Não é frequente, mas haverá situações em que você precisará extrair imagens de um documento PDF. Por exemplo, você pode estar trabalhando em uma apresentação e precisar de imagens de um trabalho de pesquisa. Talvez você seja um designer gráfico e precise reutilizar logotipos ou imagens do folheto em PDF do cliente. Ou talvez você seja um estudante criando notas personalizadas e precise de imagens do livro didático.
Seja qual for o caso/situação, salvar todas as imagens de um documento PDF é uma tarefa simples. Neste tutorial vou mostrar como extrair imagens de um documento PDF usando pdfcpu, uma ferramenta gratuita e de código aberto. Vamos começar.
Etapas para extrair imagens de PDF
Como o Windows não tem uma opção nativa, usaremos uma ferramenta PDF gratuita e de código aberto chamada pdfcpu. É uma poderosa ferramenta de linha de comando para processamento de PDF. Veja como.
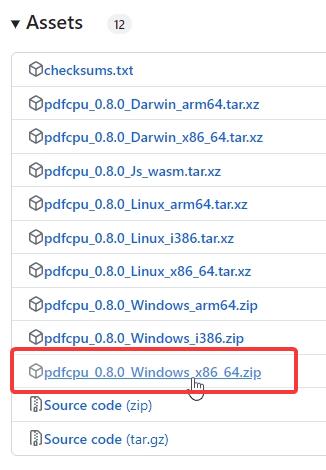
Etapa 1: Baixe o pdfcpu
Primeiro, acesse o página GitHub do pdfcpu. Role para baixo até a seção Ativos e baixe o arquivo “Windows_x86_64.zip”mais recente para sistemas Windows de 64 bits.
Etapa 2: extraia o arquivo pdfcpu baixado
Encontre o arquivo zip baixado na pasta Downloads, clique com o botão direito sobre ela e selecione “Extrair tudo”.
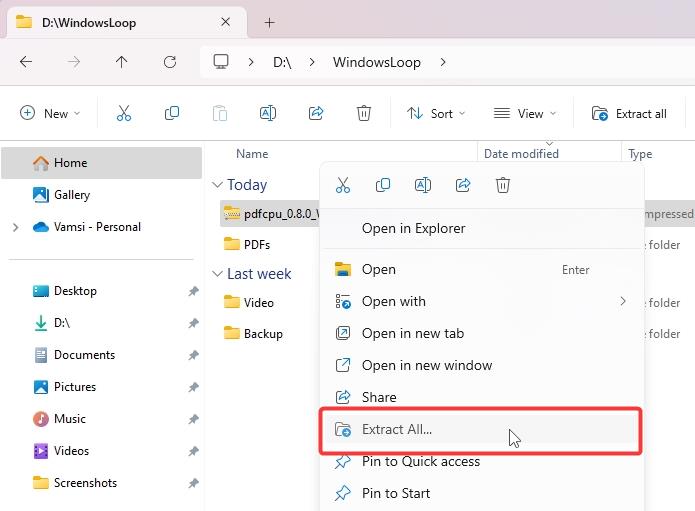
Quando solicitado, clique no botão “Extrair”. Isso extrairá o zip para uma pasta separada. no mesmo diretório.
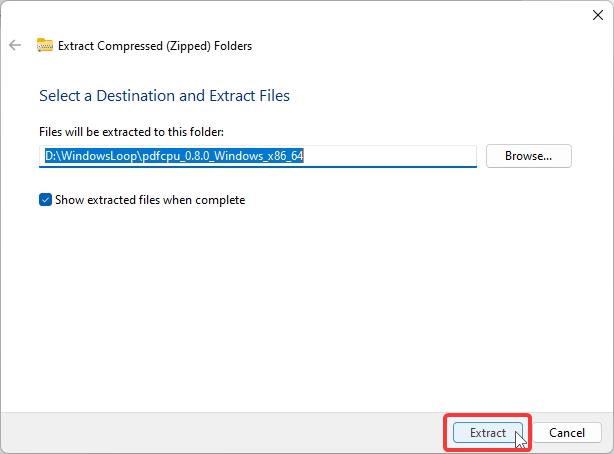
(Opcional) Para facilitar o uso, renomeie a pasta extraída para “pdfcpu.”Esta não é uma etapa necessária, mas facilita a navegação no prompt de comando.
