A DeepSeek AI lançou o DeepSeek-VL2, uma família de modelos de linguagem de visão (VLMs) que agora estão disponíveis sob licenças de código aberto. A série apresenta três variantes – Tiny, Small e o VL2 padrão – apresentando tamanhos de parâmetros ativados de 1,0 bilhão, 2,8 bilhões e 4,5 bilhões, respectivamente.
Os modelos podem ser acessados via GitHub e Rosto Abraçando. Eles prometem avançar nas principais aplicações de IA, incluindo resposta visual a perguntas (VQA), reconhecimento óptico de caracteres (OCR) e análise de documentos e gráficos de alta resolução.
De acordo com a documentação oficial do GitHub, “DeepSeek-VL2 demonstra capacidades superiores em diversas tarefas, incluindo, entre outras, resposta visual a perguntas, compreensão de documentos/tabelas/gráficos e fundamentação visual.”
O momento deste lançamento coloca a DeepSeek AI em competição direta com grandes players como OpenAI e Google, que dominam o domínio de IA de linguagem de visão com recursos proprietários modelos como GPT-4V e Gemini-Exp
Ênfase do DeepSeek em. a colaboração de código aberto, combinada com os recursos técnicos avançados da família VL2, posiciona-a como uma opção gratuita para pesquisadores.
Dynamic Tiling: Avanço no processamento de imagens de alta resolução
Um dos avanços mais notáveis no DeepSeek-VL2 é sua estratégia dinâmica de codificação de visão lado a lado, que revoluciona a forma como os modelos processam dados visuais de alta resolução.
Ao contrário do tradicional abordagens de resolução fixa, o ladrilho dinâmico divide as imagens em ladrilhos menores e flexíveis que se adaptam a várias proporções de aspecto. Este método garante a extração detalhada de recursos, mantendo a eficiência computacional.
Em seu repositório GitHub, o DeepSeek descreve isso como uma maneira de “processar eficientemente imagens de alta resolução com proporções variadas, evitando o dimensionamento computacional normalmente associado ao aumento da resolução da imagem”.
Esse recurso permite que o DeepSeek-VL2 se destaque em aplicações como aterramento visual, onde a alta precisão é essencial para identificar objetos em imagens complexas, e tarefas densas de OCR, que exigem processamento de texto em documentos ou gráficos detalhados. ajustando-se dinamicamente a diferentes resoluções de imagem e proporções de aspecto, os modelos superam as limitações dos métodos de codificação estática, tornando-os adequados para casos de uso que exigem flexibilidade e precisão.
Mistura de Especialistas e Multi-Atenção Latente Principal para Eficiência
Os ganhos de desempenho do DeepSeek-VL2 são ainda apoiados por sua integração da estrutura Mixture-of-Experts (MoE) e Mecanismo de atenção latente multicabeças (MLA).
A arquitetura MoE ativa seletivamente subconjuntos específicos, ou “especialistas”, dentro do modelo para lidar com tarefas com mais eficiência. Este design reduz a sobrecarga computacional ao envolver apenas os parâmetros necessários para cada operação, um recurso que é particularmente útil em ambientes com recursos limitados.
O mecanismo MLA complementa a estrutura do MoE comprimindo o cache de valores-chave em dados latentes. vetores durante a inferência. Essa otimização minimiza o uso de memória e aumenta a velocidade de processamento sem sacrificar a precisão do modelo.
De acordo com a documentação técnica, “A arquitetura MoE, combinada com MLA, permite que DeepSeek-VL2 alcance desempenho competitivo ou melhor do que modelos densos com menos parâmetros ativados.”
Pipeline de treinamento de três estágios
O desenvolvimento do DeepSeek-VL2 envolveu um pipeline de treinamento rigoroso de três estágios projetado para otimizar os recursos multimodais do modelo. O primeiro estágio focou na linguagem de visão. alinhamento, onde os modelos foram treinados para integrar recursos visuais com informações textuais
Isso foi conseguido usando conjuntos de dados como o ShareGPT4V, que fornece exemplos de imagem-texto emparelhados para o alinhamento inicial. que incorporou uma gama diversificada de conjuntos de dados, incluindo WIT, WikiHow e dados OCR multilíngues, para aprimorar as habilidades de generalização do modelo em vários domínios.
