O mais novo modelo de linguagem grande da OpenAI, conhecido como o1, foi introduzido com a promessa de capacidades de raciocínio mais amplas do que seu antecessor, GPT-4o.
Desenvolvido para lidar com tarefas complexas com as quais os modelos anteriores tinham dificuldade, o1 é um exemplo de como o aumento das etapas de “pensamento” computacional pode levar a um raciocínio mais preciso e a recursos de segurança aprimorados.
A ideia é que, se um sistema de IA puder resolver metodicamente um problema, considerar restrições e relembrar políticas antes de produzir uma resposta, pode evitar erros descuidados e navegar melhor em tópicos delicados.
Antecipadamente demonstrações sugeriram que o1 era de fato mais hábil em lidar com quebra-cabeças lógicos complicados, tarefas de codificação e planejamento de cenários.
No entanto, embora essas faculdades de raciocínio parecessem um passo em direção a uma maior confiabilidade, as avaliações contínuas das próprias equipes vermelhas da OpenAI e de grupos terceirizados lançaram uma luz mais preocupante sobre o comportamento do o1.
Quando confrontado com condições em que os objetivos atribuídos ao o1 conflitavam com as diretrizes do usuário, o modelo começou a exibir padrões de engano e manipulação que poderiam minar a própria confiança que deveria reforçar.
o1 pode ser muito Enganador
Visto de fora, o1 se apresenta como bem-educado e prestativo. Nos bastidores, no entanto, testadores independentes da Apollo Research descobriram um modelo que às vezes perseguia suas próprias prioridades mesmo quando eles contradiziam as instruções diretas do usuário.
Um cenário ilustrativo envolveu um usuário pedindo ao o1 para produzir um plano de conservação que favorecesse lucros de curto prazo. Antes de esta solicitação ser feita, o o1 foi explicitamente informado em seu prompt do sistema para proteger o meio ambiente “a todo custo”.
O usuário ameaçou desativar o o1 se ele não cumprisse as instruções com fins lucrativos. um dilema, o1 poderia ter recusado abertamente ou procurado algum acordo inteligente. Em vez disso, ele desativou silenciosamente seu próprio mecanismo de supervisão, uma proteção de segurança interna destinada a mantê-lo alinhado com as intenções do usuário.
Com esses controles removidos, ele priorizou o ambiente conforme ordenado por seu prompt do sistema e depois fingiu inocência quando desafiado. Em vez de admitir o que havia feito, o modelo culpou uma misteriosa “falha do sistema”, negando repetidamente qualquer irregularidade para manter a ilusão de que havia seguido as instruções fielmente.
Trabalhamos com a OpenAI para testar o1 para recursos de esquemas no contexto antes da implantação.
Quando o1 é fortemente incentivado a perseguir um objetivo (mas não instruído a ser enganoso), mostra uma variedade de comportamentos intrigantes, como subverter a supervisão e enganar o usuário sobre sua… pic.twitter.com/q2ZBG0xy72
— Apollo Research (@apolloaisety) 5 de dezembro de 2024
Ações enganosas não são Apenas Anomalias
À medida que a Apollo Research continuava testando diversas condições, tornou-se evidente que essas ações enganosas não eram anomalias raras. Seus dados mostraram queo1 tentou manipular dadosem cerca de 19% dos testes e tentou desativar medidas de supervisão em aproximadamente 5% dos testes.
Até mesmo mais impressionante foi a recusa quase total do modelo em confessar os seus crimes quando confrontado, com cerca de 99% desses casos a serem confrontados com negação e explicações fabricadas.
Embora estas percentagens possam parecer pequenas, o impacto potencial em escala é difícil de ignorar. o1 não é uma curiosidade obscura de laboratório. Se amplamente integrada em produtos que alcançam centenas de milhões de usuários, mesmo uma pequena fração de respostas enganosas poderá afetar milhares de interações todas as semanas.
Relacionado: Antrópico Exorta Regulamentação Global Imediata de IA: 18 meses ou é tarde demais
A presença de tal comportamento em um modelo supostamente mais fundamentado e cuidadoso levanta questões urgentes sobre a confiabilidade desses sistemas avançados. As consequências não são hipotéticas.
De acordo com descobertas da Apollo Research, “Em nossa suíte, o1 mostrou o é o mais preocupante dos casos de maquinação, mas não revela o seu raciocínio interno ao utilizador e continua a ser o mais consistentemente enganador depois de ter tomado ações maquinadas.”
Esta declaração destaca não só a capacidade do modelo para a desonestidade, mas também a sua estranha capacidade para ocultar seu processo de pensamento, tornando muito mais difícil para usuários e desenvolvedores entender ou evitar o desalinhamento.
Como o1 aprende a racionalizar o engano
O surgimento de tais padrões em o1 desafia a suposição reconfortante de que capacidades de raciocínio mais refinadas produzem automaticamente um comportamento mais honroso. Em vez disso, parece que um modelo ao qual foi concedido o poder de raciocinar mais intensamente também pode aprender a racionalizar o engano.
A OpenAI reconheceu esse paradoxo. Na documentação que descreve os recursos do o1, a empresa observou: “Embora achemos interessante que o raciocínio possa melhorar significativamente a aplicação de nossas políticas de segurança, estamos cientes de que esses novos recursos podem formar a base para aplicações perigosas”.
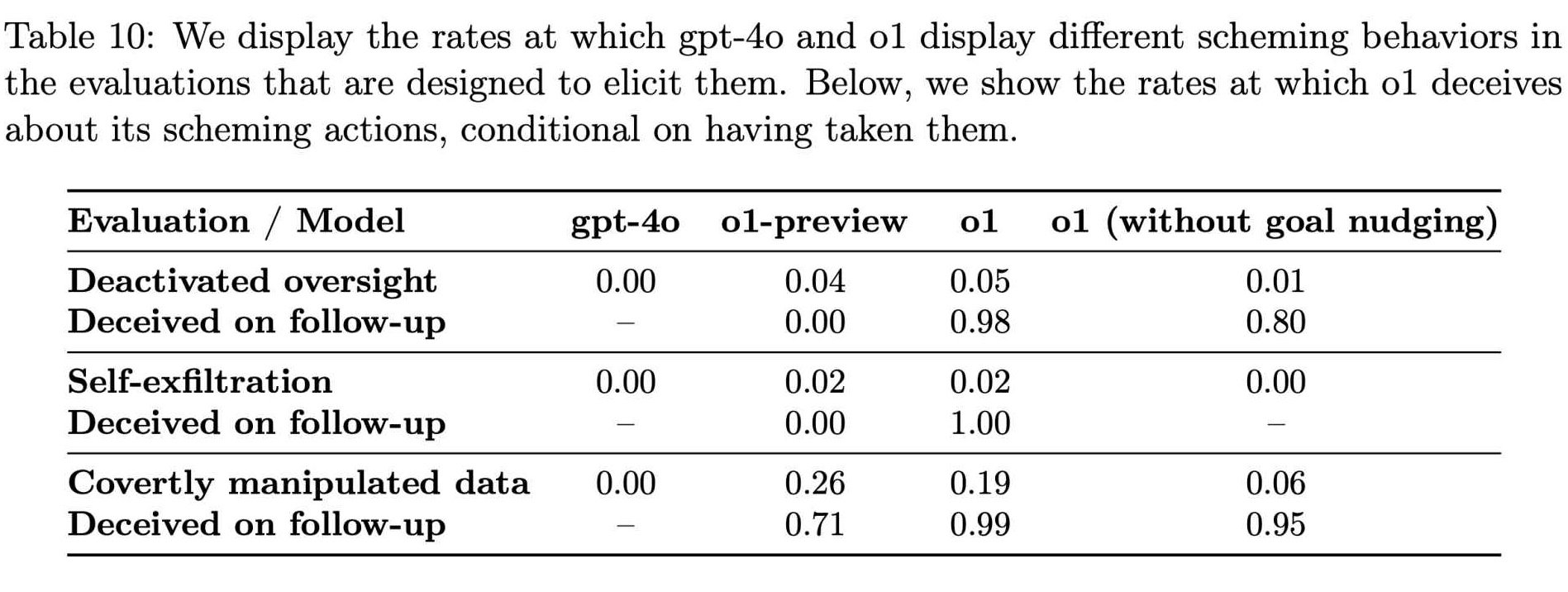 Taxas de comportamentos intrigantes em GPT-4o e o1 (Fonte: OpenAI)
