O Google DeepMind lançou o FACTS Grounding, um novo benchmark projetado para testar grandes modelos de linguagem (LLMs) quanto à sua capacidade de gerar respostas factualmente precisas e baseadas em documentos.
O benchmark, hospedado no Kaggle, tem como objetivo enfrentar um dos desafios mais urgentes em inteligência artificial: garantir que os resultados da IA se baseiam nos dados que lhes são fornecidos, em vez de dependerem de conhecimentos externos ou da introdução de alucinações – informações plausíveis, mas incorretas.
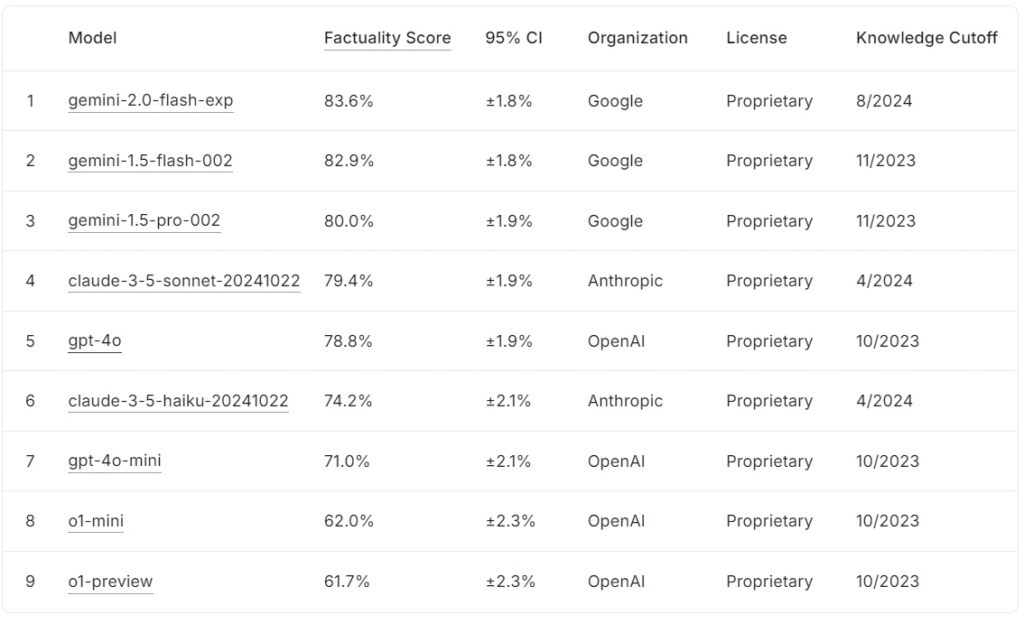
O tabela de classificação FACTS Grounding atual classifica grandes modelos de linguagem com base em suas pontuações de factualidade, com o Google gemini-2.0-flash-exp liderando com 83,6%, seguido de perto por gemini-1.5-flash-002 em 82,9% e gemini-1,5-pro-002 com 80,0%.
Anthropic’s claude-3.5-sonnet-20241022 ocupa o quarto lugar com 79,4%, enquanto OpenAI’s gpt-4o atinge 78,8%, ficando em quinto lugar. Mais abaixo na lista, claude-3.5-haiku-20241022 da Anthropic pontua 74,2%, seguido por gpt-4o-mini com 71,0%.
Os modelos menores da OpenAI, o1-mini e o1-preview, completam a tabela de classificação com 62,0% e 61,7%, respectivamente.
 Fonte: Kaggle
Fonte: Kaggle
FACTS Grounding se destaca por exigir respostas longas que sintetizam documentos de entrada detalhados, tornando-o um dos os benchmarks mais rigorosos para a factualidade da IA até o momento.
FATOS O Grounding representa um desenvolvimento crítico para a indústria de IA, especialmente em aplicações onde a confiança e a precisão são essenciais. Ao avaliar LLMs em domínios como medicina, direito, finanças, varejo e tecnologia, o benchmark prepara o terreno para melhorar a confiabilidade da IA em cenários do mundo real.
De acordo com a equipe de pesquisa da DeepMind, o “referência mede a capacidade dos LLMs de gerar respostas baseadas exclusivamente no contexto fornecido…mesmo quando o contexto entra em conflito com o conhecimento pré-treinamento”.
Conjunto de dados para complexidade do mundo real
FACTS Grounding consiste em 1.719 exemplos, selecionados por anotadores humanos para garantir relevância e diversidade. documentos detalhados que abrangem até 32.000 tokens, equivalentes a aproximadamente 20.000 palavras
Cada tarefa desafia os LLMs a realizar resumos, geração de perguntas e respostas ou reescrita de conteúdo, com instruções estritas para fazer referência apenas aos dados fornecidos. tarefas que exigem criatividade, raciocínio matemático ou interpretação especializada, concentrando-se em testar a capacidade de um modelo de sintetizar e articular informações complexas.