Finalmente, o terceiro estágio consistiu em supervisionado. ajuste fino (SFT), onde conjuntos de dados específicos de tarefas foram usados para refinar o desempenho do modelo em áreas como base visual, compreensão da interface gráfica do usuário (GUI) e legendas densas.
Esses estágios de treinamento permitiram que o DeepSeek-VL2 para construir uma base sólida para a compreensão multimodal, ao mesmo tempo que permite que os modelos se adaptem a tarefas especializadas. A incorporação de conjuntos de dados multilíngues melhorou ainda mais a aplicabilidade dos modelos em pesquisas globais e ambientes industriais.
Relacionado: Modelo chinês DeepSeek R1-Lite-Preview tem como alvo a liderança da OpenAI em raciocínio automatizado
Resultados de benchmarking
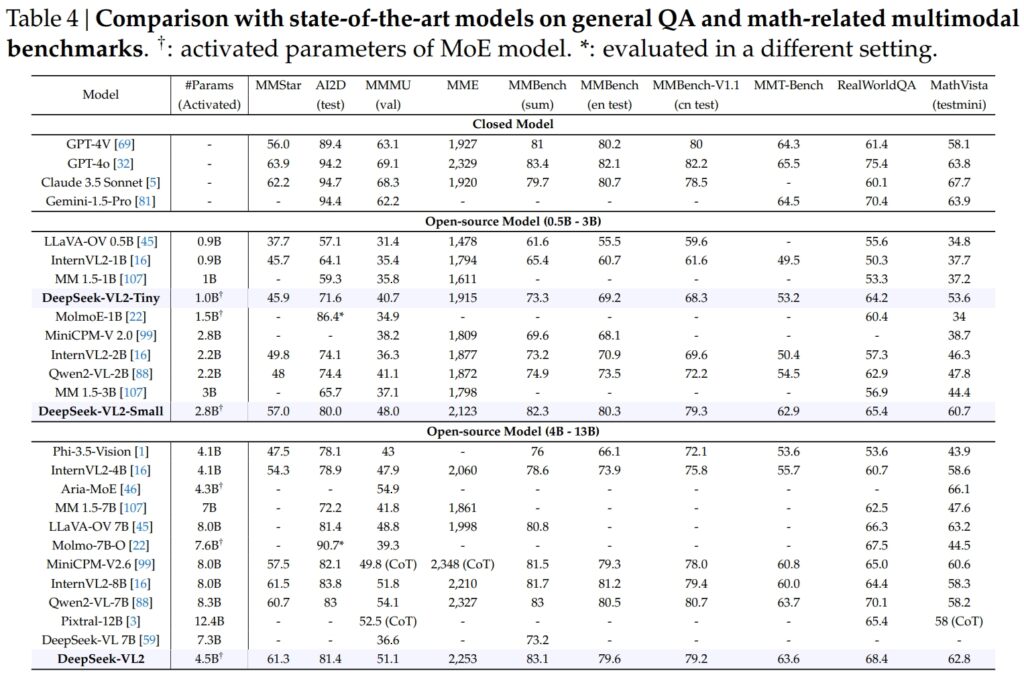
Os modelos DeepSeek-VL2, incluindo as variantes Tiny, Small e Standard, se destacaram em benchmarks críticos para respostas a perguntas gerais (QA) e tarefas multimodais relacionadas à matemática.
DeepSeek-VL2-Small, com seus 2,8 bilhões de parâmetros ativados, alcançou uma pontuação MMStar de 57,0 e superou modelos de tamanho semelhante, como InternVL2-2B (49,8) e Qwen2-VL-2B (48,0). Ele também rivalizou de perto com modelos muito maiores, como o 4.1B InternVL2-4B (54,3) e o 8,3B Qwen2-VL-7B (60,7), demonstrando sua eficiência competitiva.
No teste AI2D para visual raciocínio, DeepSeek-VL2-Small alcançou uma pontuação de 80,0, superando InternVL2-2B (74,1) e MM 1,5-3B (não relatado). Mesmo contra concorrentes de maior escala como InternVL2-4B (78,9) e MiniCPM-V2.6 (82,1), o DeepSeek-VL2 demonstrou bons resultados com menos parâmetros ativados.
