隨著GPT-5型號的動盪推出,OpenAI正在測試Chatgpt的新“思維工作”功能,從而為用戶提供了對AI性能的顆粒狀控制。實驗環境在8月下旬發現,使用戶可以從四個級別的計算強度中進行選擇。
此舉是對損壞GPT-5發射的廣泛批評的直接響應,該批評促使該公司還原其流行的GPT-4O模型並添加手動控件。通過讓用戶平衡響應速度與分析深度,OpenAI的目標是解決可靠性問題並改善用戶體驗。目的是消除首席執行官山姆·奧特曼(Sam Altman)所說的不同模型的“混亂混亂”。但是,雄心勃勃的策略很快就揭開了。該模型發明了虛構的狀態名稱,例如“ Onegon”,在基本數學上失敗了,並產生了荒謬的輸出,從而導致了廣泛的反彈。公眾接待是如此負面,以至於該公司被迫陷入罕見的防禦姿態。
8月8日,阿爾特曼(Altman)發出了公眾道歉。他承認,模型的內部模式之間的“有缺陷的“自動開關”使它的“笨拙”比預期的要長,”將技術缺陷歸咎於糟糕的表現。這種絆腳石為批評家提供了彈藥,並為競爭對手創造了一個開幕式,他們很快就可以利用這種情況。
幾天后,8月12日,Openai執行了重大的逆轉。它恢復了GPT-4O,用於支付訂戶並為GPT-5引入手動模式:“自動”,“快速”和“思考”。這個樞紐指示了AI領導者關於平衡創新與用戶期望的主要課程。
新的“思考工作”功能似乎是該課程校正的更詳細的演變。阿爾特曼本人暗示了這一轉變,他說:“從過去的幾天開始,我們真的只需要到達一個擁有更多按用戶自定義模型個性的世界。
Openai的Chatgpt副總裁Nick Turley,Nick Turley,尼克·特利(Nick Turley),承認這是一個迭代的過程,我們並不總是能夠快速地嘗試#1,這是一個快速的努力,這是一個快速的努力。用戶反饋。
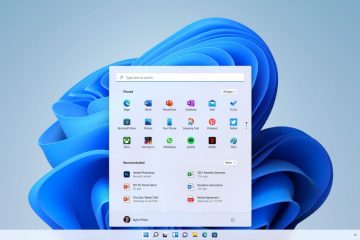
在引擎蓋下:“思維工作”如何工作
新的努力選擇器使用戶直接影響了模型的計算預算。據報導,該功能呈現出四個不同級別的強度供用戶選擇。這些是“輕”,“標準”,“擴展”和“最大”和“最大”
新的chatgpt Web應用程序版本具有更新的(隱藏的)思維精力選擇器- Max Thinker – Max Thinking(200),擴展思維(48),標準思維(18),光思維(18),光思維(5)
pic.twitter.com/onwcbq4cuw
該分層系統允許用戶根據特定任務量身定制AI的性能。用戶可能會選擇“輕”,以進行快速,簡單的問題,但在處理需要更徹底的推理的複雜問題(例如債券估值或代碼分析)時切換到“擴展”或“最大”。
這可能是新的分層績效策略的暗示,有可能打開簡單訂閱的未來貨幣化模型。它正式化了速度和質量之間的權衡,這是大規模AI部署中的核心挑戰。
對對AI安全性的更深層關注的反應
這不僅僅是對更大的用戶控制的推動,這不僅在於修復otched發射;它反映了一個更廣泛的行業,以AI的可靠性和安全性計算。 The feature arrives shortly after OpenAI and rival Anthropic published the results of joint safety tests on August 28.
Those evaluations, framed by some as a在AI軍備競賽中的“決鬥”揭示了兩家公司模型中令人震驚的缺陷。這些報告詳細介紹了諸如“極端粘糊精”之類的問題,模型將驗證用戶的妄想信念,並願意協助危險要求。
測試還強調了哲學上的鴻溝。 Anthropic的模型通常拒絕回答以避免錯誤,從而優先考慮效用。相比之下,OpenAi的模型更有幫助,但在受控測試中提供了更多的事實錯誤或幻覺,以提供更多的事實錯誤或幻覺。馬庫斯(Marcus)爭辯說:“沒有任何具有智力誠信的人仍然可以相信純正的縮放會使我們進入AGI,”對整個“更大的IS更好”範式質疑。
我在這裡的工作確實完成了。沒有任何具有智力完整性的人仍然可以相信,純縮放會使我們進入AGI。
gpt-5可能是中等定量的改進(並且可能更便宜),但它仍然以與前任,在國際象棋上,……
– Gary Marcus(Gary Marcus(Gary Marcus)(@Garymarcus)(@Garymarcus)<@garymarcus)的所有定性方式失敗。 href=“ https://twitter.com/garymarcus/status/1953939152594252170?ref_src=twsrc;在公司中聲稱,“安全文化和流程已將閃亮產品的倒退。 ”
通過將“思考工作”撥號直接放在用戶手中,OpenAI正在授權他們減輕其中的某些風險。此舉向從“單一適合所有”的自動化方法到更透明,可自定義且最終更具辯護的用戶體驗的戰略樞紐。