponentiellen gleitenden Durchschnitts (EMA) erreicht, einer mathematischen Methode, die historische Aufmerksamkeitsmuster in einer kompakten Zusammenfassung fester Größe komprimiert. EMA stellt sicher, dass die Darstellungen leichtgewichtig und handhabbar bleiben, sodass NAMMs lange Aufmerksamkeitssequenzen effizient analysieren und gleichzeitig den Rechenaufwand minimieren können.
Der letzte Schritt ist Scoring and Pruning, wobei NAMMs eine leichte Darstellung verwenden Klassifikator für neuronale Netze, um die komprimierten Token-Darstellungen auszuwerten und basierend auf ihrer Wichtigkeit Punkte zuzuweisen. Token mit Werten unter einem definierten Schwellenwert werden aus dem Kontextfenster entfernt, wodurch nicht hilfreiche oder redundante Details effektiv „vergessen“ werden. Dieser Bewertungsmechanismus ermöglicht es NAMMs, kritische Token zu priorisieren, die zum Entscheidungsprozess des Modells beitragen, und gleichzeitig weniger relevante Daten zu verwerfen.
Was NAMMs besonders effektiv macht, ist ihre Abhängigkeit von der evolutionären Optimierung zur Verfeinerung dieses Prozesses. Traditionelle Optimierungsmethoden wie der Gradientenabstieg kämpfen mit nicht differenzierbaren Aufgaben – wie etwa der Entscheidungsfindung ob ein Token behalten oder verworfen werden soll.
Stattdessen verwenden NAMMs einen iterativen evolutionären Algorithmus, der von der natürlichen Selektion inspiriert ist, um im Laufe der Zeit die effizientesten Speicherverwaltungsstrategien zu „mutieren“. , entwickelt sich das System weiter, um wichtige Token automatisch zu priorisieren und so ein Gleichgewicht zwischen Leistung und Speichereffizienz zu erreichen, ohne dass eine manuelle Feinabstimmung erforderlich ist.
Diese optimierte Ausführung – Kombination von spektrogrammbasierter Token-Analyse, effizienter Komprimierung, und automatisiertes Bereinigen – ermöglicht NAMMs sowohl erhebliche Speichereinsparungen als auch Leistungssteigerungen bei verschiedenen Transformer-basierten Aufgaben. Durch die Reduzierung des Rechenaufwands bei gleichzeitiger Beibehaltung oder Verbesserung der Genauigkeit setzen NAMMs einen neuen Maßstab für effiziente Speicherverwaltung in modernen KI-Modellen.
Was kommt als nächstes für Transformers?
Sakana AI glaubt, dass NAMMs nur der Anfang sind. Während sich die aktuelle Arbeit auf die Optimierung vorab trainierter Modelle bei der Inferenz konzentriert, könnten zukünftige Forschungen NAMMs in den Trainingsprozess selbst integrieren. Dies könnte es Modellen ermöglichen, Speicherverwaltungsstrategien nativ zu erlernen, was die Länge von Kontextfenstern weiter verlängert und die Effizienz über Domänen hinweg steigert.
„Diese Arbeit hat gerade erst begonnen, den Designraum unserer Speichermodelle zu erkunden, was wir erwarten.“ könnte viele neue Möglichkeiten bieten, zukünftige Generationen von Transformatoren voranzutreiben“, schlussfolgert das Team.
Die nachgewiesene Fähigkeit von NAMMs, die Leistung zu skalieren, Kosten zu senken und sich modalitätsübergreifend anzupassen, setzt einen neuen Standard für die Effizienz von Großtransformatoren KI-Modelle.