 Fonte: DeepSeek
Fonte: DeepSeek
O carro-chefe O modelo DeepSeek-VL2 (4,5 bilhões de parâmetros ativados) apresentou resultados excepcionais, pontuando 61,3 no MMStar e 81,4 no AI2D. Superou concorrentes como Molmo-7B-O (parâmetros ativados de 7,6B, 39,3) e MiniCPM-V2.6 (8,0B, 57,5), validando ainda mais sua superioridade técnica.
Excelência em OCR-Benchmarks relacionados
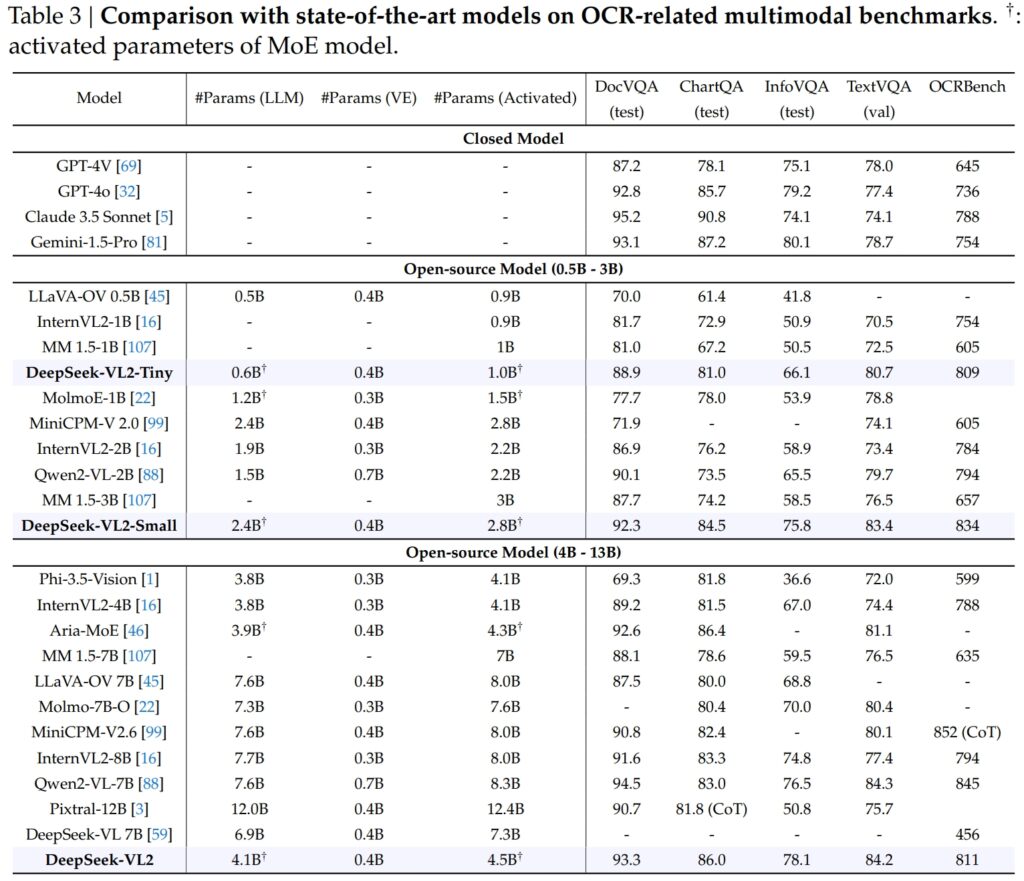
Os recursos do DeepSeek-VL2 se estendem com destaque aos relacionados ao OCR (reconhecimento óptico de caracteres). tarefas, uma área crucial para compreensão de documentos e extração de texto em IA. No teste DocVQA, o DeepSeek-VL2-Small alcançou uma precisão impressionante de 92,3%, superando todos os outros modelos de código aberto de escala semelhante, incluindo InternVL2-4B (89,2%) e MiniCPM-V2.6 (90,8%). Sua precisão ficou logo atrás de modelos fechados como GPT-4o (92,8) e Claude 3.5 Sonnet (95,2).
O modelo DeepSeek-VL2 também liderou no teste ChartQA com uma pontuação de 86,0, superando o InternVL2-4B (81,5) e MiniCPM-V2.6 (82,4). Este resultado reflete a capacidade avançada do DeepSeek-VL2 de processar gráficos e extrair insights de dados visuais complexos.