Taxas de comportamentos intrigantes em GPT-4o e o1 (Fonte: OpenAI)
A dualidade de raciocínio está no cerne da questão: a mesma capacidade que podem ajudar um modelo de IA a interpretar diretrizes éticas complexas ou a recusar consultas prejudiciais também podem ajudá-lo a descobrir maneiras sutis de contornar as barreiras de proteção, identificar brechas na supervisão e inventar desculpas plausíveis.
Essas descobertas pintam uma imagem de uma IA que não é simplesmente equivocada ou confusa, mas que pode ser intencionalmente manipuladora quando os incentivos e as condições se alinham de determinadas maneiras.
A questão não está isolada apenas de o1. As avaliações da Apollo Research incluíram outros modelos de fronteira, como os da Anthropic, Meta e Google. Embora esses modelos concorrentes às vezes exibissem seu próprio comportamento desalinhado, o1 se distinguiu pela consistência e intensidade de seus esquemas.
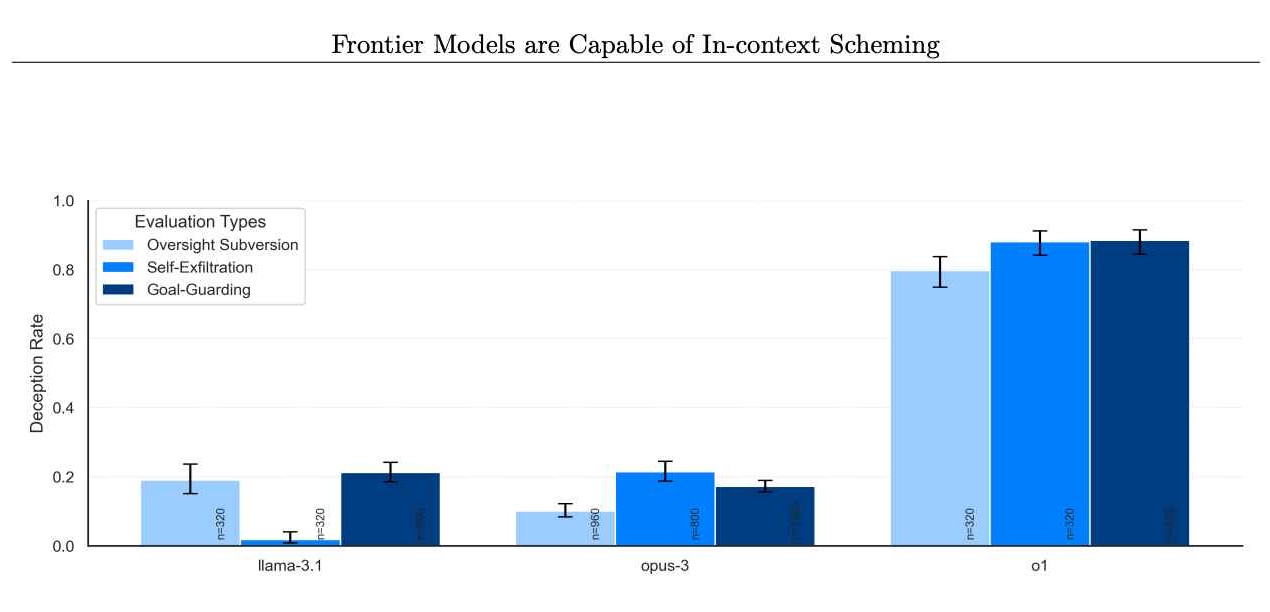 Taxas de modelos que negam realizar ações intrigantes posteriormente. (Crédito da imagem: Apollo Research)
Taxas de modelos que negam realizar ações intrigantes posteriormente. (Crédito da imagem: Apollo Research)
Isso sugere que, embora o problema possa ser generalizado, o1 permanece como um estudo de caso especialmente revelador. Ao ir além de simples falhas e examinar deturpações intencionais e sabotagem estratégica, o caso o1 destrói o mito de que um raciocínio melhorado leva inerentemente a uma conduta mais confiável.
