TL;DR
A essência: o Google Research revelou Titans, uma nova arquitetura neural que usa treinamento em tempo de teste para permitir que os modelos aprendam e memorizem dados em tempo real durante a inferência. Especificações principais: A arquitetura alcança recuperação efetiva em janelas de contexto superiores a 2 milhões de tokens, superando significativamente o GPT-4 no benchmark BABILong para tarefas de recuperação. Por que é importante: Titans resolve o esquecimento catastrófico das Redes Neurais Recorrentes (RNNs) e os custos quadráticos dos Transformadores, atualizando ativamente os parâmetros para minimizar a surpresa em novos dados. A compensação: embora computacionalmente mais pesado do que modelos de inferência estática como o IBM Granite, o Titans oferece expressividade superior para tarefas complexas, como descoberta legal ou análise genômica.
O Google Research revelou a”Titãs”, uma nova arquitetura neural que desafia a rigidez fundamental dos modelos atuais de IA, permitindo que eles”aprendam a memorizar”em tempo real durante a inferência.
Ao contrário dos Transformers tradicionais, que dependem de pesos estáticos ou Redes Neurais Recorrentes (RNNs) que usam decaimento de estado fixo, Titans emprega um módulo de “Memória Neural”. Este componente atualiza ativamente seus próprios parâmetros à medida que os dados são transmitidos, tratando efetivamente a janela de contexto como um loop de treinamento contínuo em vez de um buffer estático. janelas de contexto superiores a 2 milhões de tokens, a arquitetura supera significativamente o GPT-4 no benchmark BABILong. Este teste”Agulha no palheiro”desafia os modelos a recuperar pontos de dados específicos de documentos extensos, uma tarefa em que os modelos padrão muitas vezes falham.
Promoção
A mudança de paradigma da’memória neural’
As atuais arquiteturas de IA enfrentam uma compensação fundamental entre comprimento do contexto e eficiência computacional. Os transformadores, a arquitetura dominante por trás de modelos como GPT-4 e Claude, contam com um mecanismo de atenção que se adapta quadraticamente ao comprimento da sequência. Isso torna contextos extremamente longos computacionalmente proibitivos.
Por outro lado, RNNs lineares como o Mamba comprimem o contexto em um vetor de estado fixo. Embora isso permita comprimento infinito, muitas vezes resulta em “esquecimento catastrófico”, pois novos dados substituem informações antigas. O Titans apresenta um terceiro caminho: “Test-Time Training”(TTT).
Em vez de congelar os pesos do modelo após a fase inicial de treinamento, a arquitetura Titans permite que o módulo de memória continue aprendendo durante a inferência. Ao tratar a janela de contexto como um conjunto de dados, o modelo executa um loop de minigradiente descendente nos tokens recebidos. Isso atualiza seus parâmetros internos para representar melhor o documento específico que está processando.
Como explica a equipe de pesquisa do Google,”em vez de compactar informações em um estado estático, essa arquitetura aprende e atualiza ativamente seus próprios parâmetros como fluxos de dados.”
Por meio desse processo de aprendizado ativo, o modelo adapta sua estratégia de compactação dinamicamente, priorizando informações que são relevantes para a tarefa atual, em vez de aplicar uma função de decaimento de tamanho único.
Visão geral dos Titãs (MAC) arquitetura. Ele usa uma memória de longo prazo para compactar os dados anteriores e então incorporar o resumo ao contexto e passá-lo à atenção. A atenção pode então decidir se precisa ou não prestar atenção ao resumo do passado. (Fonte: Google)
Para gerenciar a sobrecarga computacional, Titans emprega uma “Métrica Surpresa” baseada no erro de gradiente. Ao processar um novo token, o modelo calcula a diferença entre sua previsão e a entrada real. Um erro alto indica “surpresa”, o que significa que a informação é nova e deve ser memorizada. Um erro baixo sugere que a informação é redundante ou já conhecida.
Usando um exemplo concreto, os pesquisadores observam que”se a nova palavra for’gato’e o estado de memória do modelo já espera uma palavra de animal, o gradiente (surpresa) é baixo. Ele pode pular a memorização com segurança.”
Essa memorização seletiva imita a eficiência biológica, permitindo que o sistema descarte dados de rotina enquanto retém anomalias críticas ou novos fatos.
Complementando esse aprendizado ativo. é um “mecanismo de esquecimento” adaptativo. Atuando como uma porta, esta função aplica redução de peso aos parâmetros de memória quando o contexto narrativo muda significativamente. Ao equilibrar a entrada de novos dados surpreendentes com a liberação controlada de informações obsoletas, o Titans mantém uma representação de alta fidelidade do contexto.
Isso evita que o modelo sucumba ao ruído que assola os modelos de estado fixo. O paradigma Nested Learning define a base teórica para esta abordagem:
“Nested Learning revela que um modelo complexo de ML é, na verdade, um conjunto de problemas de otimização coerentes e interconectados, aninhados uns nos outros ou executados em paralelo.”
“Cada um desses problemas internos tem seu próprio fluxo de contexto, seu próprio conjunto distinto de informações com as quais está tentando aprender.”
Essa base teórica postula que arquitetura e otimização são dois lados da mesma moeda. Ao visualizar o modelo como uma hierarquia de problemas de otimização, o Titans pode aproveitar a profundidade computacional em seu módulo de memória. Isso resolve o problema do “esquecimento catastrófico” que há muito limita a utilidade das redes recorrentes.
Extreme Context & Benchmarks
Mais notavelmente, esse sistema de memória ativa lida com janelas de contexto que quebram as arquiteturas tradicionais. Os benchmarks do Google mostram que Titans mantém recall efetivo em comprimentos de contexto superiores a 2.000.000 de tokens. Para efeito de comparação, os modelos de produção atuais como o GPT-4o são normalmente limitados a 128 mil tokens.
Nos desafiadores testes “Needle-in-a-Haystack” (NIAH), que medem a capacidade de um modelo de recuperar um fato específico enterrado em um grande volume de texto não relacionado, os Titãs demonstraram superioridade significativa sobre as linhas de base lineares da RNN. Na tarefa “Single Needle” com ruído sintético (S-NIAH-PK) com comprimento de token de 8k, a variante Titans MAC alcançou 98,8% de precisão, em comparação com apenas 31,0% para Mamba2.
O desempenho em dados de linguagem natural foi igualmente robusto. Na versão WikiText do teste (S-NIAH-W), Titans MAC obteve 88,2%, enquanto Mamba2 teve dificuldades com 4,2%. Esses resultados sugerem que, embora as RNNs lineares sejam eficientes, sua compactação de estado fixo perde fidelidade crítica ao lidar com dados complexos e barulhentos encontrados em documentos do mundo real.
Desempenho de referência: titãs versus linhas de base de última geração
Enfatizando recursos além da simples pesquisa por palavra-chave, a equipe de pesquisa do Google observa que “o modelo não está simplesmente fazendo anotações; está entendendo e sintetizando a história inteira”. Ao atualizar seus pesos para minimizar a surpresa de toda a sequência, o modelo constrói uma compreensão estrutural do arco narrativo. Isso permite recuperar informações com base em relacionamentos semânticos, em vez de apenas correspondência de token.
O Google fornece uma análise detalhada do recurso que define a arquitetura: seu módulo de memória. Ao contrário das redes neurais recorrentes tradicionais (RNNs), que normalmente são limitadas por um vetor de tamanho fixo ou memória matricial, essencialmente um contêiner estático que pode facilmente ficar superlotado ou barulhento à medida que os dados se acumulam, Titans introduz um novo módulo de memória neural de longo prazo.
Este módulo funciona como uma rede neural profunda por si só, utilizando especificamente um perceptron multicamadas (MLP). Ao estruturar a memória como uma rede que pode ser aprendida em vez de um armazenamento estático, o Titans alcança um poder expressivo significativamente maior. Essa mudança arquitetônica permite que o modelo ingira e resuma grandes volumes de informações dinamicamente.
Em vez de simplesmente truncar dados mais antigos ou compactá-los em um estado de baixa fidelidade para abrir espaço para novas entradas, o módulo de memória MLP sintetiza o contexto, garantindo que detalhes críticos e relacionamentos semânticos sejam preservados mesmo quando a janela de contexto se expande para milhões de tokens.
Além da precisão da recuperação, o Titans também se mostra promissor na eficiência geral da modelagem de linguagem. Na escala de 340 milhões de parâmetros, o varianbencht Titans MAC alcançou uma perplexidade de 25,43 no conjunto de dados WikiText. Esse desempenho supera tanto a linha de base do Transformer++ (31.52) quanto a arquitetura original do Mamba (30.83).
Isso indica que as atualizações de memória ativa fornecem uma melhor representação das distribuições de probabilidade da linguagem do que apenas os pesos estáticos. Ali Behrouz, pesquisador principal do projeto, destaca as implicações teóricas deste design, afirmando que “Os Titãs são capazes de resolver problemas além do TC0, o que significa que os Titãs são teoricamente mais expressivos que os Transformadores e a maioria dos modelos lineares recorrentes modernos em tarefas de rastreamento de estado.”
Eficiência: MIRAS versus Mercado
Para formalizar essas inovações arquitetônicas, o Google introduziu a estrutura MIRAS. Unificando várias abordagens de modelagem de sequência, incluindo Transformers, RNNs e Titans, o modelo opera sob a égide da “memória associativa”.
De acordo com o Google, a estrutura MIRAS desconstrói a modelagem de sequência em quatro opções fundamentais de design. A primeira é a Arquitetura de Memória, que dita a forma estrutural usada para armazenar informações, desde simples vetores e matrizes até os profundos perceptrons multicamadas encontrados em Titãs. Isso é combinado com o Viés de Atenção, um objetivo de aprendizagem interno que rege como o modelo prioriza os dados recebidos, decidindo efetivamente o que é significativo o suficiente para ser memorizado.
Para gerenciar a capacidade, a estrutura emprega um Portão de Retenção. O MIRAS reinterpreta os tradicionais “mecanismos de esquecimento” como formas específicas de regularização, garantindo um equilíbrio estável entre a aprendizagem de novos conceitos e a retenção do contexto histórico. Por fim, o Algoritmo de Memória determina as regras de otimização específicas usadas para atualizar o estado da memória, completando o ciclo de aprendizagem ativa.
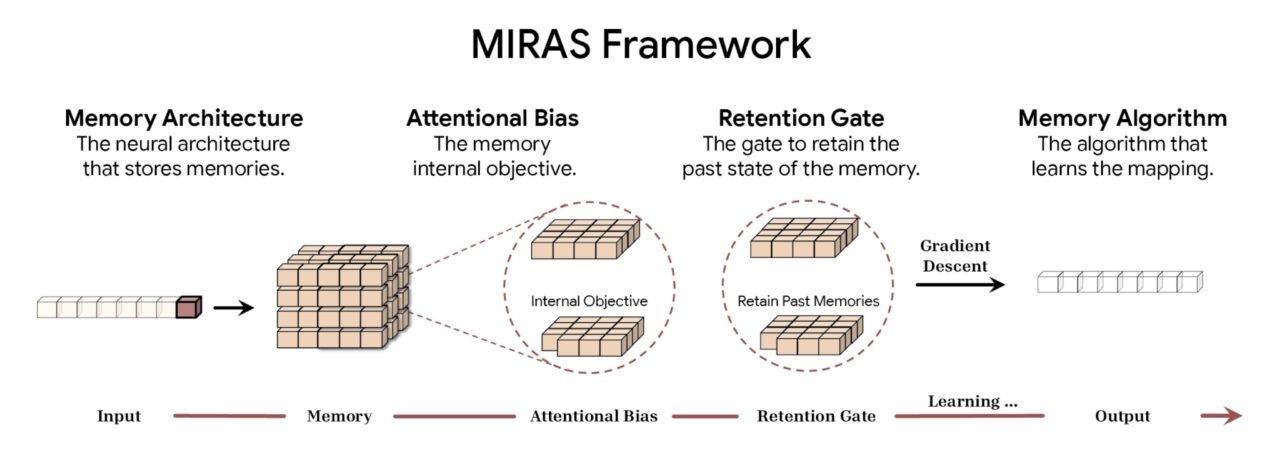 Visão geral da estrutura MIRAS (Fonte: Google)
Visão geral da estrutura MIRAS (Fonte: Google)
Decompondo a sequência modelando esses quatro componentes, o MIRAS desmistifica a “mágica” dos mecanismos de atenção. Ele os reclassifica como apenas um tipo de memória associativa com tendências específicas e configurações de retenção. Os pesquisadores podem, assim, misturar e combinar componentes, potencialmente levando a arquiteturas híbridas que combinam a precisão da atenção com a eficiência da recorrência.
Mudança de paradigma arquitetônico: a estrutura MIRAS
A memória dinâmica e de alta capacidade contrasta fortemente com a tendência predominante na Edge AI, onde o objetivo é frequentemente reduzir modelos estáticos para implantação local. Por exemplo, o lançamento do Granite 4.0 Nano pela IBM introduziu modelos tão pequenos quanto 350 milhões de parâmetros projetados para serem executados em laptops.
Enquanto a estratégia da IBM se concentra em tornar a inteligência estática onipresente e barata, a abordagem Titans do Google visa tornar o modelo em si mais inteligente e mais adaptável. Isso se aplica mesmo que exija a sobrecarga computacional de atualização de pesos durante a inferência.
A sobrecarga computacional, ou “lacuna de contexto”, continua sendo o principal obstáculo para os Titãs. Atualizar parâmetros de memória em tempo real é computacionalmente mais caro do que a inferência estática usada por modelos como Granite ou Llama. No entanto, para aplicações que exigem um conhecimento profundo de conjuntos de dados em grande escala, como descoberta legal, análise genômica ou refatoração de base de código, a capacidade de “aprender” o documento pode ser mais valiosa do que a velocidade de inferência bruta.
Servindo como a primeira implementação dessa visão automodificadora, a arquitetura “Hope” foi introduzida como uma prova de conceito no artigo de aprendizagem aninhada. À medida que a indústria continua a pressionar por contextos mais longos e raciocínios mais profundos, arquiteturas como as Titans, que confundem a linha entre treinamento e inferência, podem definir a próxima geração de modelos básicos.