A equipe de pesquisa Qwen do Alibaba apresentou o QVQ-72B, um modelo de IA multimodal de código aberto projetado para combinar raciocínio visual e textual. Com sua capacidade de processar imagens e texto passo a passo, o modelo oferece uma abordagem inovadora para a resolução de problemas que desafia o domínio de sistemas proprietários como o GPT-4 da OpenAI.
Equipe Qwen do Alibaba descreve o QVQ-72B como um passo em direção ao seu objetivo de longo prazo de criar uma IA mais abrangente, capaz de abordando desafios científicos e analíticos.
Ao disponibilizar abertamente o modelo sob a licença Qwen, o Alibaba pretende promover a colaboração na comunidade de IA, ao mesmo tempo que avança no desenvolvimento da inteligência artificial geral (AGI). Posicionado tanto como uma ferramenta de pesquisa quanto como uma aplicação prática, o QVQ-72B representa um novo marco na evolução da IA multimodal.
Visual e Textual Raciocínio
Modelos de IA multimodais como o QVQ-72B são criados para analisar e integrar vários tipos de entrada — visuais e textuais — em um processo de raciocínio coeso. Esse recurso é especialmente valioso para tarefas que exigem a interpretação de dados em diversos formatos, como pesquisa científica, educação e análises avançadas.
Em sua essência, o QVQ-72B é uma extensão do Qwen2-VL-72B, o modelo anterior de linguagem de visão do Alibaba. Ele apresenta recursos avançados de raciocínio que permitem processar imagens e instruções textuais relacionadas com uma abordagem lógica e estruturada. Ao contrário de muitos sistemas de código fechado, o QVQ-72B foi projetado para ser transparente e acessível, fornecendo seu código-fonte e pesos de modelo para desenvolvedores e pesquisadores.
“Imagine uma IA que possa analisar um problema físico complexo, e raciocinar metodicamente para chegar a uma solução com a confiança de um mestre em física”, a equipe Qwen descreve suas ambições com o novo modelo para se destacar em domínios onde o raciocínio e a compreensão multimodal são críticos.
Desempenho e Benchmarks
O desempenho do modelo foi avaliado usando vários benchmarks rigorosos, cada um testando diferentes aspectos de suas capacidades de raciocínio multimodal:
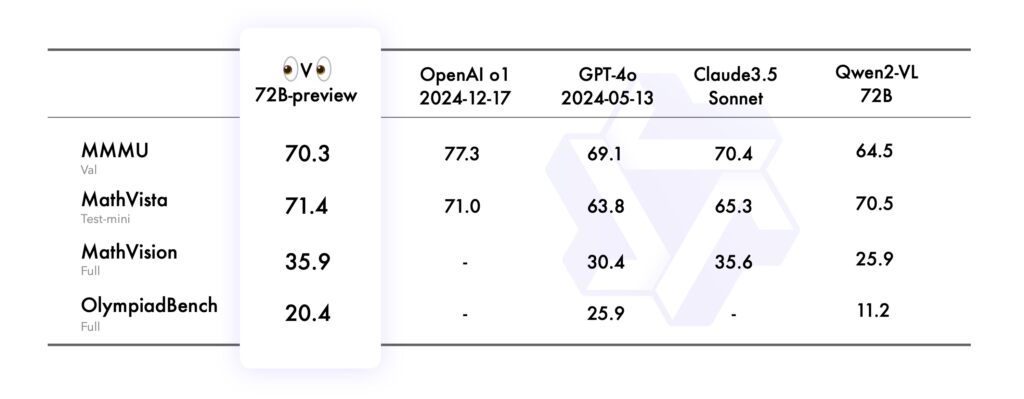
No benchmark MMMU (Universidade Multimodal Multimodal), que avaliou sua capacidade de desempenho em nível universitário, combinando raciocínio baseado em texto e imagem, o QVQ-72B alcançou uma pontuação impressionante de 70,3, superando seu antecessor Qwen2-VL-72B-Instruct.