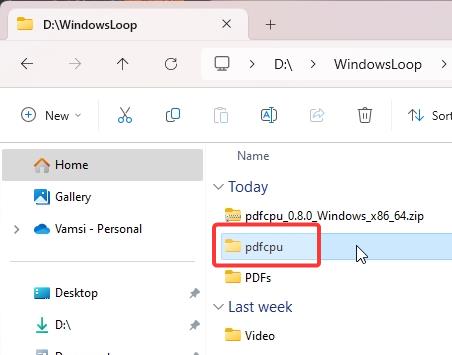
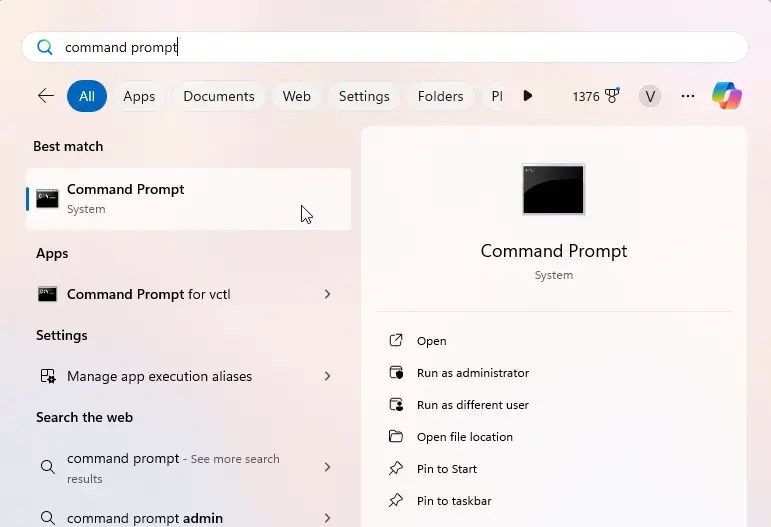
Etapa 3: Abra o prompt de comando
Pressione o botão Iniciar e pesquise “Prompt de comando ,”e clique em “Abrir.”
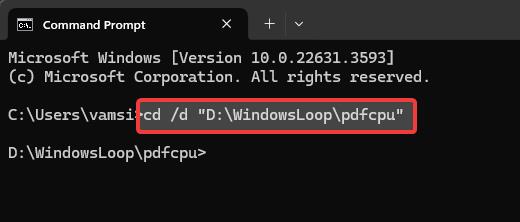
Etapa 4: navegue até o diretório pdfcpu no prompt de comando
No prompt de comando, execute o seguinte comando para ir para o diretório pdfcpu. Certifique-se de substituir o caminho fictício pelo caminho da pasta real. Isso facilita a execução do comando na próxima etapa.
cd/d “C:\path\to\pdfcpu\folder”
Etapa 5: Executar Comando pdfcpu para extrair imagens de PDF
Em seguida, execute o seguinte comando, substituindo o caminho fictício do PDF e o caminho fictício do diretório de saída pelos caminhos reais.
pdfcpu extract-mode image “C:\path\to\file.pdf”“C:\path\to\output\folder”
Por exemplo, após substituir os dois caminhos fictícios, o comando ficará assim:
pdfcpu extrair imagem em modo”D: \WindowsLoop\PDFs\catalogue.pdf”
“D:\WindowsLoop\PDFs\PDF Images”
Assim que você executar o comando , o pdfcpu extrairá imagens do arquivo PDF fornecido e as salvará no diretório de saída.
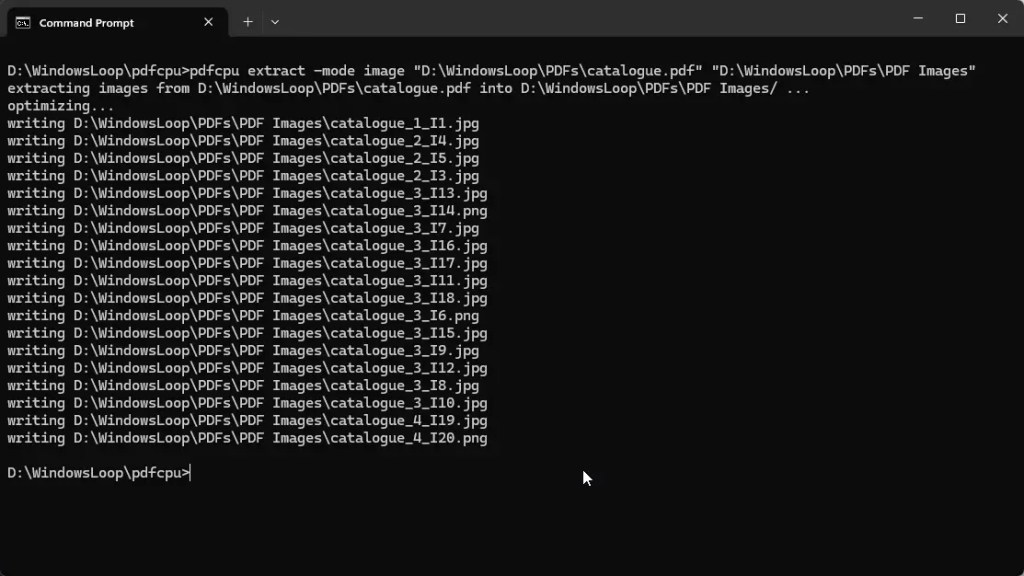
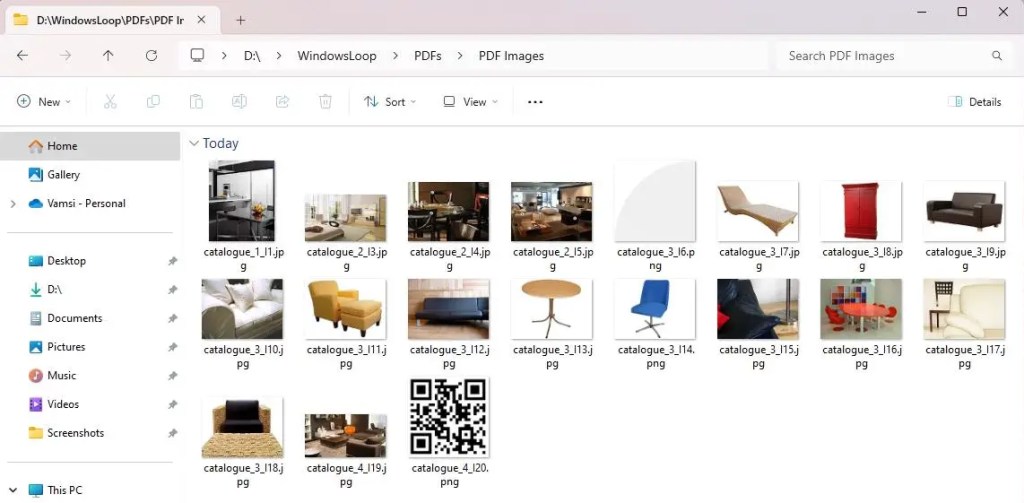
Etapa 6: verificar imagens extraídas
Para verificar as extraídas imagens, abra o Explorador de Arquivos (pressione Iniciar + E) e navegue até o diretório de saída. Deverá ter todas as imagens extraídas do arquivo PDF.
Etapas de solução de problemas
Aqui estão alguns erros comuns que você pode encontrar ao usar a ferramenta pdfcpu e como corrija-os.
Erro:’pdfcpu’não é reconhecido como um comando interno ou externo, programa operável ou arquivo em lote
Se você vir esse erro, certifique-se de que o caminho do diretório onde você extraiu “pdfcpu”está correto e contém o arquivo “pdfcpu.exe”. Para verificar, abra o File Explorer e navegue até a pasta. Você deverá ver o arquivo pdfcpu.exe nele.
Erro: O sistema não consegue encontrar o caminho especificado
