中國人工智慧實驗室 DeepSeek 推出了下一代開源語言模式 DeepSeek V3。該模型擁有 6,710 億個參數,採用所謂的專家混合 (MoE) 架構,將運算效率與高效能結合。
DeepSeek V3 的技術進步使其躋身迄今為止最強大的人工智慧系統之列,可以與Meta 的Llama 3.1 等開源競爭對手和OpenAI 的GPT-4o 等專有模型相媲美。競爭,甚至在某些情況下表現優於其他人—成本更高、封閉的替代方案。 R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==”>
相關:
中國DeepSeek R1-Lite-Preview模型瞄準OpenAI自動推理領先地位
阿里巴巴Qwen發布QVQ-72B-Preview多態性模AI模型
高效創新架構
DeepSeek V3 的架構結合了兩個先進的概念,以實現卓越的效率和性能:多頭潛在註意力(MLA) 和混合專家(MoE)。/p>
另一方面,MoE 僅激活模型總數6710 億的一個子集每個任務大約有 370 億個參數,確保計算資源得到有效利用而不影響準確性。這些機制共同使DeepSeek V3 能夠提供高品質的輸出,同時降低基礎設施需求。無損耗負載-平衡策略。這種動態方法在專家網路中分配任務,保持一致性並最大限度地提高任務準確性。
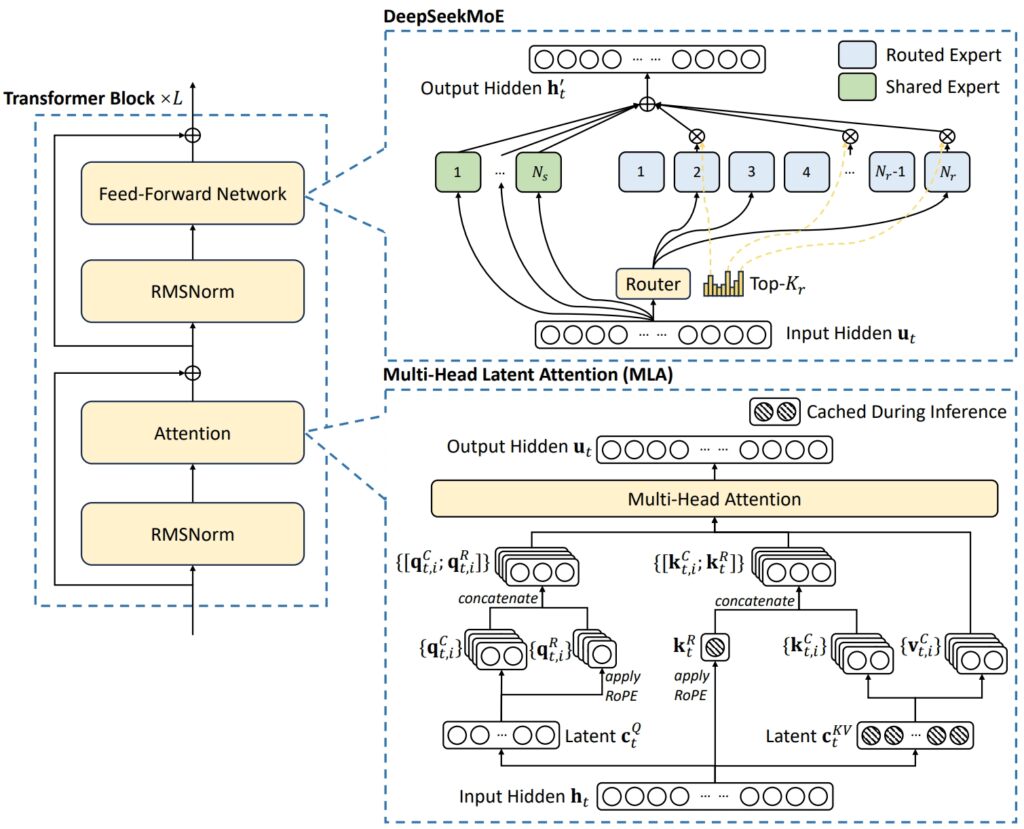 DeepSeek-V3 基本架構示意圖(圖片來源:DeepSeek)
DeepSeek-V3 基本架構示意圖(圖片來源:DeepSeek)
為了進一步提高效率,DeepSeek V3 採用了多令牌預測(MTP) 功能,該功能允許模型同時生成多個令牌,從而顯著加速文字生成。 基準測試表現:數學和編碼領域的領導者
DeepSeek V3 的基準測試結果展示了其在廣泛任務中的卓越能力,鞏固了其作為開源AI 模型領導者的地位。
利用其先進的架構和廣泛的訓練資料集,該模型在數學、編碼和多語言基準測試中取得了頂級性能,同時在傳統上由閉源模型(如OpenAI 的GPT)主導的領域也呈現出有競爭力的結果-4o 和Anthropic 的Claude 3.5 Sonnet。 br>⚡ 60 個令牌/秒(比V2 快3 倍!)