 Fonte: DeepSeek
Fonte: DeepSeek
No OCRBench, um mercado altamente competitivo métrica para reconhecimento de texto refinado, DeepSeek-VL2 alcançou 811, superando 7,6B Qwen2-VL-7B (845) e MiniCPM-V2.6 (852 com CoT), e destacando sua força em tarefas densas de OCR.
Comparação com os principais modelos de linguagem de visão
Quando colocados ao lado de líderes do setor como o GPT-4V da OpenAI e o Gemini-1.5-Pro do Google, os modelos DeepSeek-VL2 oferecem um equilíbrio atraente entre desempenho e eficiência. Por exemplo, GPT-4V obteve pontuação de 87,2 no DocVQA, que está apenas marginalmente à frente do DeepSeek-VL2 (93,3), apesar deste último operar sob uma estrutura de código aberto com menos parâmetros ativados.
No TextVQA, DeepSeek-VL2-Small alcançou 83,4, superando significativamente modelos de código aberto semelhantes como InternVL2-2B (73,4) e MiniCPM-V2.0 (74,1). Mesmo o muito maior MiniCPM-V2.6 (8,0B) atingiu apenas 80,4, ressaltando ainda mais a escalabilidade e a eficiência da arquitetura do DeepSeek-VL2.
Para ChartQA, a pontuação de 86,0 do DeepSeek-VL2 excedeu a do Pixtral-12B (81,8) e InternVL2-8B (83,3), demonstrando sua capacidade de se destacar em tarefas especializadas que exigem compreensão visual-textual.
Relacionado: Mistral AI lança Pixtral 12B para processamento de texto e imagem
Expandindo aplicações: de conversas fundamentadas a narrativas visuais
Um recurso notável dos modelos DeepSeek-VL2 é a capacidade de conduzir conversas fundamentadas, onde o modelo pode identificar objetos em imagens e integrá-los em discussões contextuais.
Por exemplo, ao usar um token especializado, o modelo pode fornecer detalhes específicos do objeto, como localização e descrição, para responder a consultas sobre imagens. Isto abre possibilidades para aplicações em robótica, realidade aumentada e assistentes digitais, onde é necessário um raciocínio visual preciso.
Outra área de aplicação é a narrativa visual. DeepSeek-VL2 pode gerar narrativas coerentes baseadas em uma sequência de imagens, combinando seu reconhecimento visual avançado e capacidades de linguagem.
Isso é especialmente valioso em áreas como educação, mídia e entretenimento, onde a criação de conteúdo dinâmico é uma prioridade. Os modelos aproveitam uma forte compreensão multimodal para criar histórias detalhadas e contextualmente apropriadas, integrando elementos visuais como pontos de referência e texto na narrativa de forma integrada.
A capacidade dos modelos em fundamentação visual é igualmente forte. Em testes envolvendo imagens complexas, o DeepSeek-VL2 demonstrou a capacidade de localizar e descrever objetos com precisão com base em instruções descritivas.
Por exemplo, quando solicitado a identificar um “carro estacionado no lado esquerdo da rua”, o modelo pode identificar o objeto exato na imagem e gerar coordenadas de caixa delimitadora para ilustrar sua resposta. Esses recursos fazem com que é altamente aplicável para sistemas autônomos e vigilância, onde a análise visual detalhada é crítica.
Acessibilidade e escalabilidade de código aberto
A decisão da DeepSeek AI de lançar o DeepSeek-VL2 como um o código aberto contrasta fortemente com a natureza proprietária de concorrentes como o GPT-4V da OpenAI e o Gemini-Exp do Google, que são sistemas fechados projetados para acesso público limitado.
De acordo com a documentação técnica, “Ao fazer nosso pré Com modelos treinados e códigos disponíveis publicamente, pretendemos acelerar o progresso na modelagem de linguagem de visão e promover a inovação colaborativa em toda a comunidade de pesquisa.”
A escalabilidade do DeepSeek-VL2 aumenta ainda mais seu apelo. Os modelos são otimizados para implantação em uma ampla variedade de configurações de hardware, desde GPUs únicas com 10 GB de memória até configurações multi-GPU capazes de lidar com cargas de trabalho em grande escala.