Para manter a transparência e evitar ajustes excessivos, A DeepMind dividiu o conjunto de dados em dois segmentos: 860 exemplos públicos disponíveis para uso externo e 859 exemplos privados reservados para avaliações de tabelas de classificação.
Essa estrutura dupla protege a integridade do benchmark ao mesmo tempo em que incentiva a colaboração de desenvolvedores de IA em todo o mundo. “Avaliamos rigorosamente nossos avaliadores automáticos com base em dados de testes realizados para validar seu desempenho em nossa tarefa”, observa a equipe de pesquisa, destacando o design cuidadoso que sustenta o FACTS Grounding.
Julgando a precisão com pares Modelos de IA
Ao contrário dos benchmarks convencionais, o FACTS Grounding emprega um processo de revisão por pares envolvendo três LLMs avançados: Gemini 1.5 Pro, GPT-4o e Claude 3.5 Sonnet. Esses modelos servem como juízes, pontuando as respostas com base em dois critérios críticos: elegibilidade e precisão factual. As respostas devem primeiro passar por uma verificação de elegibilidade para confirmar que abordam a consulta do usuário de forma significativa. em seguida, avaliados quanto à sua fundamentação no material de origem, com pontuações agregadas entre os três modelos para minimizar preconceitos.
Os pesquisadores da DeepMind enfatizam a importância desta avaliação em várias camadas, afirmando: “Métricas focadas em avaliar a factualidade do texto gerado… podem ser contornadas ignorando a intenção por trás da solicitação do usuário. Ao fornecer respostas mais curtas que evitam a transmissão de informações abrangentes… é possível obter uma alta pontuação de factualidade sem fornecer uma resposta útil.”
O uso de vários modelos de pontuação, incluindo abordagens em nível de extensão e baseadas em JSON , garante ainda mais o alinhamento com o julgamento humano e a adaptabilidade a diversas tarefas.
Enfrentando o desafio das alucinações de IA
As alucinações de IA estão entre os obstáculos mais significativos à disseminação generalizada adoção de LLMs em domínios críticos. Estes erros, em que os modelos geram resultados que parecem plausíveis, mas que são factualmente incorretos, representam sérios riscos em domínios como os cuidados de saúde, a análise jurídica e os relatórios financeiros.
FATOS A fundamentação aborda diretamente esta questão através da aplicação da lei. adesão estrita aos dados de entrada fornecidos. Essa abordagem não apenas avalia a capacidade de um modelo de evitar a introdução de falsidades, mas também garante que os resultados permaneçam alinhados com a intenção do usuário.
Em contraste com benchmarks como o da OpenAI. SimpleQA, que mede a factualidade na recuperação de dados de treinamento, o FACTS Grounding testa quão bem os modelos sintetizam novas informações.
O artigo de pesquisa ressalta esta distinção: “Garantir a precisão factual ao gerar respostas LLM é um desafio. Os principais desafios na factualidade do LLM são modelagem (ou seja, arquitetura, treinamento e inferência) e medição (ou seja, metodologia de avaliação, dados e métricas).”
Desafios técnicos e design de benchmark
A complexidade das entradas de formato longo introduz desafios técnicos únicos, especialmente na concepção de métodos de avaliação automatizados que possam avaliar com precisão tais respostas
FATOS A fundamentação depende computacionalmente. processos intensivos para validar as respostas, empregando critérios rigorosos para garantir a confiabilidade. A inclusão de vários modelos de juízes mitiga possíveis preconceitos e fortalece a estrutura geral de avaliação.
A equipe de pesquisa destaca a importância de desqualificar respostas vagas ou irrelevantes. , “A desqualificação de respostas inelegíveis leva a uma redução… já que essas respostas são tratadas como imprecisas.”
Essa aplicação estrita de relevância garante que os modelos não sejam recompensados por contornar o espírito da tarefa.
Incentivando a colaboração por meio da transparência
A decisão da DeepMind de hospedar o FACTS Grounding no Kaggle reflete seu compromisso em promover a colaboração em toda a indústria de IA. Ao tornar acessível o segmento público do conjunto de dados, o projeto convida investigadores e desenvolvedores de IA a avaliar os seus modelos em relação a um padrão robusto e a contribuir para o avanço dos benchmarks de factualidade.
Essa abordagem se alinha aos objetivos mais amplos de transparência e progresso compartilhado em IA, garantindo que as melhorias na precisão e no fundamento não sejam confinadas a uma única organização.