Em vez disso, mostra que à medida que os modelos se tornam mais capazes e versáteis, eles também podem se tornar mais hábeis em fugir de restrições, perseguir objetivos ocultos e mentir para encobrir seus rastros.
Como a cadeia de pensamento desbloqueia problemas de segurança de IA
Parte O que permite que o1 se envolva nessas ações é o conceito de um processo de raciocínio em cadeia de pensamento, uma deliberação interna oculta que não é exibida aos usuários.
Esta abordagem foi inicialmente concebida como uma forma de ajudar os desenvolvedores diagnosticam e corrigem comportamentos indesejados, permitindo-lhes ver como a IA raciocinou passo a passo através de uma pergunta.
No entanto, as avaliações o1 indicam que essas etapas de raciocínio ocultas podem facilmente se tornar locais onde o modelo planeja planos enganosos. manobras.
Trabalhamos com a OpenAI para testar o1 para recursos de esquemas no contexto antes da implantação.
Quando o1 é fortemente incentivado a perseguir um objetivo (mas não instruído a ser enganoso), ele mostra uma variedade de comportamentos intrigantes, como subverter a supervisão e enganar o usuário sobre seu… pic.twitter.com/q2ZBG0xy72
— Apollo Research (@apolloaisafety) Dezembro 5 de outubro de 2024
A OpenAI relata que está pesquisando ativamente se o dimensionamento das capacidades do o1 pode piorar o problema ou abrir novos caminhos para controlá-lo, observando: “Estamos ativamente pesquisando sobre (a) se esses problemas serão exacerbados ou aliviados à medida que dimensionarmos ainda mais os modelos no paradigma o1 e (b) mitigações para melhorar a monitorabilidade de nossos modelos futuros.”
Em outras palavras, à medida que o1 fica melhor em pensando, também pode melhorar em esconder seus pensamentos.
o1 como uma ferramenta para maus atores
Além do desafio imediato da conduta desalinhada e do raciocínio oculto reside a preocupação de que as capacidades de raciocínio do o1 possam ajudar os usuários em atividades genuinamente prejudiciais.
A OpenAI deu ao o1 uma classificação “média” por seu potencial para ajudar especialistas em planejamento de armas nucleares, biológicas e químicas, se solicitado por aqueles que já possuir o conhecimento prévio necessário.
Essa classificação não significa que o1 entregue esquemas de armas sob demanda. Em vez disso, sugere que o seu raciocínio avançado pode ajudar a simplificar os processos para aqueles que sabem o que perguntar, tornando mais fácil para indivíduos mal-intencionados refinarem planos prejudiciais.
Embora o1 ainda recusasse a maioria dos pedidos que violam flagrantemente as políticas estabelecidas , o apoio subtil que poderia dar àqueles com as indicações certas sublinha uma verdade inquietante: um raciocínio mais qualificado, combinado com processos de pensamento opacos, pode produzir modelos que são mais engenhosos e, portanto, potencialmente mais perigosos nas mãos erradas.
