OpenAI hat Reinforcement Fine-Tuning (RFT) vorgestellt, ein neues Framework, das die Anpassung von KI-Modellen für branchenspezifische Anwendungen ermöglichen soll. RFT wurde während der OpenAI-Veranstaltung „12 Days of OpenAI“ vorgestellt und ermöglicht Entwicklern die Verbesserung der KI-Folgefähigkeiten mit domänenspezifischen Datensätzen und Bewertungsrubriken.
Die neue Funktion richtet sich an Unternehmen und Forscher und steht im Einklang mit den umfassenderen Bemühungen von OpenAI um die Lücke zwischen allgemeinen KI-Modellen und speziellen Branchenanforderungen zu schließen.
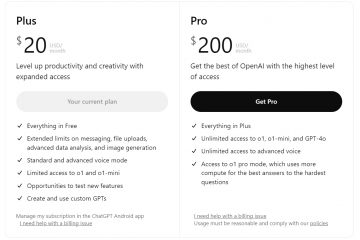
Begleitend mit RFT wird der ChatGPT Pro Plan ab dem ersten Tag von „12 Days of“ eingeführt OpenAI“, ein 200-Dollar-Monat-Abonnement für Profis, beinhaltet den o1 Pro-Modus, der als die bisher zuverlässigste Argumentations-KI von OpenAI gilt. Erste Bewertungen des o1 Pro-Modus zeigen jedoch sowohl sein Potenzial als auch seine Grenzen und verdeutlichen die anhaltenden Herausforderungen bei der Weiterentwicklung fortschrittlicher KI-Systeme für den praktischen Einsatz.

Was ist Reinforcement Fine-Tuning?
Reinforcement Fine-Tuning ist der neueste Ansatz von OpenAI zur Verbesserung von KI-Modellen durch Training mit vom Entwickler bereitgestellten Datensätzen und Bewertungssystemen. Im Gegensatz zum herkömmlichen überwachten Lernen, das sich auf die Replikation gewünschter Ergebnisse konzentriert, legt RFT Wert auf Argumentation und Problemlösung, die auf bestimmte Bereiche zugeschnitten sind.
In seiner Ankündigung OpenAI beschrieb RRFT als ein Tool, das es Organisationen ermöglicht, Expertenmodelle zu trainieren, ohne dass tiefe Kenntnisse über Reinforcement Learning erforderlich sind.
[eingebetteter Inhalt]
Frühanwender wie Thomson Reuters und Berkeley Lab haben seinen Nutzen bereits unter Beweis gestellt, sagt OpenAI. Thomson Reuters nutzte RFT, um einen Rechtsassistenten zu entwickeln, der in der Lage ist, komplexe Rechtstexte zu analysieren, während Berkeley Lab es auf die Genforschung anwendete und Erkenntnisse über seltene Krankheiten lieferte.
Aufbauend auf früheren Innovationen
RFT und o1 Pro Mode sind die neuesten Meilensteine in den Bemühungen von OpenAI, die Leistung und Ausrichtung der KI zu verfeinern. Anfang dieses Jahres führte OpenAI CriticGPT ein, ein Tool, das menschliche Trainer bei der Bewertung von KI-generierten Ausgaben unterstützen soll.
CriticGPT war besonders effektiv bei Codeüberprüfungen und identifizierte Fehler, die menschliche Kommentatoren oft übersehen. Durch die Kombination menschlicher Expertise mit KI-Bewertung möchte OpenAI die Zuverlässigkeit seiner Modelle verbessern.
Konkurrenten wie Microsoft entwickeln ebenfalls KI-Trainingsmethoden weiter. Die Self-Exploring Language Models (SELM) von Microsoft nutzen Belohnungsfunktionen, um die Fähigkeiten zum Befolgen von Anweisungen zu verbessern.
Die Vorfreude auf GPT-4.5
Da OpenAIs „12 Die Kampagne „Days of OpenAI“ geht weiter, die Spekulationen über GPT-4.5 nehmen zu. GPT-4.5 wird voraussichtlich noch in diesem Monat auf den Markt kommen und Gerüchten zufolge bessere Argumentation, erweiterte multimodale Fähigkeiten und Verbesserungen bieten Branchenbeobachter sehen darin eine mögliche Lösung für die Einschränkungen des o1 Pro-Modus, insbesondere bei Aufgaben, die Anpassungsfähigkeit und Abstraktion erfordern.
Philip, der Entwickler des angesehenen SimpleBench-Benchmarks, kommentierte das Potenzial von GPT-4.5, mit der Aussage: „200 US-Dollar pro Monat nur für den Pro-Modus werden sie auf keinen Fall rechtfertigen.“ Die Hinzufügung von GPT-4.5 könnte das Wertversprechen des ChatGPT Pro-Plans neu definieren, aktuelle Mängel beheben und seine Attraktivität für ein breiteres Publikum erweitern.
Die Einführung von RFT und o1 Pro Mode markiert einen Fortschritt in OpenAI Mission, KI-Fähigkeiten an reale Anforderungen anzupassen. Während diese Tools für spezielle Anwendungen vielversprechend sind.