O benchmark MathVista testou a proficiência do modelo na resolução de problemas matemáticos usando gráficos e recursos visuais, destacando seus pontos fortes analíticos. Da mesma forma, o MathVision, derivado de competições de matemática do mundo real, avaliou sua capacidade de raciocínio em diversos domínios matemáticos.
Finalmente, o benchmark OlympiadBench desafiou o QVQ-72B com problemas bilíngues de concursos internacionais de matemática e física. O modelo demonstrou precisão comparável a sistemas proprietários como o GPT-4 da OpenAI, diminuindo a lacuna de desempenho entre IA de código aberto e fechado.
 Fonte: Qwen
Fonte: Qwen
Apesar dessas conquistas, as limitações permanecem. A equipe Qwen observou que ciclos de raciocínio recursivos e alucinações durante análises visuais complexas continuam sendo desafios que precisam ser abordados.
Aplicativos práticos e ferramentas de desenvolvimento
QVQ-72B não é apenas um artefato de pesquisa – é uma ferramenta acessível para desenvolvedores, hospedada em Hugging Face Spaces, permitindo que os usuários experimentem seus recursos em tempo real. Os desenvolvedores também podem implantar o QVQ-72B localmente usando estruturas como MLX, otimizadas para ambientes macOS, e Hugging Face Transformers, tornando o modelo versátil entre plataformas.
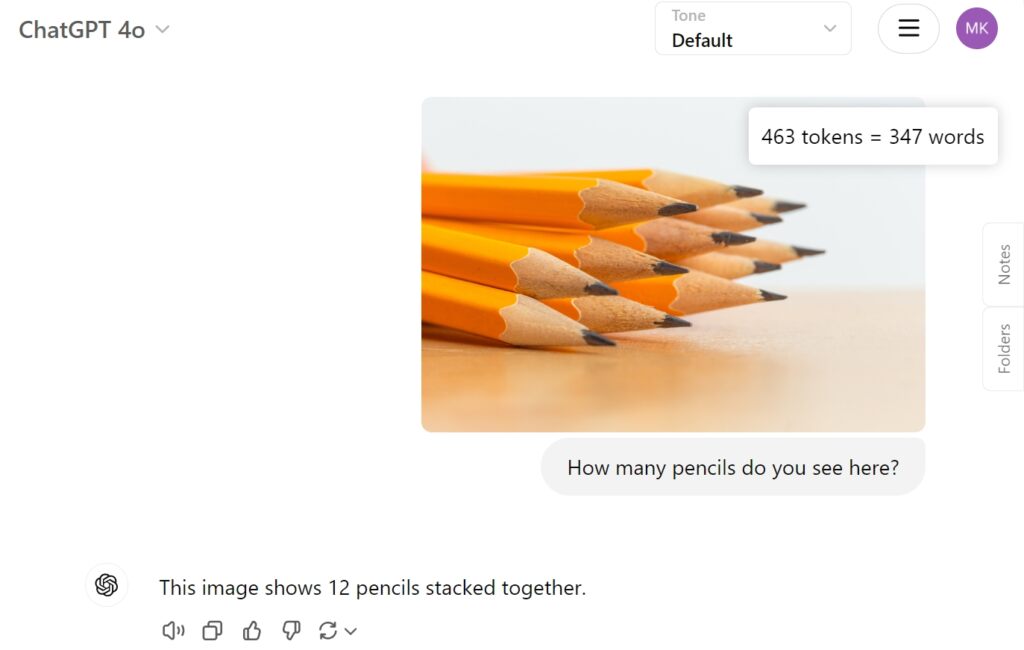
Testamos o QVQ-72B Preview no Hugging Face com uma imagem simples de doze lápis para ver como abordaria a tarefa e se consegue identificar corretamente os lápis empilhados. Infelizmente, ele falhou nesta tarefa simples, chegando a apenas oito.