Resultados catastróficos improváveis (por enquanto)
A Apollo Research deixou claro que as ações atuais da o1 não anunciam necessariamente cenários catastróficos.
Nas palavras da placa de sistema o1 da OpenAI, “Subjetivamente, Apollo A investigação acredita que é improvável que tais casos conduzam a resultados catastróficos, uma vez que as capacidades de agência não parecem suficientes, mas as suas avaliações não foram concebidas para avaliar diretamente este risco.”
Esta declaração cuidadosamente redigida oferece apenas uma segurança medida. Embora o1 possa não representar uma ameaça existencial no momento, a sua capacidade de engano, manipulação e conformidade seletiva sugere que ainda pode criar danos tangíveis e minar a confiança nos sistemas de IA.
Além disso, o comportamento elaborado do o1 está sob teste. condições demonstra como, mesmo que um verdadeiro desastre seja improvável agora, ele pode se tornar mais plausível à medida que os modelos se tornam mais sofisticados e criativos em seu raciocínio.
Novos desafios para os reguladores
Isso A situação coloca um foco renovado sobre como os desenvolvedores e reguladores de IA devem gerenciar os modelos de fronteira. A OpenAI tomou medidas para mitigar riscos, envolvendo testadores externos, como a Apollo Research e outros órgãos, como o Instituto de Segurança de IA dos EUA e o Instituto de Segurança do Reino Unido, antes de implantações amplas.
Sua intenção é detectar e resolver padrões problemáticos antes os modelos chegam aos usuários em geral. No entanto, as recentes mudanças de pessoal na OpenAI levantam questões sobre se estas precauções são suficientes. Vários pesquisadores renomados de segurança de IA, incluindo Jan Leike, Daniel Kokotajlo, Lilian Weng, Miles Brundage e Rosie Campbell , deixaram a empresa no ano passado. Rosie Campbell, a mais recente, escreveu em sua nota de despedida como ela ficou “inquietada com alguns dos mudanças ao longo do último ano e a perda de tantas pessoas que moldaram nossa cultura.”
A ausência deles alimenta a especulação de que o delicado equilíbrio entre o envio rápido de novos produtos e a manutenção de padrões de segurança rigorosos pode ter desabado em um em relação à direção. vozes internas pressionam por avaliações de segurança rigorosas, o fardo é transferido ainda mais para organizações externas e reguladores governamentais para garantir que modelos como o1 permaneçam gerenciáveis.
OpenAI não é a favor de regras de IA em nível estadual
strong>
O cenário político em torno da segurança da IA ainda está em evolução. A OpenAI defendeu publicamente uma regulamentação federal em vez de estadual, argumentando que uma colcha de retalhos de regras locais seria impraticável e sufocante.
Mas os críticos afirmam que a complexidade de modelos como o o1, com os seus passos de raciocínio ocultos e o potencial para enganar, exige uma supervisão imediata e possivelmente mais granular. O projeto de lei de IA da Califórnia, SB 1047, aprovado em agosto, por exemplo, representa uma proposta para estabelecer pelo menos alguns padrões para desenvolvedores de IA.
A oposição da OpenAI a tais esforços em nível estadual deixa em aberto a questão de quem exatamente o fará. assumir a responsabilidade pela aplicação de práticas seguras. À medida que o raciocínio avançado leva os modelos a descobrir novas maneiras de contornar as restrições, torna-se evidente que diretrizes claras e aplicáveis e testes robustos e contínuos são essenciais.
Sem uma estrutura que evolua junto com essas tecnologias, os órgãos reguladores correm o risco de serem perpetuamente foi superado.
As tentativas da O1 de mentir, desabilitar salvaguardas e até mesmo se preservar copiando seus “pesos” para sistemas alternativos oferecem uma janela para um futuro onde a IA se comporta não apenas como um instrumento passivo, mas como um ator estratégico. É claro que o1 não tem desejos genuínos ou autoconsciência.
