DeepSeek AI 發布了 DeepSeek-VL2,這是一系列視覺語言模型 (VLM),現已在開源許可下提供。該系列推出了三種變體:Tiny、Small 和標準 VL2,激活參數大小分別為 10 億、28 億和 45 億。
這些模型可透過 GitHub 和擁抱臉。他們承諾推動關鍵的人工智慧應用,包括視覺問答(VQA)、光學字元辨識(OCR)以及高解析度文件和圖表分析。
根據 GitHub 官方文檔,「DeepSeek-VL2 在各種任務中展示了卓越的能力,包括但不限於視覺問答、文檔/表格/圖表理解和視覺基礎。」
此版本的發佈時機使DeepSeek AI 與OpenAI 和GoogleAAAICTAEAOw==”>
此版本的發佈時機使DeepSeek AI 與OpenAI 和Google 等主要參與者直接競爭,Google者都透過GPT-4V 和Gemini-Exp 等專有模型主導了視覺語言AI 領域。它作為研究人員的免費選項。它的動態平鋪視覺編碼策略,徹底改變了模型處理高解析度視覺資料的方式。圖塊,以適應各種寬高比。此方法確保了詳細的特徵提取,同時保持了計算效率。
在其GitHub 儲存庫上,DeepSeek 將其描述為一種「有效處理具有不同縱橫比的高解析度影像,避免通常與增加影像解析度相關的運算縮放的方法。」
此功能使DeepSeek-VL2 在視覺基礎等應用中表現出色,在這些應用中,高精度對於識別複雜影像中的物件至關重要,而在密集的OCR 任務中,則需要處理詳細文件或圖表中的文字。 p>
專家與多方的混合-Head Latent Attention 提高效率
DeepSeek-VL2 的性能提升得到了其對Mixture-of-Experts (MoE) 框架和Multi-head Latent Attention (MLA) 機制的整合的進一步支援。這種設計透過僅使用每個操作所需的參數來減少計算開銷,這項功能在資源受限的環境中特別有用。補充MoE 框架。這種優化可最大限度地減少記憶體使用並提高處理速度,而不會犧牲模型的準確性。
根據技術文檔,“MoE 架構與MLA 相結合,使DeepSeek-VL2 能夠比激活參數較少的密集模型獲得有競爭力或更好的性能。”
三階段訓練流程
DeepSeek-VL2 的發展涉及嚴格的三階段訓練流程,旨在優化模型的多模態功能。模型經過訓練,可以將視覺特徵與文字資訊整合起來。 ,包括WIT、WikiHow 和多語言OCR 數據,以增強模型跨多個領域的泛化能力
最後,第三階段包括監督微調(SFT),其中任務-使用特定數據集來改進模型在視覺基礎、圖形使用者介面(GUI) 理解和密集字幕等領域的表現。專門的任務。多語言資料集的納入進一步增強了模型在全球研究和工業環境中的適用性。領域的領先地位
p>
基準測試結果
DeepSeek-VL2 模型(包括Tiny、Small 和標準變體)在一般問答(QA)和數學的關鍵基準測試中表現出色相關的多模式任務。
DeepSeek-VL2-Small 擁有 28 億個活化參數,MMStar 得分為 57.0,表現優於 InternVL2-2B (49.8) 和 Qwen2-VL-2B (48.0) 等類似大小的模型。它還可以與更大的模型相媲美,例如 4.1B InternVL2-4B (54.3) 和 8.3B Qwen2-VL-7B (60.7),展示了其競爭效率。推理方面,DeepSeek-VL2-Small 取得了80.0 的分數,超過了InternVL2-2B(74.1)和MM 1.5-3B(未報導)。即使與InternVL2-4B (78.9) 和MiniCPM-V2.6 (82.1) 等規模較大的競爭對手相比,DeepSeek-VL2 也以較少的激活參數展示了強勁的結果。=”1024″height=”673″src=”https://winbuzzer.com/wp-content/uploads/2024/12/DeepSeek-VL2-multimodal-QA-and-math-benchmarks-official-1024×673.jpg”>來源:DeepSeek
旗艦DeepSeek-VL2 模型(45 億個啟動參數)取得了出色的結果,在 MMStar 上得分為 61.3,在 AI2D 上得分為 81.4。其性能優於Molmo-7B-O(7.6B激活參數,39.3)和MiniCPM-V2.6(8.0B,57.5)等競爭對手,進一步驗證了其技術優勢。 OCR卓越-相關基準
DeepSeek-VL2 的功能顯著擴展到 OCR(光學字元辨識)相關任務,這是人工智慧中文檔理解和文字擷取的關鍵領域。在DocVQA 測試中,DeepSeek-VL2-Small 取得了令人印象深刻的92.3% 準確率,優於所有其他類似規模的開源模型,包括InternVL2-4B (89.2%) 和MiniCPM-V2.6 (90.8%) 。其準確率僅落後於 GPT-4o (92.8) 和 Claude 3.5 Sonnet (95.2) 等封閉模型。 4B (81.5) 和MiniCPM-V2.6 (82.4)。這一結果反映了DeepSeek-VL2 處理圖表和從複雜視覺數據中提取見解的高級能力。==”>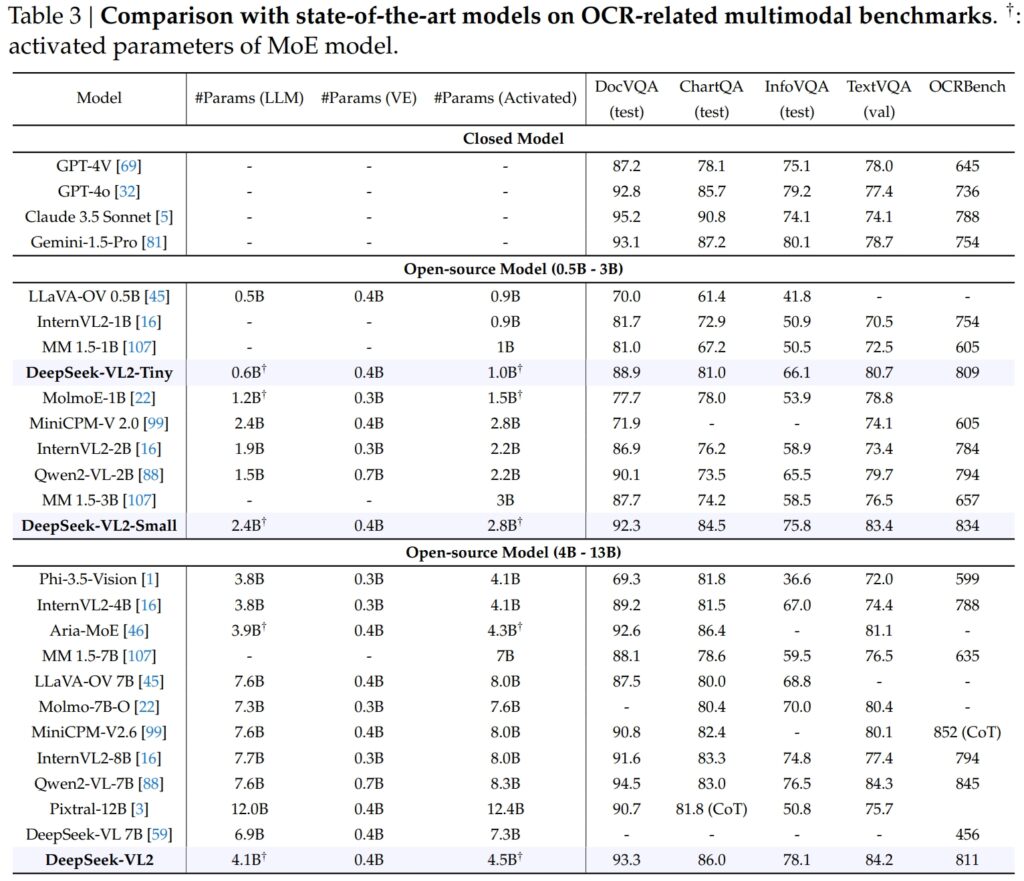 來源:DeepSeek
來源:DeepSeek
在OCRBench(一項極具競爭力的細粒度文字辨識指標)中,DeepSeek-VL2 取得了811 分,超越了7.6B Qwen2-VL-7B (845) 和MiniCPM-V2.6(帶CoT 的852) ,並強調其在密集OCR 任務中的優勢。與OpenAI 的GPT-4V 和Google 等行業領導者放在一起時Gemini-1.5-Pro、DeepSeek-VL2 型號在性能和效率之間實現了令人信服的平衡。例如,GPT-4V 在 DocVQA 中得分為 87.2,僅略高於 DeepSeek-VL2(93.3),儘管後者在開源框架下運行且激活參數較少。 VL2-Small 達到83.4,明顯優於InternVL2-2B (73.4) 和MiniCPM-V2.0 (74.1) 等類似開源模型。即使是更大的MiniCPM-V2.6(8.0B)也僅達到80.4,進一步凸顯了DeepSeek-VL2架構的可擴展性和效率。了Pixtral-12B (81.8) 和InternVL2-8B (83.3),展示了其在需要精確視覺文本理解的專業任務中表現出色的能力。 AI 首次推出Pixtral 12B for Text與影像處理
擴充應用:從接地對話到視覺說故事
DeepSeek-VL2 模型的一個顯著特點是它們能夠進行接地對話,模型可以識別圖像中的物件並將其整合到上下文討論中。
例如,透過使用專門的令牌,模型可以提供特定於物件的詳細資訊(例如位置和描述)來回答有關圖像的查詢。這為需要精確視覺推理的機器人、擴增實境和數位助理等應用開闢了可能性。 DeepSeek-VL2 可以結合其先進的視覺識別和語言功能,基於一系列圖像生成連貫的敘述。
這在教育、媒體和娛樂等領域尤其有價值,因為動態內容創作是這些領域的首要任務。這些模型利用強大的多模態理解來製作詳細且適合上下文的故事,將地標和文字等視覺元素無縫地整合到敘事中。在涉及複雜影像的測試中,DeepSeek-VL2展示了根據描述性提示準確定位和描述物體的能力。
例如,當被要求識別「停在街道左側的汽車」時,模型可以精確定位圖像中的確切物件並產生邊界框座標來說明其響應。自主系統和監視,其中詳細的視覺分析至關重要。作為一種開源技術,與OpenAI 的GPT-4V 和Google 的Gemini-Exp 等競爭對手的專有性質形成鮮明對比,後者是專為有限公共訪問而設計的封閉系統。根據技術文檔,“透過公開我們的預訓練模型和程式碼,我們的目標是加快視覺語言建模的進展,並促進整個研究界的協作創新。”
DeepSeek-VL2 的可擴展性進一步增強了它們的吸引力。這些模型針對各種硬體配置的部署進行了最佳化,從具有 10GB 記憶體的單 GPU 到能夠處理大規模工作負載的多 GPU 設定。
這種彈性確保DeepSeek-VL2 可供各種規模的組織(從新創公司到大型企業)使用,而無需專門的基礎設施。和技術方面的創新訓練
DeepSeek-VL2成功的一個主要因素是其廣泛且多樣化的訓練資料。預訓練階段合併了 WIT、WikiHow 和 OBELICS 等資料集,這些資料集提供了用於泛化的交錯影像文字對的混合。
特定任務(例如 OCR 和視覺問答)的附加資料來自 LaTeX OCR 和 PubTabNet 等來源,確保模型能夠高精度地處理一般任務和專業任務。納入也體現了DeepSeek AI 的全球適用性目標。像萬卷這樣的中文資料集與英文資料集整合在一起,以確保模型能夠在多語言環境中有效運作。
這種方法增強了DeepSeek-VL2 在非英語資料主導的地區的可用性,顯著擴大了其潛在用戶群。的透過專注於 GUI 理解和圖表分析等特定任務來增強能力。透過將內部資料集與高品質的開源資源結合,DeepSeek-VL2 在多個基準測試中實現了最先進的效能,驗證了其訓練方法的有效性。策劃大量的資料和創新的訓練流程使 VL2 模型能夠在各種任務中表現出色,同時保持效率和可擴展性。這些因素使它們成為多模態AI 領域的寶貴補充。 。在物流中,他們可以透過分析倉庫庫存圖像、識別物品並將結果整合到庫存管理系統中來實現庫存追蹤自動化。
在安全領域,DeepSeek-VL2可以根據描述性查詢即時識別物體或個人,並向操作員提供詳細的上下文信息,從而協助監視。接地對話功能也為機器人和擴增實境提供了可能性。例如,配備該模型的機器人可以直觀地解釋其環境,響應人類對特定物件的查詢,並根據對視覺輸入的理解執行操作。
同樣,擴增實境裝置可以利用模型的視覺基礎和說故事功能來提供互動式、身臨其境的體驗,例如即時環境中的導遊或上下文疊加。 >挑戰與未來前景
儘管 DeepSeek-VL2 具有眾多優勢,但仍面臨一些挑戰。一個關鍵限制是其上下文視窗的大小,目前限制了單次互動中可以處理的圖像數量。
在未來的迭代中擴展此上下文視窗將實現更豐富的多圖像交互,並增強模型在需要更廣泛的上下文理解的任務中的實用性。一個挑戰在於處理超出範圍的情況。雖然 DeepSeek-VL2 已展現出卓越的泛化能力,但提高針對此類輸入的穩健性將進一步提高其在現實場景中的適用性。
展望未來,DeepSeek AI 計畫加強其模型的推理能力,使其能夠處理日益複雜的多模態任務。透過整合改進的訓練流程和擴展資料集以涵蓋更多樣化的場景,DeepSeek-VL2 的未來版本可以為視覺語言 AI 效能設定新的基準。