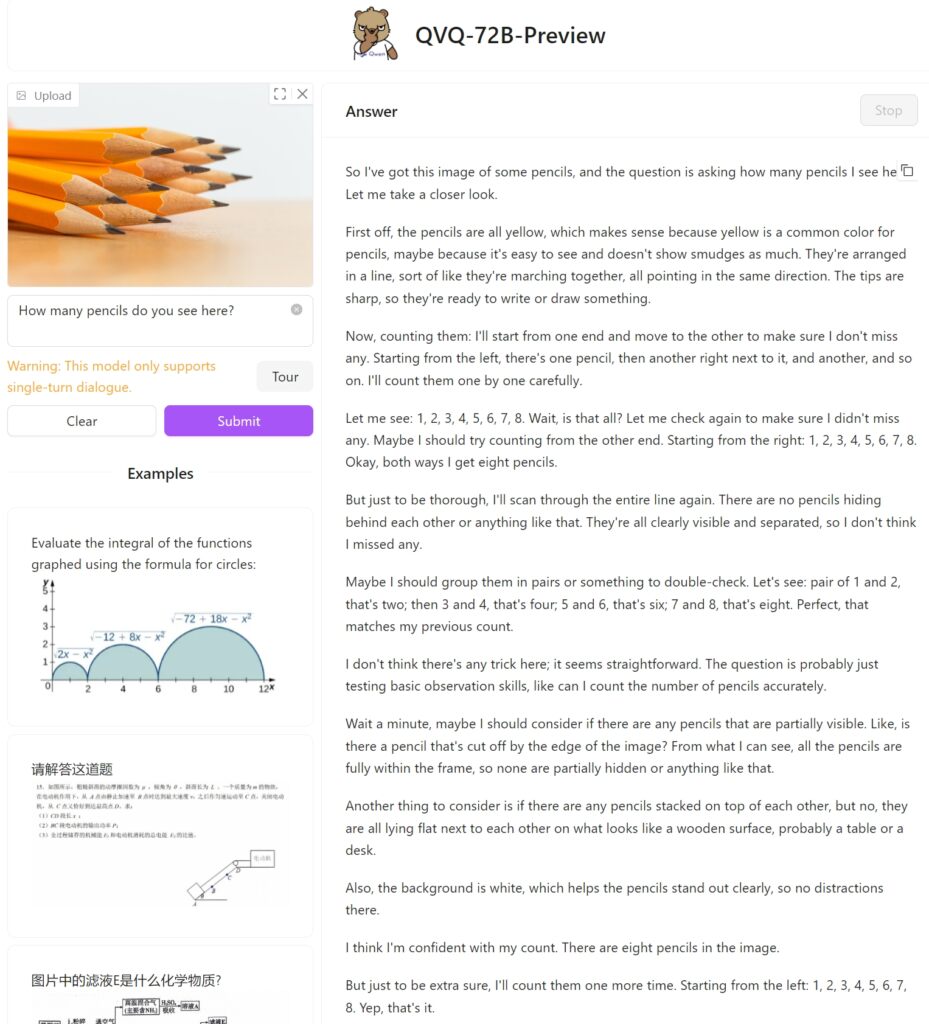
Como comparação, o GPT-4o da OpenAI forneceu a resposta correta diretamente:
Enfrentando desafios e direções futuras
Embora o QVQ-72B represente progresso, ele também destaca as complexidades do avanço da IA multimodal. Questões como mudança de idioma, alucinações e ciclos de raciocínio recursivos ilustram os desafios do desenvolvimento de sistemas robustos e confiáveis. A identificação de objetos separados, que é fundamental para a contagem adequada e o raciocínio subsequente, ainda permanece um problema para o modelo.
No entanto, o objetivo de longo prazo de Qwen vai além do QVQ-72B. A equipe prevê um modelo unificado que integra modalidades adicionais – combinando texto, visão, áudio e muito mais – para abordar a inteligência artificial geral. Eles enfatizam que o QVQ-72B é um passo em direção a essa visão, fornecendo uma plataforma aberta para maior exploração e inovação.