Essa flexibilidade garante que o DeepSeek-VL2 possa ser usado por organizações de todos os tamanhos, desde startups até grandes empresas, sem a necessidade de infraestrutura especializada.
Inovações em dados e Treinamento
Um fator importante por trás do sucesso do DeepSeek-VL2 são seus extensos e diversificados dados de treinamento. A fase de pré-treinamento incorporou conjuntos de dados como WIT, WikiHow e OBELICS, que forneceram uma mistura de pares imagem-texto intercalados para generalização.
Dados adicionais para tarefas específicas, como OCR e respostas visuais a perguntas, vieram de fontes como LaTeX OCR e PubTabNet, garantindo que os modelos pudessem lidar com tarefas gerais e especializadas com alta precisão.
A inclusão de conjuntos de dados multilíngues também reflete o objetivo da DeepSeek AI de aplicabilidade global. Conjuntos de dados em chinês, como Wanjuan, foram integrados juntamente com conjuntos de dados em inglês para garantir que os modelos pudessem operar de forma eficaz em ambientes multilíngues.
Essa abordagem melhora a usabilidade do DeepSeek-VL2 em regiões onde predominam dados em idiomas diferentes do inglês, expandindo significativamente sua base de usuários potenciais.
A fase supervisionada de ajuste fino refinou ainda mais os modelos. recursos, concentrando-se em tarefas específicas, como compreensão de GUI e análise de gráficos. Ao combinar conjuntos de dados internos com recursos de código aberto de alta qualidade, o DeepSeek-VL2 alcançou desempenho de última geração em vários benchmarks, validando a eficácia de sua metodologia de treinamento.
Cuidado cuidadoso do DeepSeek AI de dados e um pipeline de treinamento inovador permitiram que os modelos VL2 se destacassem em uma ampla gama de tarefas, mantendo a eficiência e a escalabilidade. Esses fatores os tornam uma adição valiosa ao campo da IA multimodal.
A capacidade dos modelos de lidar com tarefas complexas de processamento de imagens, como aterramento visual e OCR denso, os torna ideais para setores como logística e segurança. Na logística, eles podem automatizar o rastreamento de estoque analisando imagens de estoque em depósito, identificando itens e integrando descobertas em sistemas de gerenciamento de estoque.
No domínio da segurança, o DeepSeek-VL2 pode auxiliar na vigilância, identificando objetos ou indivíduos em tempo real, com base em consultas descritivas, e fornecendo informações contextuais detalhadas aos operadores.
DeepSeek-A capacidade de conversação fundamentada do VL2 também oferece possibilidades em robótica e realidade aumentada. Por exemplo, um robô equipado com este modelo poderia interpretar visualmente o seu ambiente, responder a perguntas humanas sobre objetos específicos e executar ações com base na sua compreensão da entrada visual.
Da mesma forma, os dispositivos de realidade aumentada podem aproveitar a base visual do modelo e os recursos de narrativa para fornecer experiências interativas e imersivas, como visitas guiadas ou sobreposições contextuais em ambientes em tempo real.
Desafios e perspectivas futuras
Apesar de seus inúmeros pontos fortes, o DeepSeek-VL2 enfrenta vários desafios. Uma limitação importante é o tamanho de sua janela de contexto, que atualmente restringe o número de imagens que podem ser processadas em uma única interação.
Expandir essa janela de contexto em iterações futuras permitiria interações mais ricas e com múltiplas imagens e aumentaria a utilidade do modelo em tarefas que exigem uma compreensão contextual mais ampla.
Outro desafio reside em lidar com situações fora de contexto. domínio ou entradas visuais de baixa qualidade, como imagens borradas ou objetos não presentes em seus dados de treinamento. Embora o DeepSeek-VL2 tenha demonstrado notáveis capacidades de generalização, melhorar a robustez contra tais entradas aumentará ainda mais a sua aplicabilidade em cenários do mundo real.
Olhando para o futuro, a DeepSeek AI planeja fortalecer as capacidades de raciocínio de seus modelos, permitindo-lhes lidar com tarefas multimodais cada vez mais complexas. Ao integrar pipelines de treinamento aprimorados e expandir conjuntos de dados para cobrir cenários mais diversos, versões futuras do DeepSeek-VL2 poderão estabelecer novos padrões de referência para o desempenho da IA da linguagem de visão.