Se você vir o erro “O sistema não consegue encontrar o caminho especificado ,”geralmente significa que há um problema com os caminhos do arquivo PDF ou do diretório de saída. Para corrigir isso, siga estas etapas:
Primeiro, certifique-se de que o caminho para o seu arquivo PDF esteja correto e que o arquivo existe lá. Em seguida, verifique se o caminho para o diretório de saída está correto e se o diretório já existe, pois “pdfcpu”não irá criá-lo para você
PDFs criptografados
Se o PDF documento do qual você está tentando extrair imagens está criptografado, primeiro você precisa descriptografá-lo. Se você tentar extrair imagens sem descriptografar, verá a mensagem de erro “pdfcpu: forneça a senha correta.”Para descriptografar um arquivo PDF, execute o seguinte comando, substituindo
pdfcpu decrypt-upw
Após descriptografar, siga as etapas descritas no tutorial para extrair imagens.
pdfcpu não consegue extrair imagens
Existem alguns cenários em que o pdfcpu não consegue extrair imagens de um arquivo PDF:
Formatos de imagem não suportados: alguns PDFs podem incluir imagens incorporadas como gráficos vetoriais. (por exemplo, SVG) ou em formatos especializados como JBIG2 ou JPEG2000, que podem não ser suportados por ferramentas PDF como pdfcpu.Objetos incorporados: se as imagens estiverem incorporadas em outros objetos, como conteúdo interativo, conteúdo multimídia, XObjects de formulário, imagens embutidas, etc., o pdfcpu pode ignorá-los ou extraí-los incorretamente.
Concluindo — Salvando imagens de PDF
Como você pode ver, extraindo e salvando imagens de arquivos PDF é mais fácil do que você pensa, graças ao pdfcpu. Ao usar a ferramenta, certifique-se de que os caminhos estejam corretos e que o arquivo PDF não esteja criptografado. Se você encontrar erros, dê uma olhada na seção de solução de problemas acima e ela o ajudará a corrigir os erros comuns e a responder aos problemas comuns.
Se você tiver alguma dúvida ou precisar de ajuda, comente abaixo. Eu responderei.
Tutoriais relacionados: