A IA Mistral, a empresa francesa de inteligência artificial, introduziu Small 3, um modelo de linguagem de grande parâmetros de 24 bilhões de parâmetros (LLM) projetado como uma alternativa local de código aberto a modelos proprietários como o GPT-4o Mini do OpenAI.
A empresa está posicionando Small 3 como um modelo altamente eficiente otimizado para respostas rápidas e precisas, capaz de executar em um MacBook padrão com 32 GB de RAM, tornando-o acessível a uma ampla gama de usuários.
The Launch Chega em conjunto com o Instituto Allen para AI (AI2) lançando Tülu 3 405b , uma versão personalizada do Llama 3.1 da Meta, enfatizando a força contínua de avanços de código aberto no setor de IA do setor de IA. Os novos lançamentos chegam em um momento em que a IA Mistral confirmou planos para uma oferta pública inicial e está expandindo suas operações para a região da Ásia-Pacífico.
otimizado para a velocidade e a eficiência
A IA de Mistiplyehes e a foco e a foco e a acessibilidade. Ao contrário de muitos modelos maiores, o pequeno 3 tem menos camadas, o que reduz notavelmente o tempo de processamento. Esse design permite que ele seja executado em pé de igualdade com modelos como o LLAMA 3.3 70B da Meta e o QWEN 32B do Alibaba, mas com latência significativamente menor.
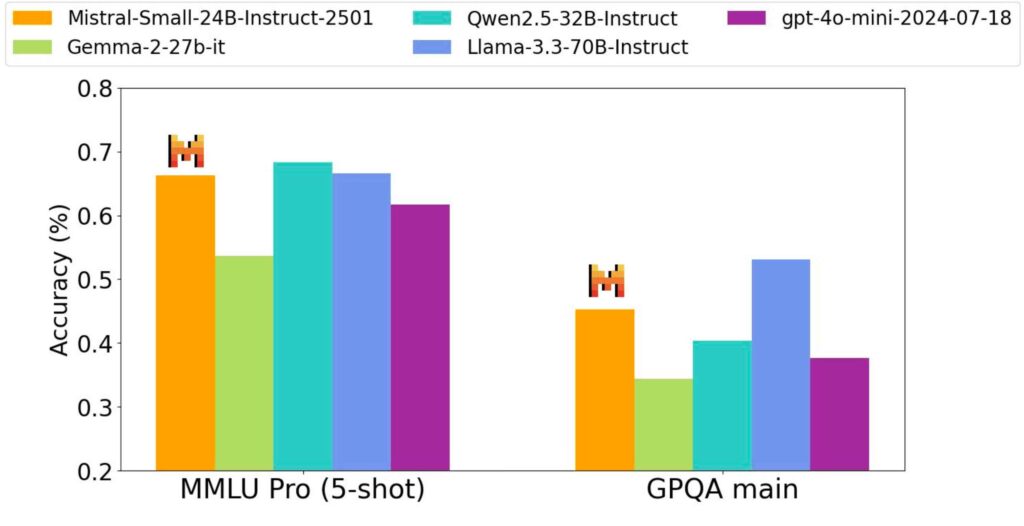
A IA Mistral relata que o pequeno 3 alcançou uma precisão de mais de 81% no benchmark MMLU, um teste para medir a precisão do modelo de linguagem em uma gama diversificada de assuntos, sem o uso do aprendizado de reforço ou dados sintéticos.
 Source: Mistral
Source: Mistral
This places the model earlier in its production stage, compared to models like DeepSeek R1, positioning it as a strong base for further customization and development of reasoning capabilities.
Performance Benchmarks
In internal assessments, Mistral Small 3 demonstrated an output quality that is comparable to larger models, such as Llama 3.3 70B, while achieving significantly faster response times.
Além disso, exibiu maior qualidade de saída e menor latência do que o GPT-4O Mini do OpenAI. Mistral relata que o modelo pode operar em um único RTX 4090 ou em um MacBook com 32 GB de RAM quando quantizado.
Quantization is a technique that reduces the precision of the numbers used in AI models, enabling them to run on devices with less computing power. This makes it ideal for hobbyists and organizations that require local inference while handling sensitive data.
The model’s capabilities position it for uses like fast-response conversational assistance, low-latency function execution, and fine-tuning for specific As áreas de assunto. P> Visualizações Mistral Small 3 como uma solução versátil para muitas tarefas generativas de IA que exigem instruções rápidas e confiáveis a seguir. Segundo Mistral, os clientes estão avaliando o modelo para diversas aplicações, como detecção de fraude em serviços financeiros, trincas de clientes em assistência médica e comando e controle no dispositivo em robótica e manufatura.
Pesquisadores Mistral declarados em blog post que, “Mistral Small 3 é um pré-trained and instructed model catered to the’80%’of generative AI tasks—those that require robust language and instruction following performance, with very low latency.” Its low latency makes it well-suited for automated workflows and AI agents that engage with Aplicações externas. Desenvolvimento de IA. processo de treinamento. de aprendizado de reforço que aprimora a capacidade do modelo para tarefas como resolver problemas de matemática. a indústria global de IA. CEO Arthur Mensch declarou em uma entrevista à Bloomberg ,”Não estamos à venda”, pois a empresa busca independência e crescimento global, pois confirmou planos para uma oferta pública inicial e está expandindo suas operações para a região da Ásia-Pacífico. Modelo de 14 bilhões de parâmetros conhecido por seu forte desempenho em tarefas de raciocínio. Raciocínio matemático./4v_cjx8svem? Si