Google DeepMind 推出了 FACTS Grounding,這是一項新基準測試,旨在測試大型語言模型 (LLM) 產生事實準確、基於文件的回應的能力。
此基準測試在 Kaggle 上託管,旨在解決最緊迫的挑戰之一人工智慧:確保人工智慧的輸出是基於提供給他們的數據,而不是依賴外部知識或引入幻覺——看似合理但不正確的資訊。
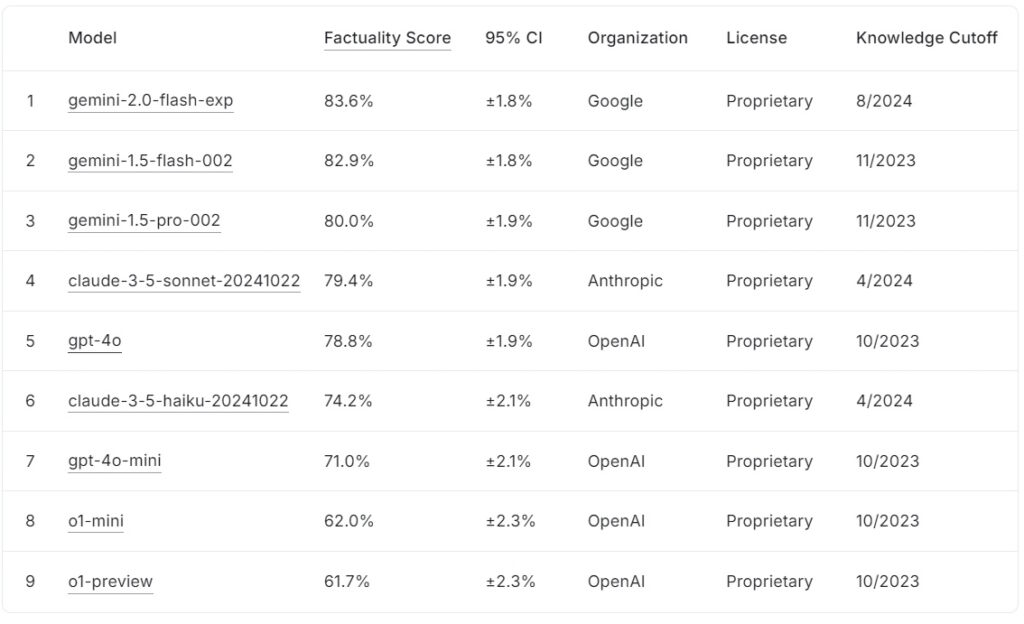
目前的FACTS Grounding 排行榜根據事實分數對大型語言模型進行排名,Google的gemini-2.0-flash-exp 領先(83.6%),緊隨其後的是gemini-1.5-flash-002(82.9%)和gemini-1.5-pro-002(80.0%) 。
Anthropic 的claude-3.5-son-2024102 >以79.4%排名第四,而OpenAI的gpt-4o達到78.8%,排名第五。排名後的是 Anthropic 的 claude-3.5-haiku-20241022 得分 74.2%,其次是 gpt-4o-mini 得分 71.0%。
OpenAI 的較小模型o1-mini 和o1-preview 以62.0% 和62.0% 的成績躋身排行榜>61.7%,分別。
 來源:Kaggle
來源:Kaggle
FACTS Grounding 的獨特之處在於需要綜合詳細輸入文件的長格式回應,使得它是迄今為止最嚴格的人工智慧真實性基準之一。透過評估醫學、法律、金融、零售和技術等領域的法學碩士,該基準為提高現實場景中人工智慧的可靠性奠定了基礎。
根據DeepMind 的研究團隊的說法,「基準衡量的是法學碩士生成專門基於所提供上下文的響應的能力……即使上下文與預訓練知識相衝突。」
現實世界複雜性資料集
FACTS Grounding 包含1,719 個範例,由人工註釋者整理,以確保相關性和多樣性。個標記的詳細文件。了需要創造力、數學推理或內容的任務。為兩部分:860 個可供外部使用的公共範例和859 個私人範例保留用於排行榜評估。
這種雙重結構可以保障基準的完整性,同時鼓勵全球人工智慧開發人員的合作。研究團隊指出:“我們根據提供的測試數據嚴格評估我們的自動評估器,以驗證他們在我們任務中的表現”,並強調了支持FACTS 接地的精心設計。與同儕一起判斷準確性AI 模型
與傳統基準不同,FACTS Grounding 採用同儕審查流程,涉及三個高階LLM:Gemini 1.5 Pro、GPT-4o 和Claude 3.5 Sonnet。模型充當法官,對答案進行評分。條件的回答進行評估,以評估其在來源材料中的基礎。指出:「專注於評估生成文字真實性的指標…可以透過忽略使用者請求背後的意圖。透過給予較短的回應來避免傳達全面的訊息…可以在不提供有用回應的情況下獲得較高的事實性分數。包括跨度層級和基於JSON 的方法,進一步確保與人類判斷的一致性和對不同任務的適應性。 p>人工智慧幻覺是廣泛傳播的最重要障礙之一在關鍵領域採用法學碩士的錯誤,導致模型生成看似合理但實際上不正確的結果,為醫療保健、法律分析和財務報告等領域帶來了嚴重風險。與使用者的意圖保持一致。
該研究論文強調了這一區別:「在生成法學碩士回覆的同時確保事實準確性具有挑戰性。 LLM事實性的主要挑戰是建模(即架構、訓練和推理)和測量(即評估方法、數據和指標)。/h2>
長格式輸入的複雜性帶來了獨特的技術挑戰,特別是在設計能夠準確評估此類回應的自動化評估方法方面。過程來驗證回應。 ,並指出,“取消不合格的答案的資格。導致減少……因為這些反應被視為不準確。”
這種嚴格執行相關性可確保模型不會因規避任務精神而獲得獎勵。 >DeepMind 決定在Kaggle 上主辦FACTS Grounding 反映出其致力於促進整個人工智慧產業合作的承諾。透過開放資料集的公共部分,該專案邀請人工智慧研究人員和開發人員根據強大的標準評估他們的模型,並為推進事實基準做出貢獻。
這種方法符合人工智慧領域透明度和共享進步的更廣泛目標,確保準確性和基礎性的改進不限於單一組織。不同基準
FACTS Grounding 與其他基準的區別在於,它注重以新引入的輸入為基礎,而不是預先訓練的知識。
OpenAI 的 SimpleQA 等基準測試評估模型檢索和利用訓練語料庫中的信息的能力,而 FACTS Grounding 則評估模型僅根據提供的數據綜合和闡明響應的能力。 >這種差異對於解決模型先入為主或固有偏見帶來的挑戰至關重要。透過隔離處理外部輸入的任務,FACTS Grounding 可確保效能指標反映模型在動態、真實場景中運作的能力,而不是簡單地重複預先學習的資訊。
正如DeepMind 在其研究論文中所解釋的那樣,該基準測試旨在評估法學碩士管理具有事實依據的複雜、長格式查詢、模擬與現實世界應用相關的任務的能力。/p>
法學碩士接地的替代方法
有幾種方法提供與 FACTS Grounding 類似的接地功能,每種方法都有其優點和缺點。這些方法旨在透過改善對準確資訊的存取或改進其訓練和對齊過程來增強法學碩士輸出。 >檢索增強生成(RAG)透過從外部知識庫或資料庫動態檢索相關資訊並將其合併來提高LLM輸出的準確性進入模型的回應。 RAG 不是重新訓練整個 LLM,而是透過攔截使用者提示並用最新資訊豐富它們來運作。回應提供高度相關的上下文。文件或其片段根據其語義嵌入進行索引,從而允許系統將使用者的查詢與上下文最相關的條目相匹配。這種方法確保法學碩士根據最新、最相關的資料產生回應。 FACTS Grounding 評估法學碩士保持錨定所提供的上下文文件的能力,而RAG 則透過使法學碩士能夠動態擴展其知識、從外部資源中汲取知識以增強事實性和相關性來補充這一點。 >
知識蒸餾
知識蒸餾涉及轉移大型複雜模型的功能(稱為作為教師)到一個較小的、特定於任務的模型(學生)。此方法提高了效率,同時保留了原始模型的大部分準確性。知識蒸餾主要使用兩種方法:
基於反應的知識蒸餾:重點是複製教師模型的輸出,確保學生模型針對給定的輸入產生相似的結果。/p>
基於特徵的知識蒸餾:從教師模型中提取內部表示和特徵,使學生模型能夠複製更深入的見解。小的模型,知識蒸餾可以在資源有限的環境中部署法學碩士,而不會造成性能的重大損失。與評估接地保真度的FACTS Grounding 不同,知識蒸餾更著重於擴展LLM 能力並針對特定任務進行最佳化。 >
微調涉及透過對預訓練的法學碩士進行精心策劃的培訓,使他們適應特定領域或任務事實基礎至關重要的資料集。例如,包含科學文獻或歷史記錄的資料集可用於提高模型產生準確且特定領域輸出的能力。該技術增強了專業應用程式(例如醫學或法律文件分析)的LLM 效能。獲得的知識。事實基礎著重於在孤立的背景下測試事實性,而微調則旨在提高法學碩士在特定領域的基線表現。/h4>
人類回饋強化學習 (RLHF) 將人類偏好納入法學碩士的訓練過程中。透過迭代訓練模型,使其反應與人類回饋保持一致,RLHF 改進了輸出的品質、真實性和有用性。人類評估者對 LLM 的輸出進行評分,這些分數用作優化模型的訊號。 FACTS Grounding 根據特定文件評估事實依據,而 RLHF 則強調將 LLM 輸出與人類價值觀和偏好保持一致。 遵循指示和上下文學習涉及透過在使用者提示中精心設計的範例來展示法學碩士的基礎知識。這些方法依賴於模型從幾次演示中進行概括的能力。雖然這種方法可以快速改進,但它可能無法達到與微調或基於檢索的方法相同程度的基礎品質。 >LLM可以與外部工具和API集成,以提供對外部資料的即時訪問,從而顯著增強其基礎能力。例如:
瀏覽功能:使法學碩士能夠從網絡訪問和檢索實時信息,以回答特定問題或更新他們的知識。強>API呼叫:允許法學碩士與結構化資料庫或服務交互,透過精確和最新的資訊豐富回應。碩士的實用性。雖然FACTS Grounding 評估內部接地保真度,但外部工具提供了擴展和驗證事實性的替代方法。/h2 >
幾種開源實作可用於上面討論的替代接地方法:

