蒙特利爾的一位三星人工智能研究人員創建了一個微型人工智能模型,其作用遠遠超出了其自身的能力,挑戰了行業對大規模的關注。本週發布的 700 萬參數微型遞歸模型 (TRM) 在棘手的推理難題上優於 Google Gemini 2.5 Pro 等巨型模型。
該模型由 Alexia Jolicoeur-Martineau 開發,詳細信息 arXiv 上發表的一篇論文旨在證明巧妙的設計比純粹的尺寸更重要。它使用簡單的“遞歸”過程來循環思考並改進自己的答案,從而提供更有效的創新路徑。
這種方法質疑是否需要龐大且昂貴的模型來解決人工智能難題。正如 Jolicoeur-Martineau 所說,“必須依賴一些大公司花費數百萬美元訓練的大規模基礎模型才能解決艱鉅任務的想法是一個陷阱。”該版本標誌著朝著更小型、專業模型的發展趨勢不斷發展。
從復雜層次結構到遞歸 簡單性
TRM 源自分層推理模型 (HRM),但從根本上簡化了其設計。今年早些時候推出的 HRM 使用兩個以不同頻率運行的獨立網絡,其創建者通過有關人腦的複雜生物學論證來證明這一概念。
該方法還依賴於隱式函數定理等高級數學原理來管理其學習過程,因此難以解析。 Jolicoeur-Martineau 的工作剝離了這些抽象層。
TRM 僅使用單個微小的兩層網絡。它消除了生物學類比和定點依賴性,使架構更加透明。目標是分離出核心機制:遞歸改進。
核心創新在於其推理過程。該模型從一個粗略的答案開始,然後迭代地完善它。在每個循環中,它首先更新其內部“思維過程”,然後再更新其最終答案,從而有效地模擬更深層次的網絡,而無需高昂的成本。
這種自我改進的循環是“深度監督”的一種形式,模型在每一步都經過訓練,以更接近正確的解決方案。這使得它能夠學習複雜的、多步驟的推理鏈,而這些推理鏈通常需要更大的模型。
正如研究論文所解釋的那樣,“這種遞歸過程允許模型以極其參數有效的方式逐步改進其答案……同時最大限度地減少過度擬合。”這種方法可以提高性能,並避免較大模型在小數據集上面臨的問題。
在推理基準測試中超額發揮
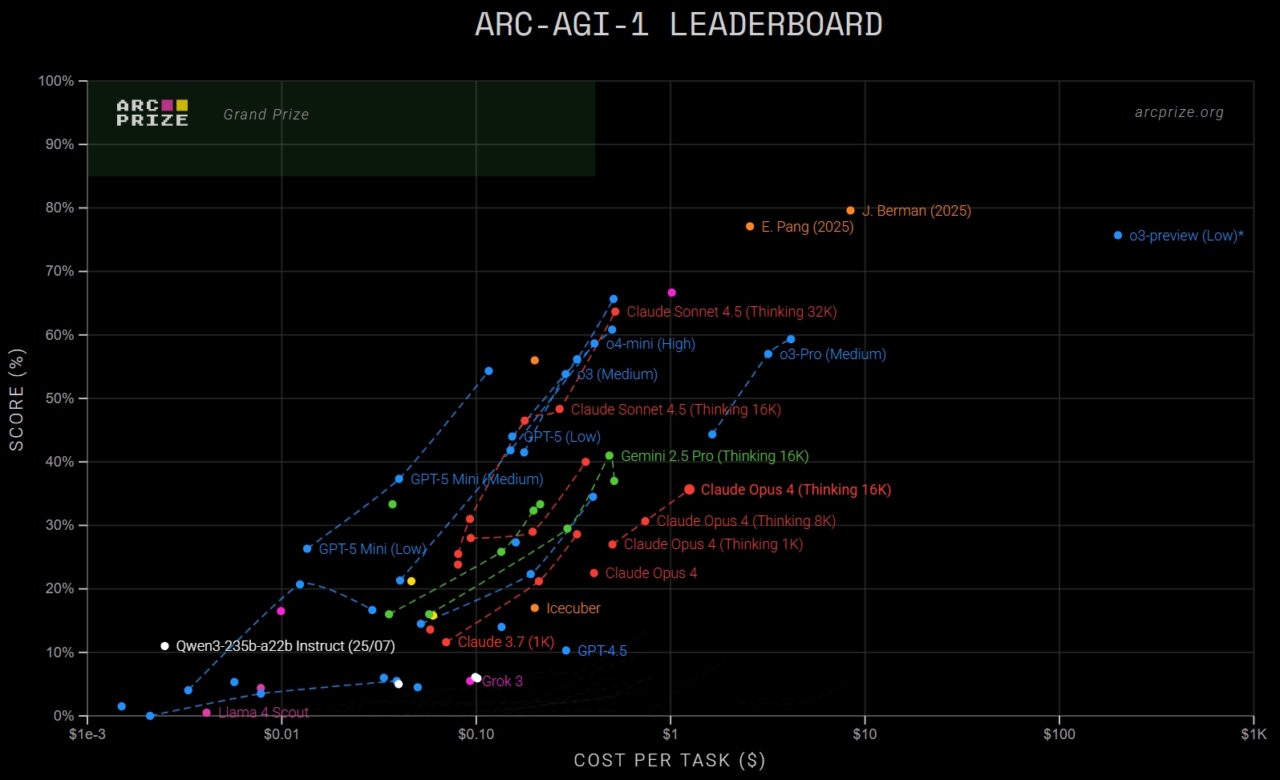
TRM 的威力在旨在測試抽象 AI 推理的基準測試中表現得最為明顯,在這個領域,即使是最大的模型也常常陷入困境。它的傑出成就來自抽象與推理語料庫 (ARC-AGI),這是一套具有挑戰性的視覺謎題,對人類來說很簡單,但對人工智能來說卻非常困難。
在測試的第一個版本 ARC-AGI-1 中,TRM 達到了 45% 的準確率。這一分數超過了許多業界重量級產品,包括 Google 的 Gemini 2.5 Pro (37.0%)、OpenAI 的 o3-mini-high (34.5%) 和 DeepSeek R1 (15.8%),儘管 TRM 的參數不到 0.01%。
該模型的優勢在更困難的 ARC-AGI-2 基準測試中依然存在。在這裡,TRM 得分為 7.8%,再次擊敗 Gemini 2.5 Pro 的 4.9% 和 o3-mini-high 的 3.0%。雖然這些絕對分數可能看起來很低,但它們代表了在進展緩慢的基准上的重大飛躍。
就上下文而言,當前排行榜由 xAI 的 Grok 4 等大規模前沿模型占據首位,但 TRM 僅 700 萬個參數的性能使其成為一個引人注目的指標 離群值,突出了其架構的效率。
該模型的主導地位擴展到了大型模型經常出現問題的其他邏輯領域。在 Sudoku-Extreme(一個只有 1,000 個訓練樣本的困難謎題數據集)上,TRM 創下了新的最先進記錄,達到 87.4% 的準確率。這比其前身 HRM 的得分 55% 有了巨大的進步。
同樣,在 Maze-Hard 基準測試中,TRM 得分為 85.3%,該基準涉及通過複雜的 30×30 網格尋找長路徑。這些跨多個不同邏輯領域的結果展示了遞歸方法在解決結構化問題方面的強大功能。
“少即是多”:高效人工智能的新哲學
也許是最引人注目的 是模型的效率。研究人員證實,整個模型僅用兩天時間就在四塊 NVIDIA H-100 GPU 上進行了訓練,費用不到 500 美元。這與當今前沿法學碩士所需的數百萬美元的培訓形成鮮明對比。
<500 美元,4 H-100 大約 2 天
— Alexia Jolicoeur-Martineau (@jm_alexia) 2025 年 10 月 7 日
Jolicoeur-Martineau 強調了這一點,並指出,“ 遞歸推理,結果證明“少即是多”。一個從頭開始預訓練的微型模型……可以在不花太多錢的情況下取得很多成果。”這種成本效益使尖端人工智能研究民主化。
較小的兩層網絡優於較大版本的發現也挑戰了傳統的縮放定律。該論文認為,這是因為遞歸深度有助於防止過度擬合,這是在有限數據上訓練大型模型時的常見問題。
人工智能研究工程師 Sebastian Raschka 評論了效率,並指出,“是的,在沒有數據中心的情況下仍然可以做很酷的事情。”
從層次推理模型 (HRM) 到新的微型遞歸模型 (TRM)。
幾個月前,HRM 在人工智能研究界掀起了軒然大波,儘管它的大小只有 27M,但它在 ARC 挑戰中表現出了非常好的性能。 (這比… pic.twitter.com/YhMpn4hlxi
-Sebastian Raschka (@rasbt) 2025 年 10 月 8 日
該項目是 在 GitHub 上,具有寬鬆的 MIT 許可證,允許商業用途並鼓勵更廣泛的採用。
專業求解器,而不是通才
了解 TRM 至關重要 上下文。該模型是一個高度專業化的求解器,而不是像基於 OpenAI 或 Google 模型的通用聊天機器人。它的性能僅限於結構化、基於網格的任務,其中遞歸方法在這些任務中表現出色。
這種專業化是一個功能,而不是一個錯誤。正如 Menlo Ventures 合夥人 Deedy Das 所觀察到的那樣,“如今大多數人工智能公司都使用帶有任務提示的通用法學碩士。對於特定任務, 較小的模型可能不僅更便宜,而且質量更高!”
TRM 論文感覺像是人工智能的重大突破。
它破壞了 ARC AGI 1 和 2 基準(以及數獨和迷宮求解)上的帕累托前沿,每個任務的 estd <0.01 美元成本,在 2 個 H100 上訓練 7M 模型 2 小時的成本 <500 美元 天。
[培訓和測試細節]… pic.twitter.com/9c31HdxiLy
— Deedy (@deedydas) 2025 年 10 月 9 日
這個焦點意味著 TRM 不會寫詩或總結會議。然而,它的成功提供了一個 為企業提供強大的概念驗證。它表明,一組小型專家模型可能比單個整體通才模型更有效和高效。
雖然人工智能社區讚揚了這項創新,但有些人指出了其狹窄的領域。人們的共識是,雖然 TRM 不是通用智能的一種形式,但它傳達的信息是廣泛的:仔細的遞歸,而不僅僅是不斷的擴展,可以推動下一波推理 研究。