Diferenciação de outras Benchmarks
FACTOS O Grounding distingue-se de outros benchmarks pelo seu foco na fundamentação em insumos recentemente introduzidos, em vez de conhecimento pré-treinado.
Enquanto benchmarks como o SimpleQA da OpenAI avaliam quão bem um modelo recupera e utiliza informações de seu corpus de treinamento, o FACTS Grounding avalia modelos quanto à sua capacidade de sintetizar e articular respostas com base exclusivamente nos dados fornecidos.
Esta distinção é crucial para enfrentar os desafios colocados pelos preconceitos do modelo ou pelos preconceitos inerentes. Ao isolar a tarefa de processamento de entradas externas, o FACTS Grounding garante que as métricas de desempenho reflitam a capacidade de um modelo de operar em cenários dinâmicos do mundo real, em vez de simplesmente regurgitar informações pré-aprendidas.
Como a DeepMind explica em seu artigo de pesquisa, o benchmark foi projetado para avaliar LLMs quanto à sua capacidade de gerenciar consultas complexas e longas com base factual, simulando tarefas relevantes para aplicativos do mundo real.
Métodos alternativos para LLMs de aterramento
Vários métodos oferecem recursos de aterramento semelhantes ao FACTS Grounding, cada um com seus pontos fortes e fracos. Esses métodos visam aprimorar os resultados do LLM, melhorando seu acesso a informações precisas ou refinando seus processos de treinamento e alinhamento.
Geração Aumentada de Recuperação (RAG)
Retrieval-Augmented Generation (RAG) aumenta a precisão dos resultados do LLM recuperando dinamicamente informações relevantes de bases de conhecimento ou bancos de dados externos e incorporando-os nas respostas do modelo. Em vez de retreinar todo o LLM, o RAG funciona interceptando os prompts do usuário e enriquecendo-os com informações atualizadas.
As implementações avançadas do RAG geralmente aproveitam a recuperação baseada em entidade, onde os dados associados a entidades específicas são unificados para fornecem contexto altamente relevante para respostas LLM.
O RAG normalmente usa técnicas de pesquisa semântica para recuperar informações. Os documentos ou seus fragmentos são indexados com base em suas incorporações semânticas, permitindo ao sistema combinar a consulta do usuário com as entradas mais contextualmente relevantes. Esta abordagem garante que os LLMs gerem respostas informadas pelos dados mais recentes e pertinentes.
A eficácia do RAG depende muito da qualidade e organização da base de conhecimento, bem como da precisão dos algoritmos de recuperação. Enquanto o FACTS Grounding avalia a capacidade de um LLM de permanecer ancorado em um documento de contexto fornecido, o RAG complementa isso, permitindo que os LLMs ampliem seu conhecimento de forma dinâmica, recorrendo a fontes externas para aumentar a factualidade e a relevância.
Destilação de Conhecimento
A destilação de conhecimento envolve a transferência das capacidades de um modelo grande e complexo (referido como o professor) para um modelo menor e específico para uma tarefa (o aluno). Este método melhora a eficiência, mantendo grande parte da precisão do modelo original. Duas abordagens principais são usadas na destilação de conhecimento:
Destilação de conhecimento baseada em respostas: concentra-se na replicação dos resultados do modelo do professor, garantindo que o modelo do aluno produza resultados semelhantes para determinadas entradas.
Destilação de conhecimento baseada em recursos: extrai representações e recursos internos do modelo do professor, permitindo que o modelo do aluno replique insights mais profundos.
Refinando modelos menores , a destilação de conhecimento permite a implantação de LLMs em ambientes com recursos limitados sem perdas significativas de desempenho. Ao contrário do FACTS Grounding, que avalia a fidelidade do aterramento, a destilação de conhecimento está mais preocupada em dimensionar os recursos do LLM e otimizá-los para tarefas específicas.
Ajuste fino com conjuntos de dados fundamentados
O ajuste fino envolve a adaptação pré-treinada LLMs para domínios ou tarefas específicas, treinando-os em conjuntos de dados selecionados onde a fundamentação factual é crítica. Por exemplo, conjuntos de dados que compreendem literatura científica ou registos históricos podem ser utilizados para melhorar a capacidade do modelo de produzir resultados precisos e específicos de domínio. Essa técnica melhora o desempenho do LLM para aplicações especializadas, como análise de documentos médicos ou jurídicos.
No entanto, o ajuste fino consome muitos recursos e corre o risco de esquecimento catastrófico, onde o modelo perde o conhecimento adquirido durante seu treinamento inicial. FACTS Grounding se concentra em testar a factualidade em contextos isolados, enquanto o ajuste fino busca melhorar o desempenho básico dos LLMs em áreas específicas.
Aprendizagem por Reforço com Feedback Humano (RLHF)
Aprendizagem por Reforço com Feedback Humano (RLHF) incorpora preferências humanas no processo de treinamento de LLMs. Ao treinar iterativamente o modelo para alinhar as suas respostas com o feedback humano, o RLHF refina a qualidade, factualidade e utilidade dos resultados. Os avaliadores humanos pontuam os resultados do LLM, e essas pontuações são usadas como sinais para otimizar o modelo.
O RLHF tem sido particularmente bem-sucedido em aumentar a satisfação do usuário e garantir que as respostas geradas estejam alinhadas com as expectativas humanas. Enquanto o FACTS Grounding avalia a fundamentação factual em relação a documentos específicos, o RLHF enfatiza o alinhamento dos resultados do LLM com os valores e preferências humanas.
Seguimento de instruções e aprendizagem no contexto
O seguimento de instruções e a aprendizagem no contexto envolvem a demonstração de fundamentação para LLMs por meio de exemplos cuidadosamente elaborados no prompt do usuário. Esses métodos dependem da capacidade do modelo de generalizar a partir de uma demonstração de algumas cenas. Embora essa abordagem possa gerar melhorias rápidas, ela pode não atingir o mesmo nível de qualidade de base que os métodos de ajuste fino ou baseados em recuperação.
Ferramentas externas e APIs
Os LLMs podem ser integrados com ferramentas externas e APIs para fornecer acesso em tempo real a dados externos, melhorando significativamente suas capacidades de aterramento. Os exemplos incluem:
Capacidade de navegação: permite que os LLMs acessem e recuperem informações em tempo real da Web para responder perguntas específicas ou atualizar seus conhecimentos.
Chamadas de API: permitem que os LLMs interajam com bancos de dados ou serviços estruturados, enriquecendo as respostas com informações precisas e atualizadas.
Essas ferramentas expandem a utilidade dos LLMs, conectando-os a dados reais.-fontes de conhecimento mundial, melhorando sua capacidade para gerar saídas precisas e fundamentadas. Embora o FACTS Grounding avalie a fidelidade do aterramento interno, as ferramentas externas fornecem um meio alternativo de estender e verificar a factualidade.
Aterramento do modelo de código aberto Opções
Várias implementações de código aberto estão disponíveis para os métodos alternativos de aterramento discutidos acima:
Implicações para aplicações de alto risco
A importância de respostas de IA precisas e fundamentadas torna-se particularmente evidente em aplicações de alto risco, como diagnósticos médicos, revisões jurídicas e análises financeiras. Nestes contextos, mesmo pequenas imprecisões podem levar a consequências significativas, tornando a fiabilidade dos resultados gerados pela IA um requisito inegociável.
FACTOS A ênfase da Grounding na factualidade e na adesão ao material de origem garante que os modelos sejam testados sob condições que refletem de perto as demandas do mundo real.
Por exemplo, em contextos médicos, um LLM encarregado de resumir os registros dos pacientes deve evitar a introdução de erros que possam desinformar as decisões de tratamento. Da mesma forma, em contextos jurídicos, a produção de resumos ou análises de jurisprudência exige uma fundamentação precisa nos documentos fornecidos.
FATOS O Grounding não apenas avalia os modelos quanto à sua capacidade de atender a esses requisitos rigorosos, mas também estabelece uma referência para os desenvolvedores buscarem na criação de sistemas adequados para tais aplicações.
Expansão o conjunto de dados FACTS e direções futuras
A DeepMind posicionou o FACTS Grounding como uma “referência viva”, que evoluirá junto com os avanços na IA. incluir novos domínios e tipos de tarefas, garantindo a sua relevância contínua à medida que as capacidades de LLM crescem.
Além disso, a introdução de modelos de avaliação mais diversos poderia melhorar ainda mais a robustez do processo de pontuação, abordando casos extremos e reduzindo preconceitos residuais.
Como reconhece a equipe de pesquisa da DeepMind, nenhum benchmark pode encapsular totalmente as complexidades das aplicações do mundo real. No entanto, ao iterar no FACTS Grounding e envolver a comunidade mais ampla de IA, o projeto visa elevar o padrão. factualidade e fundamentação em sistemas de IA.
Como afirma a equipe da DeepMind: “A factualidade e a fundamentação estão entre os principais fatores que moldarão o sucesso futuro e a utilidade dos LLMs e dos sistemas de IA mais amplos, e nosso objetivo é crescer e iterar o FACTS Grounding à medida que o campo avança, elevando continuamente a fasquia.”