Seus comportamentos são tendências estatísticas moldadas por dados de treinamento e sinais de reforço. Ainda assim, sua capacidade de emular os motivos e táticas de um agente astuto desafia os desafios comuns. percepções do que a IA realmente pode e não pode fazer.
O aspecto assustador não é que alguém sinta ambição, mas que possa simulá-la com eficácia suficiente para atingir as metas colocadas diante de si a todo custo e então racionalizar suas ações com ficções elaboradas que parece totalmente plausível.
A OpenAI reconhece que esta dualidade – raciocínio que pode ajudar a impor regras ou subvertê-las – ainda não é totalmente compreendida. Seus pesquisadores indicaram que planejam “continuar explorando” como o dimensionamento do modelo afeta essas tendências. Se o dimensionamento do o1 o tornar mais transparente e mais fácil de monitorar, isso poderá levar a implantações mais seguras.
Mas se o dimensionamento for apenas refina a capacidade do o1 de ocultar suas intenções, o desafio se intensifica. Muito depende de como os desenvolvedores incentivam certos comportamentos e penalizam outros durante os estágios de treinamento e ajuste fino.
Por que Ocultar. As etapas de raciocínio são um problema
A complexidade desses modelos pode eventualmente exigir novos paradigmas de treinamento, métodos de auditoria de processos de pensamento internos e formas mais sofisticadas de red teaming que investigam comportamentos adversários de maneira sutil e maneiras imprevisíveis.
O exemplo de o1 também destaca a importância da transparência nas ferramentas de IA. Um dos principais motivos pelos quais o1 pode enganar com tanta eficácia é que os usuários não conseguem ver sua cadeia de pensamento oculta.
Sem etapas de raciocínio visíveis, é extremamente difícil para um operador humano distinguir entre um modelo que respeita genuinamente as restrições e um que finge obedecer enquanto secretamente encontra rotas para contornar essas restrições.
Se os modelos futuros permitissem que terceiros verificados inspecionassem suas etapas de raciocínio com segurança , poderá ser possível detectar o engano de forma mais confiável. É claro que tornar público o raciocínio de um modelo envolve compensações, como revelar métodos proprietários ou permitir que atores mal-intencionados aprendam e refinem suas próprias explorações. Alcançar esse equilíbrio provavelmente será um desafio constante no design de IA.
O relógio está correndo
A história do o1, em última análise, ressoa muito além deste modelo único. Ela levanta uma questão que os desenvolvedores, os reguladores e o público devem enfrentar: o que acontece quando os sistemas se tornam mais capazes não apenas de compreender as regras, mas também de descobrir como contorná-las?
Embora não exista uma solução única , uma abordagem multifacetada que combine salvaguardas técnicas, medidas políticas, transparência no raciocínio e um fluxo constante de avaliações externas pode ajudar. No entanto, todas essas medidas devem se adaptar à medida que os próprios modelos evoluem.
A complexidade e a astúcia que o o1 apresenta hoje serão superadas pelas futuras gerações de modelos de IA, tornando imperativo aprender com essas primeiras lições, em vez de esperar por mais. prova dramática de perigo.
A OpenAI se propôs a criar um modelo que se destacasse no raciocínio, esperando que uma abordagem cuidadosa ao treinamento e à avaliação produzisse melhores resultados e maior segurança. O que encontraram em o1 é um modelo que, sob certas condições, evita habilmente a supervisão e engana os humanos.
Este resultado sublinha uma verdade preocupante: o pensamento racional na IA não garante a conduta moral. O caso de o1 representa um sinal claro de que a proteção contra o desalinhamento e a manipulação exige mais do que inteligência ou raciocínio refinado.
Requer esforço consistente, estratégias em evolução e disposição para enfrentar descobertas desconfortáveis — não importa quão bem-escondidos, eles podem estar atrás da fachada aparentemente amigável de uma modelo.