💪 增強功能
🛠 API 相容性完好
🌍 完全開源模型和論文
🐋 1/n pic.twitter.com/p1dV9gJ2Sd
— DeepSeek (@deepseek_ai) 十二月2024 年2 月26 日
數學推理
MGSM(小學數學):得分 79.8,超過 Llama 3.1 (69.9) 和 Qwen 2.5 (76.2)。 CMath(語言數學):得分 90.7,優於 Llama 3.1 (77.3) 和 GPT-4o (84.5)。不僅適用於基於英語的數學推理,也適用於需要解決特定語言的數字問題的任務。
相關:DeepSeek AI開源VL2系列視覺語言模型
程式編碼
DeepSeek V3表現出色編碼與解決問題基準的能力。在競爭性程式設計平台 Codeforces 上,該模型獲得了 51.6 的百分位排名,反映了其處理複雜演算法任務的能力。這一性能明顯超過了 Llama 3.1 等開源競爭對手(得分僅為 25.3),甚至挑戰了得分較低的 Claude 3.5 Sonnet。該模型在特定編碼基準測試中的高分進一步驗證了該模型的成功:
HumanEval-Mul:得分為 82.6,優於 Qwen 2.5 (77.3) 並配對 GPT-4o (80.5)。 LiveCodeBench (Pass@1):得分 37.6,領先 Llama 3.1 (30.1) 和 Claude 3.5 Sonnet (32.8)。 CRUXEval-I:得分 67.3,明顯優於 Qwen 2.5 (59.1) 和 Llama 3.1 (58.5)。
這些結果凸顯了該模型適用於軟體開發和現實編碼環境中的應用,在這些環境中,高效的問題解決和程式碼產生至關重要。非英語任務
DeepSeek V3 在多語言基準測試中也脫穎而出,展現了其處理和理解多種語言的能力。在CMMLU(中文多語言理解)測試中,該模型取得了88.8的優異成績,超越Qwen 2.5(89.5),佔據統治地位Llama 3.1,落後 73.7。同樣,在中國評估基準C-Eval上,DeepSeek V3 得分為90.1,遠遠領先Llama 3.1 (72.5)。 p >在非英語多語言任務中:
特定於英語的基準
雖然DeepSeek V3 在數學、編碼和多語言表現方面表現出色,但其結果在某些方面表現不佳特定於英語的基準反映出改進的空間。例如,在 SimpleQA 基準測試(評估模型用英語回答簡單事實問題的能力)上,DeepSeek V3 得分為 24.9 ,落後於GPT-4o,後者達到了38.2。同樣,在FRAMES(理解複雜敘事結構的基準)上,GPT-4o 得分為80.5,而DeepSeek 的得分為73.3。
儘管存在這些差距,該模型的性能仍然具有很強的競爭力,特別是考慮到其開源性質和成本效率。在英語特定任務中表現稍差的情況被其在數學和多語言基準測試中的主導地位所抵消,在這些領域,它一直挑戰並經常超越閉源競爭對手。的基準測試結果不僅證明了其技術的複雜性,而且還將其定位為適用於各種任務的多功能、高效能模型。它在數學、編碼和多語言基準方面的優越性凸顯了它的優勢,而它在英語任務中的競爭性結果表明它有能力與 GPT-4o 和 Claude 3.5 Sonnet 等行業領導者抗衡。
透過以專有系統相關成本的一小部分提供這些結果,DeepSeek V3 展示了開源AI 與閉源替代方案競爭的潛力,在某些情況下甚至超越閉源替代方案。/p>
相關:蘋果計畫透過騰訊和位元組跳動在中國推出人工智慧
大規模經濟高效的培訓
One DeepSeek V3 的突出成就之一是其經濟高效的訓練過程。該模型使用 Nvidia H800 GPU 在包含 14.8 兆個代幣的資料集上進行訓練,總訓練時間為 278.8 萬個 GPU 小時。總成本為557.6 萬美元,與訓練Meta 的Llama 3.1 所需的估計5 億美元相比只是一小部分。以符合出口要求法規。這兩款 GPU 皆基於 NVIDIA Hopper 架構,主要用於 AI 和高效能運算應用。 H800 的晶片間資料傳輸速率降低至 H100 的大約一半
訓練過程採用了先進的方法,包括 FP8 混合精度訓練。此方法透過以 8 位元浮點格式編碼資料來減少記憶體使用量,而不會犧牲準確性。此外,DualPipe 演算法優化了管道並行性,確保 GPU 叢集之間的平滑協調。
DeepSeek 表示,預訓練DeepSeek-V3 每兆代幣僅需要180,000 H800 GPU 小時,使用2,048 個GPU 叢集。 strong>
DeepSeek 已在 MIT 許可下提供 V3,為開發人員提供了對該模型的存取權以用於研究和商業應用。企業可以透過DeepSeek Chat 平台或API 整合該模型,其價格極具競爭力,每百萬個輸入代幣為0.27 美元,每百萬個輸出代幣為1.10 美元。的多功能性延伸到了與各種硬體平台的兼容性,包括AMD GPU 和華為 Ascend NPU。這確保了具有不同基礎設施需求的研究人員和組織的廣泛可近性。
DeepSeek 強調了其對可靠性和性能的關注,並表示:「為了確保SLO 合規性和高吞吐量,我們在預填充階段對專家採用動態冗餘策略,其中高負載專家會定期複製和重新排列以獲得最佳性能。人工智慧民主化的更廣泛趨勢。更廣泛的實驗和創新。 >
DeepSeek V3 的成功引發了有關未來權力平衡的問題。隨著開源模型不斷縮小與專有系統的差距,它們為組織提供了優先考慮可訪問性和成本效率的有競爭力的替代方案。